 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Constituent Headedness
Mar 16, 2026Headedness is widely used as an organizing device in syntactic analysis, yet constituency treebanks rarely encode it explicitly and most processing pipelines recover it procedurally via percolation rules. We treat this notion of constituent headedness as an explicit representational layer and learn it as a supervised prediction task over aligned constituency and dependency annotations, inducing supervision by defining each constituent head as the dependency span head. On aligned English and Chinese data, the resulting models achieve near-ceiling intrinsic accuracy and substantially outperform Collins-style rule-based percolation. Predicted heads yield comparable parsing accuracy under head-driven binarization, consistent with the induced binary training targets being largely equivalent across head choices, while increasing the fidelity of deterministic constituency-to-dependency conversion and transferring across resources and languages under simple label-mapping interfaces.
Parsing Through Boundaries in Chinese Word Segmentation
Mar 29, 2025

Chinese word segmentation is a foundational task in natural language processing (NLP), with far-reaching effects on syntactic analysis. Unlike alphabetic languages like English, Chinese lacks explicit word boundaries, making segmentation both necessary and inherently ambiguous. This study highlights the intricate relationship between word segmentation and syntactic parsing, providing a clearer understanding of how different segmentation strategies shape dependency structures in Chinese. Focusing on the Chinese GSD treebank, we analyze multiple word boundary schemes, each reflecting distinct linguistic and computational assumptions, and examine how they influence the resulting syntactic structures. To support detailed comparison, we introduce an interactive web-based visualization tool that displays parsing outcomes across segmentation methods.
Enhancing Korean Dependency Parsing with Morphosyntactic Features
Mar 26, 2025This paper introduces UniDive for Korean, an integrated framework that bridges Universal Dependencies (UD) and Universal Morphology (UniMorph) to enhance the representation and processing of Korean {morphosyntax}. Korean's rich inflectional morphology and flexible word order pose challenges for existing frameworks, which often treat morphology and syntax separately, leading to inconsistencies in linguistic analysis. UniDive unifies syntactic and morphological annotations by preserving syntactic dependencies while incorporating UniMorph-derived features, improving consistency in annotation. We construct an integrated dataset and apply it to dependency parsing, demonstrating that enriched morphosyntactic features enhance parsing accuracy, particularly in distinguishing grammatical relations influenced by morphology. Our experiments, conducted with both encoder-only and decoder-only models, confirm that explicit morphological information contributes to more accurate syntactic analysis.
K-UD: Revising Korean Universal Dependencies Guidelines
Dec 01, 2024

Critique has surfaced concerning the existing linguistic annotation framework for Korean Universal Dependencies (UDs), particularly in relation to syntactic relationships. In this paper, our primary objective is to refine the definition of syntactic dependency of UDs within the context of analyzing the Korean language. Our aim is not only to achieve a consensus within UDs but also to garner agreement beyond the UD framework for analyzing Korean sentences using dependency structure, by establishing a linguistic consensus model.
Unlocking Korean Verbs: A User-Friendly Exploration into the Verb Lexicon
Oct 01, 2024



The Sejong dictionary dataset offers a valuable resource, providing extensive coverage of morphology, syntax, and semantic representation. This dataset can be utilized to explore linguistic information in greater depth. The labeled linguistic structures within this dataset form the basis for uncovering relationships between words and phrases and their associations with target verbs. This paper introduces a user-friendly web interface designed for the collection and consolidation of verb-related information, with a particular focus on subcategorization frames. Additionally, it outlines our efforts in mapping this information by aligning subcategorization frames with corresponding illustrative sentence examples. Furthermore, we provide a Python library that would simplify syntactic parsing and semantic role labeling. These tools are intended to assist individuals interested in harnessing the Sejong dictionary dataset to develop applications for Korean language processing.
Plasticine3D: Non-rigid 3D editting with text guidance
Dec 15, 2023

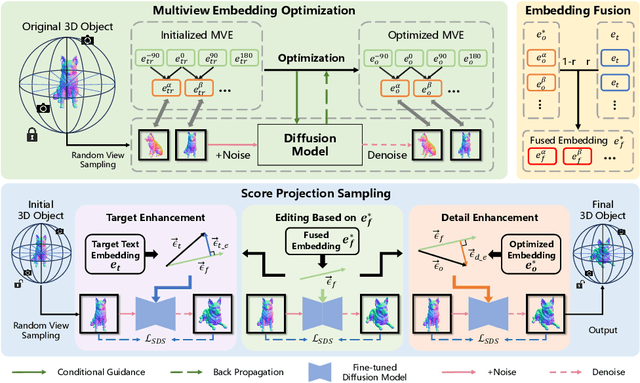

With the help of Score Distillation Sampling(SDS) and the rapid development of various trainable 3D representations, Text-to-Image(T2I) diffusion models have been applied to 3D generation tasks and achieved considerable results. There are also some attempts toward the task of editing 3D objects leveraging this Text-to-3D pipeline. However, most methods currently focus on adding additional geometries, overwriting textures or both. But few of them can perform non-rigid transformation of 3D objects. For those who can perform non-rigid editing, on the other hand, suffer from low-resolution, lack of fidelity and poor flexibility. In order to address these issues, we present: Plasticine3D, a general, high-fidelity, photo-realistic and controllable non-rigid editing pipeline. Firstly, our work divides the editing process into a geometry editing stage and a texture editing stage to achieve more detailed and photo-realistic results ; Secondly, in order to perform non-rigid transformation with controllable results while maintain the fidelity towards original 3D models in the same time, we propose a multi-view-embedding(MVE) optimization strategy to ensure that the diffusion model learns the overall features of the original object and an embedding-fusion(EF) to control the degree of editing by adjusting the value of the fusing rate. We also design a geometry processing step before optimizing on the base geometry to cope with different needs of various editing tasks. Further more, to fully leverage the geometric prior from the original 3D object, we provide an optional replacement of score distillation sampling named score projection sampling(SPS) which enables us to directly perform optimization from the origin 3D mesh in most common median non-rigid editing scenarios. We demonstrate the effectiveness of our method on both the non-rigid 3D editing task and general 3D editing task.
Korean Named Entity Recognition Based on Language-Specific Features
May 10, 2023In the paper, we propose a novel way of improving named entity recognition in the Korean language using its language-specific features. While the field of named entity recognition has been studied extensively in recent years, the mechanism of efficiently recognizing named entities in Korean has hardly been explored. This is because the Korean language has distinct linguistic properties that prevent models from achieving their best performances. Therefore, an annotation scheme for {Korean corpora} by adopting the CoNLL-U format, which decomposes Korean words into morphemes and reduces the ambiguity of named entities in the original segmentation that may contain functional morphemes such as postpositions and particles, is proposed herein. We investigate how the named entity tags are best represented in this morpheme-based scheme and implement an algorithm to convert word-based {and syllable-based Korean corpora} with named entities into the proposed morpheme-based format. Analyses of the results of {statistical and neural} models reveal that the proposed morpheme-based format is feasible, and the {varied} performances of the models under the influence of various additional language-specific features are demonstrated. Extrinsic conditions were also considered to observe the variance of the performances of the proposed models, given different types of data, including the original segmentation and different types of tagging formats.
Contrastive Learning enhanced Author-Style Headline Generation
Nov 07, 2022



Headline generation is a task of generating an appropriate headline for a given article, which can be further used for machine-aided writing or enhancing the click-through ratio. Current works only use the article itself in the generation, but have not taken the writing style of headlines into consideration. In this paper, we propose a novel Seq2Seq model called CLH3G (Contrastive Learning enhanced Historical Headlines based Headline Generation) which can use the historical headlines of the articles that the author wrote in the past to improve the headline generation of current articles. By taking historical headlines into account, we can integrate the stylistic features of the author into our model, and generate a headline not only appropriate for the article, but also consistent with the author's style. In order to efficiently learn the stylistic features of the author, we further introduce a contrastive learning based auxiliary task for the encoder of our model. Besides, we propose two methods to use the learned stylistic features to guide both the pointer and the decoder during the generation. Experimental results show that historical headlines of the same user can improve the headline generation significantly, and both the contrastive learning module and the two style features fusion methods can further boost the performance.
Yet Another Format of Universal Dependencies for Korean
Sep 20, 2022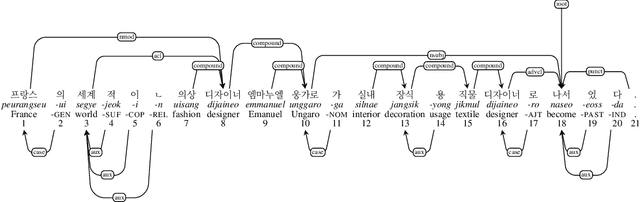

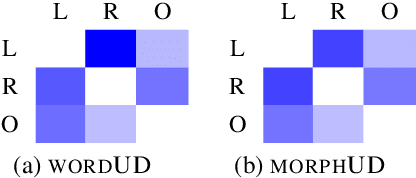
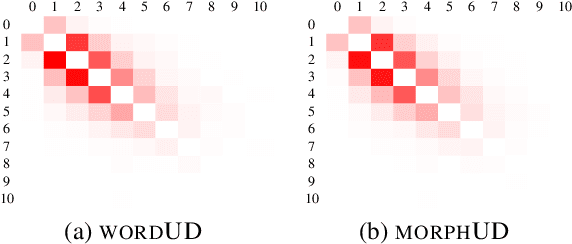
In this study, we propose a morpheme-based scheme for Korean dependency parsing and adopt the proposed scheme to Universal Dependencies. We present the linguistic rationale that illustrates the motivation and the necessity of adopting the morpheme-based format, and develop scripts that convert between the original format used by Universal Dependencies and the proposed morpheme-based format automatically. The effectiveness of the proposed format for Korean dependency parsing is then testified by both statistical and neural models, including UDPipe and Stanza, with our carefully constructed morpheme-based word embedding for Korean. morphUD outperforms parsing results for all Korean UD treebanks, and we also present detailed error analyses.