 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRI: Self-Internalizing Reinforcement Learning with Intrinsic Skills for LLM Agent Training
Jun 01, 2026Long-horizon LLM agents can benefit from reusable skills, yet existing skill-based methods often rely on external skill generators during training or persistent skill retrieval at inference, increasing engineering complexity, context length, and deployment latency. We propose Self-Internalizing Reinforcement learning with Intrinsic skills (SIRI), a three-phase framework that enables agents to discover, validate, and internalize skills without external skill generators or inference-time skill banks. SIRI first warms up the policy with GiGPO to acquire basic interaction ability and collect successful skill-free trajectories. It then performs self-skill mining, where the current policy summarizes compact skills from its own successful plain rollouts and validates them through paired skill-augmented and skill-free rollouts. Finally, SIRI distills only beneficial skill-guided action tokens into the plain policy using trajectory-level utility and action-level advantage. At inference, the agent runs with the original prompt only. On ALFWorld and WebShop with Qwen2.5-7B-Instruct, SIRI improves GiGPO from 0.908 to 0.930 on ALFWorld and from 0.728 to 0.813 on WebShop, outperforming prompt-based, RL-based, and memory-augmented baselines. Further analysis shows that our self-mining strategy can achieve performance comparable to distillation with closed-source large model. Our code is available at https://github.com/kirito618/SIRI.
DualMem: Bypassing the Objectness Bottleneck for Calibrated Unknown-Stream Filtering in Open-World Object Detection
May 22, 2026Open-world object detection (OWOD) requires detectors to localize known classes while identifying unknown objects for future incremental learning. We find that the unknown prediction streams of strong OWOD detectors are heavily polluted: on M-OWODB, across PROB, OW-DETR, and HypOW, future-task positive unknowns make up less than 10% of unknown predictions, whereas background false positives account for 46-71%. We show that this is not a missing-information problem, but an information bottleneck at the objectness head. On PROB Task 1, a linear probe on the 256-D decoder query achieves an AUROC of 0.908 for positive-versus-negative unknown discrimination, but the final one-dimensional objectness scalar drops to 0.642. A frozen SigLIP feature, without access to the detector, independently recovers much of this proposal-level separability at the filtering stage (AUROC = 0.871). Motivated by this finding, we propose DualMem, a calibrated post-hoc filter that assumes a small image-disjoint annotated calibration split of held-out future-task objects and performs a non-parametric likelihood ratio test in frozen SigLIP feature space. DualMem uses a k-nearest-neighbor positive memory to protect future-task objects and a negative memory to suppress background-like proposals. Its decision threshold is chosen by Neyman-Pearson calibration, giving users an explicit trade-off between false-unknown suppression and novel recall. Across PROB, OW-DETR, and HypOW on M-OWODB Task 1, DualMem reduces background-type false unknown proposals per image by 44.9%-66.3%, with a mean reduction of 56.6%. On PROB Task 1, it more than doubles the reduction achieved by a natural K-means prototype baseline, while leaving known-class mAP unchanged because known detections bypass the filter.
CAGE-SGG: Counterfactual Active Graph Evidence for Open-Vocabulary Scene Graph Generation
Apr 28, 2026Open-vocabulary scene graph generation (SGG) aims to describe visual scenes with flexible and fine-grained relation phrases beyond a fixed predicate vocabulary. While recent vision-language models greatly expand the semantic coverage of SGG, they also introduce a critical reliability issue: predicted relations may be driven by language priors or object co-occurrence rather than grounded visual evidence. In this paper, we propose an evidence-rounded open-vocabulary SGG framework based on counterfactual relation verification. Instead of directly accepting plausible relation proposals, our method verifies whether each candidate relation is supported by relation-pecific visual, geometric, and contextual evidence. Specifically, we first generate open-vocabulary relation candidates with a vision-language proposer, then decompose predicate phrases into soft evidence bases such as support, contact, containment, depth, motion, and state. A relation-conditioned evidence encoder extracts predicate-relevant cues, while a counterfactual verifier tests whether the relation score decreases when necessary vidence is removed and remains stable under irrelevant perturbations. We further introduce contradiction-aware predicate learning and graph-level preference optimization to improve fine-grained discrimination and global graph consistency. Experiments on conventional, open-vocabulary, and panoptic SGG benchmarks show that our method consistently improves standard recall-based metrics, unseen predicate generalization, and counterfactual grounding quality. These results demonstrate that moving from relation generation to relation verification leads to more reliable, interpretable, and evidence-grounded scene graphs.
Perturb-and-Restore: Simulation-driven Structural Augmentation Framework for Imbalance Chromosomal Anomaly Detection
Apr 01, 2026Detecting structural chromosomal abnormalities is crucial for accurate diagnosis and management of genetic disorders. However, collecting sufficient structural abnormality data is extremely challenging and costly in clinical practice, and not all abnormal types can be readily collected. As a result, deep learning approaches face significant performance degradation due to the severe imbalance and scarcity of abnormal chromosome data. To address this challenge, we propose a Perturb-and-Restore (P&R), a simulation-driven structural augmentation framework that effectively alleviates data imbalance in chromosome anomaly detection. The P&R framework comprises two key components: (1) Structure Perturbation and Restoration Simulation, which generates synthetic abnormal chromosomes by perturbing chromosomal banding patterns of normal chromosomes followed by a restoration diffusion network that reconstructs continuous chromosome content and edges, thus eliminating reliance on rare abnormal samples; and (2) Energy-guided Adaptive Sampling, an energy score-based online selection strategy that dynamically prioritizes high-quality synthetic samples by referencing the energy distribution of real samples. To evaluate our method, we construct a comprehensive structural anomaly dataset consisting of over 260,000 chromosome images, including 4,242 abnormal samples spanning 24 categories. Experimental results demonstrate that the P&R framework achieves state-of-the-art (SOTA) performance, surpassing existing methods with an average improvement of 8.92% in sensitivity, 8.89% in precision, and 13.79% in F1-score across all categories.
Factorized Neural Implicit DMD for Parametric Dynamics
Mar 11, 2026A data-driven, model-free approach to modeling the temporal evolution of physical systems mitigates the need for explicit knowledge of the governing equations. Even when physical priors such as partial differential equations are available, such systems often reside in high-dimensional state spaces and exhibit nonlinear dynamics, making traditional numerical solvers computationally expensive and ill-suited for real-time analysis and control. Consider the problem of learning a parametric flow of a dynamical system: with an initial field and a set of physical parameters, we aim to predict the system's evolution over time in a way that supports long-horizon rollouts, generalization to unseen parameters, and spectral analysis. We propose a physics-coded neural field parameterization of the Koopman operator's spectral decomposition. Unlike a physics-constrained neural field, which fits a single solution surface, and neural operators, which directly approximate the solution operator at fixed time horizons, our model learns a factorized flow operator that decouples spatial modes and temporal evolution. This structure exposes underlying eigenvalues, modes, and stability of the underlying physical process to enable stable long-term rollouts, interpolation across parameter spaces, and spectral analysis. We demonstrate the efficacy of our method on a range of dynamics problems, showcasing its ability to accurately predict complex spatiotemporal phenomena while providing insights into the system's dynamic behavior.
Not All Candidates are Created Equal: A Heterogeneity-Aware Approach to Pre-ranking in Recommender Systems
Mar 04, 2026Most large-scale recommender systems follow a multi-stage cascade of retrieval, pre-ranking, ranking, and re-ranking. A key challenge at the pre-ranking stage arises from the heterogeneity of training instances sampled from coarse-grained retrieval results, fine-grained ranking signals, and exposure feedback. Our analysis reveals that prevailing pre-ranking methods, which indiscriminately mix heterogeneous samples, suffer from gradient conflicts: hard samples dominate training while easy ones remain underutilized, leading to suboptimal performance. We further show that the common practice of uniformly scaling model complexity across all samples is inefficient, as it overspends computation on easy cases and slows training without proportional gains. To address these limitations, this paper presents Heterogeneity-Aware Adaptive Pre-ranking (HAP), a unified framework that mitigates gradient conflicts through conflict-sensitive sampling coupled with tailored loss design, while adaptively allocating computational budgets across candidates. Specifically, HAP disentangles easy and hard samples, directing each subset along dedicated optimization paths. Building on this separation, it first applies lightweight models to all candidates for efficient coverage, and further engages stronger models on the hard ones, maintaining accuracy while reducing cost. This approach not only improves pre-ranking effectiveness but also provides a practical perspective on scaling strategies in industrial recommender systems. HAP has been deployed in the Toutiao production system for 9 months, yielding up to 0.4% improvement in user app usage duration and 0.05% in active days, without additional computational cost. We also release a large-scale industrial hybrid-sample dataset to enable the systematic study of source-driven candidate heterogeneity in pre-ranking.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Seeing through the Conflict: Transparent Knowledge Conflict Handling in Retrieval-Augmented Generation
Jan 11, 2026Large language models (LLMs) equipped with retrieval--the Retrieval-Augmented Generation (RAG) paradigm--should combine their parametric knowledge with external evidence, yet in practice they often hallucinate, over-trust noisy snippets, or ignore vital context. We introduce TCR (Transparent Conflict Resolution), a plug-and-play framework that makes this decision process observable and controllable. TCR (i) disentangles semantic match and factual consistency via dual contrastive encoders, (ii) estimates self-answerability to gauge confidence in internal memory, and (iii) feeds the three scalar signals to the generator through a lightweight soft-prompt with SNR-based weighting. Across seven benchmarks TCR improves conflict detection (+5-18 F1), raises knowledge-gap recovery by +21.4 pp and cuts misleading-context overrides by -29.3 pp, while adding only 0.3% parameters. The signals align with human judgements and expose temporal decision patterns.
Aligning by Misaligning: Boundary-aware Curriculum Learning for Multimodal Alignment
Nov 11, 2025Most multimodal models treat every negative pair alike, ignoring the ambiguous negatives that differ from the positive by only a small detail. We propose Boundary-Aware Curriculum with Local Attention (BACL), a lightweight add-on that turns these borderline cases into a curriculum signal. A Boundary-aware Negative Sampler gradually raises difficulty, while a Contrastive Local Attention loss highlights where the mismatch occurs. The two modules are fully differentiable and work with any off-the-shelf dual encoder. Theory predicts a fast O(1/n) error rate; practice shows up to +32% R@1 over CLIP and new SOTA on four large-scale benchmarks, all without extra labels.
Synergy over Discrepancy: A Partition-Based Approach to Multi-Domain LLM Fine-Tuning
Nov 11, 2025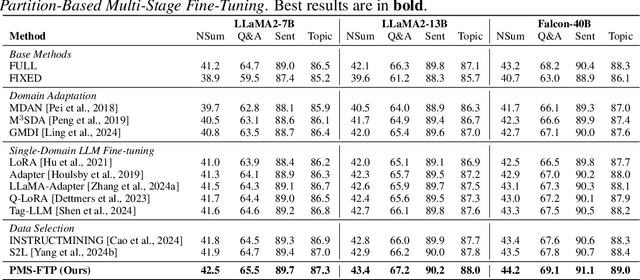
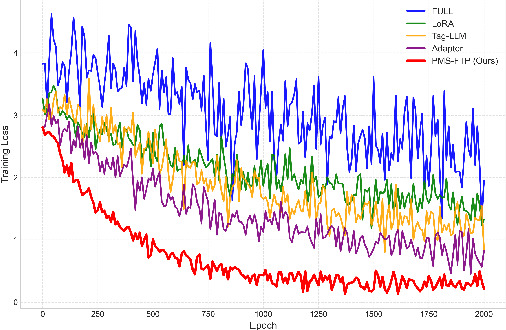
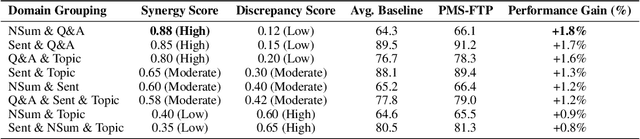
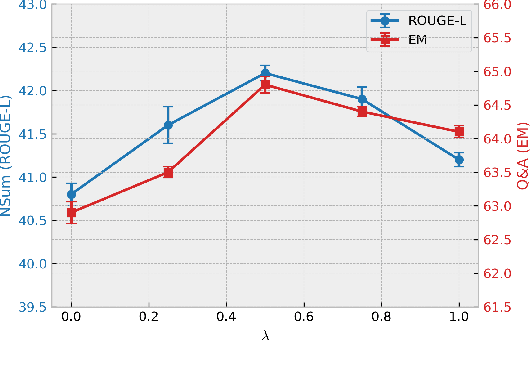
Large language models (LLMs) demonstrate impressive generalization abilities, yet adapting them effectively across multiple heterogeneous domains remains challenging due to inter-domain interference. To overcome this challenge, we propose a partition-based multi-stage fine-tuning framework designed to exploit inter-domain synergies while minimizing negative transfer. Our approach strategically partitions domains into subsets (stages) by balancing domain discrepancy, synergy, and model capacity constraints. We theoretically analyze the proposed framework and derive novel generalization bounds that justify our partitioning strategy. Extensive empirical evaluations on various language understanding tasks show that our method consistently outperforms state-of-the-art baselines.