 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTBAS: Defending LLM Agents Against Prompt Injection and Privacy Leakage
Feb 13, 2025Tool-Based Agent Systems (TBAS) allow Language Models (LMs) to use external tools for tasks beyond their standalone capabilities, such as searching websites, booking flights, or making financial transactions. However, these tools greatly increase the risks of prompt injection attacks, where malicious content hijacks the LM agent to leak confidential data or trigger harmful actions. Existing defenses (OpenAI GPTs) require user confirmation before every tool call, placing onerous burdens on users. We introduce Robust TBAS (RTBAS), which automatically detects and executes tool calls that preserve integrity and confidentiality, requiring user confirmation only when these safeguards cannot be ensured. RTBAS adapts Information Flow Control to the unique challenges presented by TBAS. We present two novel dependency screeners, using LM-as-a-judge and attention-based saliency, to overcome these challenges. Experimental results on the AgentDojo Prompt Injection benchmark show RTBAS prevents all targeted attacks with only a 2% loss of task utility when under attack, and further tests confirm its ability to obtain near-oracle performance on detecting both subtle and direct privacy leaks.
Sparse Matrix in Large Language Model Fine-tuning
May 30, 2024LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023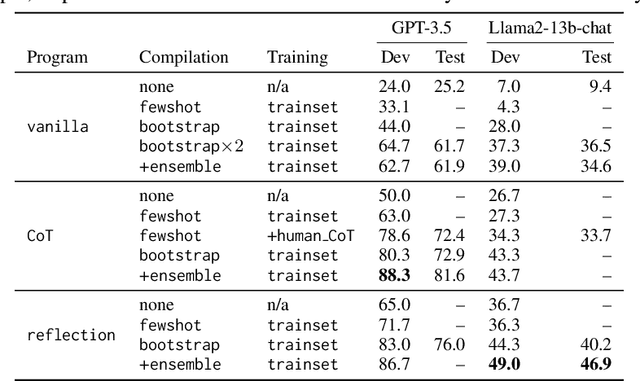

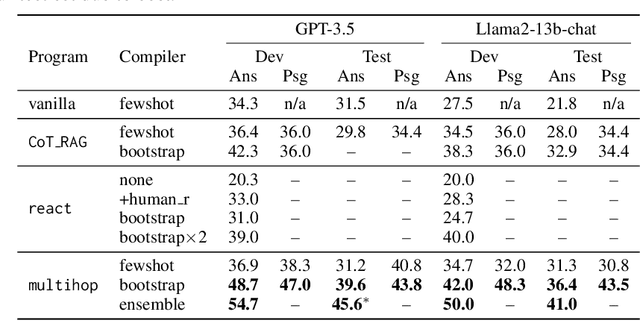

The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy