 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is MoE: Trimming Experts in Domain-Specialist Language Models
Jun 04, 2026Mixture-of-Experts (MoE) models achieve strong performance through conditional computation, but their large parameter footprint poses deployment challenges. Prior MoE compression approaches catastrophically fail when evaluated on general-purpose benchmarks beyond commonsense reasoning. We trace this failure to the granularity of compression: important capabilities are distributed across experts but concentrated in FFN sparse intermediate dimensions. To identify these dimensions, we use Fisher importance which outperforms activation-, router-score-, and magnitude-based alternatives, and identifies tiny sets of task-critical dimensions: in Qwen1.5-MoE, removing as few as 12 of 1.35M routed-FFN intermediate dimensions collapses GSM8K accuracy while largely preserving factual-knowledge performance. Building on this, we propose Fisher-MoE, which operates within FFN to remove intermediate dimensions ranked by Fisher importance. At the same 50% MoE compression ratio, Fisher-MoE preserves model capability, while reducing weight memory by ~45% and improving inference throughput by 21%. These findings suggest intermediate dimension granularity is an effective unit for both compression and ranking where capability concentrates in MoE models.
Preserving Long-Tailed Expert Information in Mixture-of-Experts Tuning
Apr 24, 2026Despite MoE models leading many benchmarks, supervised fine-tuning (SFT) for the MoE architectures remains difficult because its router layers are fragile. Methods such as DenseMixer and ESFT mitigate router collapse with dense mixing or auxiliary load-balancing losses, but these introduce noisy gradients that often degrade performance. In preliminary experiments, we systematically pruned experts and observed that while certain super experts are activated far more frequently, discarding less used experts still leads to notable performance degradation. This suggests that even rarely activated experts encode non-trivial knowledge useful for downstream tasks. Motivated by this, we propose an auxiliary-loss-free MoE SFT framework that combines bias-driven sparsification with always-active gated condenser experts. Rather than enforcing balanced activation across all experts, our method encourages task-relevant experts to remain active while pushing long-tailed experts toward inactivity. The condenser experts provide a persistent, learnable pathway that alleviates gradient starvation and facilitates consolidation of information that would otherwise remain fragmented across sparsely activated experts. Analysis further suggest that this design better preserves long-tailed expert information under sparse routing. Experiments on large-scale MoE models demonstrate that our approach outperforms state-of-the-art SFT baselines such as DenseMixer and ESFT, achieving average gain of 2.5%+ on both mathematical reasoning and commonsenseQA benchmarks.
RAST-MoE-RL: A Regime-Aware Spatio-Temporal MoE Framework for Deep Reinforcement Learning in Ride-Hailing
Dec 13, 2025Ride-hailing platforms face the challenge of balancing passenger waiting times with overall system efficiency under highly uncertain supply-demand conditions. Adaptive delayed matching creates a trade-off between matching and pickup delays by deciding whether to assign drivers immediately or batch requests. Since outcomes accumulate over long horizons with stochastic dynamics, reinforcement learning (RL) is a suitable framework. However, existing approaches often oversimplify traffic dynamics or use shallow encoders that miss complex spatiotemporal patterns. We introduce the Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE), which formalizes adaptive delayed matching as a regime-aware MDP equipped with a self-attention MoE encoder. Unlike monolithic networks, our experts specialize automatically, improving representation capacity while maintaining computational efficiency. A physics-informed congestion surrogate preserves realistic density-speed feedback, enabling millions of efficient rollouts, while an adaptive reward scheme guards against pathological strategies. With only 12M parameters, our framework outperforms strong baselines. On real-world Uber trajectory data (San Francisco), it improves total reward by over 13%, reducing average matching and pickup delays by 10% and 15% respectively. It demonstrates robustness across unseen demand regimes and stable training. These findings highlight the potential of MoE-enhanced RL for large-scale decision-making with complex spatiotemporal dynamics.
Sparse Matrix in Large Language Model Fine-tuning
May 30, 2024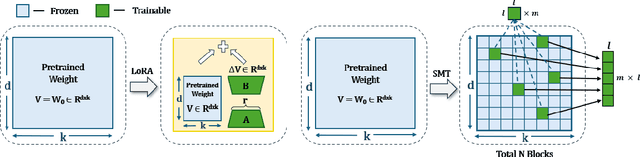



LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
Adjacent Leader Decentralized Stochastic Gradient Descent
May 18, 2024



This work focuses on the decentralized deep learning optimization framework. We propose Adjacent Leader Decentralized Gradient Descent (AL-DSGD), for improving final model performance, accelerating convergence, and reducing the communication overhead of decentralized deep learning optimizers. AL-DSGD relies on two main ideas. Firstly, to increase the influence of the strongest learners on the learning system it assigns weights to different neighbor workers according to both their performance and the degree when averaging among them, and it applies a corrective force on the workers dictated by both the currently best-performing neighbor and the neighbor with the maximal degree. Secondly, to alleviate the problem of the deterioration of the convergence speed and performance of the nodes with lower degrees, AL-DSGD relies on dynamic communication graphs, which effectively allows the workers to communicate with more nodes while keeping the degrees of the nodes low. Experiments demonstrate that AL-DSGD accelerates the convergence of the decentralized state-of-the-art techniques and improves their test performance especially in the communication constrained environments. We also theoretically prove the convergence of the proposed scheme. Finally, we release to the community a highly general and concise PyTorch-based library for distributed training of deep learning models that supports easy implementation of any distributed deep learning approach ((a)synchronous, (de)centralized).
Accelerating Parallel Stochastic Gradient Descent via Non-blocking Mini-batches
Nov 09, 2022SOTA decentralized SGD algorithms can overcome the bandwidth bottleneck at the parameter server by using communication collectives like Ring All-Reduce for synchronization. While the parameter updates in distributed SGD may happen asynchronously there is still a synchronization barrier to make sure that the local training epoch at every learner is complete before the learners can advance to the next epoch. The delays in waiting for the slowest learners(stragglers) remain to be a problem in the synchronization steps of these state-of-the-art decentralized frameworks. In this paper, we propose the (de)centralized Non-blocking SGD (Non-blocking SGD) which can address the straggler problem in a heterogeneous environment. The main idea of Non-blocking SGD is to split the original batch into mini-batches, then accumulate the gradients and update the model based on finished mini-batches. The Non-blocking idea can be implemented using decentralized algorithms including Ring All-reduce, D-PSGD, and MATCHA to solve the straggler problem. Moreover, using gradient accumulation to update the model also guarantees convergence and avoids gradient staleness. Run-time analysis with random straggler delays and computational efficiency/throughput of devices is also presented to show the advantage of Non-blocking SGD. Experiments on a suite of datasets and deep learning networks validate the theoretical analyses and demonstrate that Non-blocking SGD speeds up the training and fastens the convergence. Compared with the state-of-the-art decentralized asynchronous algorithms like D-PSGD and MACHA, Non-blocking SGD takes up to 2x fewer time to reach the same training loss in a heterogeneous environment.
RCD-SGD: Resource-Constrained Distributed SGD in Heterogeneous Environment via Submodular Partitioning
Nov 02, 2022The convergence of SGD based distributed training algorithms is tied to the data distribution across workers. Standard partitioning techniques try to achieve equal-sized partitions with per-class population distribution in proportion to the total dataset. Partitions having the same overall population size or even the same number of samples per class may still have Non-IID distribution in the feature space. In heterogeneous computing environments, when devices have different computing capabilities, even-sized partitions across devices can lead to the straggler problem in distributed SGD. We develop a framework for distributed SGD in heterogeneous environments based on a novel data partitioning algorithm involving submodular optimization. Our data partitioning algorithm explicitly accounts for resource heterogeneity across workers while achieving similar class-level feature distribution and maintaining class balance. Based on this algorithm, we develop a distributed SGD framework that can accelerate existing SOTA distributed training algorithms by up to 32%.