 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOuter-Momentum Restarting in High-Dimensional Two-Phase Optimization
May 27, 2026Communication-efficient distributed optimizers such as DiLoCo reduce synchronization costs by letting workers perform many local updates before aggregating their progress with an outer momentum optimizer. Recent theory suggests that the outer optimizer acts on an effective spectrum induced by the inner optimization loop, and that the choice of outer momentum controls how progress from local updates is accumulated across communication rounds. We study periodic restarting of the outer momentum as a simple complementary mechanism for controlling this outer memory. In a linearized squared-loss model where prediction-space residuals evolve under the empirical NTK, we derive a mode-wise restart contraction showing that resets exploit phase cancellation by discarding stale momentum while preserving inner-loop progress. Toy experiments verify the predicted contraction behavior, and language-model pretraining experiments show that periodic restarts widen the stable range of outer learning rates and momentum values across communication periods.
Worker Disagreement Reveals Sharp Directions in Local SGD
May 26, 2026Deep neural network training often exhibits highly anisotropic loss geometry, where a few sharp dominant Hessian directions coexist with a large flatter bulk. Gradients tend to align disproportionately with these dominant directions, although stable progress often requires movement through flatter bulk directions. Estimating the dominant subspace is therefore useful but costly with direct Hessian-based methods. We show that standard Local SGD exposes this geometry through worker disagreement. We theoretically show that the worker-average gap covariance is shaped by stochastic-gradient noise and Hessian curvature, causing workers to disagree along sharp, curvature-sensitive directions. Thus, worker-average gaps provide a cheap Hessian-free estimator of the dominant subspace. Experiments on MLPs, CNNs, and Transformers show that subspaces formed by worker-average gaps capture a substantial fraction of the gradient component lying in the dominant Hessian eigenspace.
Understanding Quantization of Optimizer States in LLM Pre-training: Dynamics of State Staleness and Effectiveness of State Resets
Mar 17, 2026Quantizing optimizer states is becoming an important ingredient of memory-efficient large-scale pre-training, but the resulting optimizer dynamics remain only partially understood. We study low-precision exponential moving average (EMA) optimizer states and show how quantization can cause many nominal updates to round back to the same stored value, making the state effectively stale and slowing adaptation beyond what the nominal decay would suggest. We then develop a simple predictive model of stalling that estimates one-step stalling probabilities and characterizes how stalling builds up over time after the initialization. This perspective provides a mechanistic explanation for why optimizer-state resets help in low precision: once a quantized EMA becomes effectively stale, resetting it can temporarily restore responsiveness. Motivated by this picture, we derive a simple theory-guided method for choosing useful reset periods, showing that in low precision the key question is not only whether resets help, but when they should be applied. Experiments in controlled simulations and LLM pre-training show that suitable reset schedules recover the performance lost to low-precision state storage while substantially reducing optimizer-state memory.
Zero-Shot Cross-City Generalization in End-to-End Autonomous Driving: Self-Supervised versus Supervised Representations
Mar 12, 2026End-to-end autonomous driving models are typically trained on multi-city datasets using supervised ImageNet-pretrained backbones, yet their ability to generalize to unseen cities remains largely unexamined. When training and evaluation data are geographically mixed, models may implicitly rely on city-specific cues, masking failure modes that would occur under real domain shifts when generalizing to new locations. In this work we investigate zero-shot cross-city generalization in end-to-end trajectory planning and ask whether self-supervised visual representations improve transfer across cities. We conduct a comprehensive study by integrating self-supervised backbones (I-JEPA, DINOv2, and MAE) into planning frameworks. We evaluate performance under strict geographic splits on nuScenes in the open-loop setting and on NAVSIM in the closed-loop evaluation protocol. Our experiments reveal a substantial generalization gap when transferring models relying on traditional supervised backbones across cities with different road topologies and driving conventions, particularly when transferring from right-side to left-side driving environments. Self-supervised representation learning reduces this gap. In open-loop evaluation, a supervised backbone exhibits severe inflation when transferring from Boston to Singapore (L2 displacement ratio 9.77x, collision ratio 19.43x), whereas domain-specific self-supervised pretraining reduces this to 1.20x and 0.75x respectively. In closed-loop evaluation, self-supervised pretraining improves PDMS by up to 4 percent for all single-city training cities. These results show that representation learning strongly influences the robustness of cross-city planning and establish zero-shot geographic transfer as a necessary test for evaluating end-to-end autonomous driving systems.
Self-Supervised JEPA-based World Models for LiDAR Occupancy Completion and Forecasting
Feb 13, 2026Autonomous driving, as an agent operating in the physical world, requires the fundamental capability to build \textit{world models} that capture how the environment evolves spatiotemporally in order to support long-term planning. At the same time, scalability demands learning such models in a self-supervised manner; \textit{joint-embedding predictive architecture (JEPA)} enables learning world models via leveraging large volumes of unlabeled data without relying on expensive human annotations. In this paper, we propose \textbf{AD-LiST-JEPA}, a self-supervised world model for autonomous driving that predicts future spatiotemporal evolution from LiDAR data using a JEPA framework. We evaluate the quality of the learned representations through a downstream LiDAR-based occupancy completion and forecasting (OCF) task, which jointly assesses perception and prediction. Proof of concept experiments show better OCF performance with pretrained encoder after JEPA-based world model learning.
Streamlining Industrial Contract Management with Retrieval-Augmented LLMs
Nov 18, 2025Contract management involves reviewing and negotiating provisions, individual clauses that define rights, obligations, and terms of agreement. During this process, revisions to provisions are proposed and iteratively refined, some of which may be problematic or unacceptable. Automating this workflow is challenging due to the scarcity of labeled data and the abundance of unstructured legacy contracts. In this paper, we present a modular framework designed to streamline contract management through a retrieval-augmented generation (RAG) pipeline. Our system integrates synthetic data generation, semantic clause retrieval, acceptability classification, and reward-based alignment to flag problematic revisions and generate improved alternatives. Developed and evaluated in collaboration with an industry partner, our system achieves over 80% accuracy in both identifying and optimizing problematic revisions, demonstrating strong performance under real-world, low-resource conditions and offering a practical means of accelerating contract revision workflows.
Adaptive Memory Momentum via a Model-Based Framework for Deep Learning Optimization
Oct 06, 2025The vast majority of modern deep learning models are trained with momentum-based first-order optimizers. The momentum term governs the optimizer's memory by determining how much each past gradient contributes to the current convergence direction. Fundamental momentum methods, such as Nesterov Accelerated Gradient and the Heavy Ball method, as well as more recent optimizers such as AdamW and Lion, all rely on the momentum coefficient that is customarily set to $\beta = 0.9$ and kept constant during model training, a strategy widely used by practitioners, yet suboptimal. In this paper, we introduce an \textit{adaptive memory} mechanism that replaces constant momentum with a dynamic momentum coefficient that is adjusted online during optimization. We derive our method by approximating the objective function using two planes: one derived from the gradient at the current iterate and the other obtained from the accumulated memory of the past gradients. To the best of our knowledge, such a proximal framework was never used for momentum-based optimization. Our proposed approach is novel, extremely simple to use, and does not rely on extra assumptions or hyperparameter tuning. We implement adaptive memory variants of both SGD and AdamW across a wide range of learning tasks, from simple convex problems to large-scale deep learning scenarios, demonstrating that our approach can outperform standard SGD and Adam with hand-tuned momentum coefficients. Finally, our work opens doors for new ways of inducing adaptivity in optimization.
A Survey of Optimization Methods for Training DL Models: Theoretical Perspective on Convergence and Generalization
Jan 24, 2025
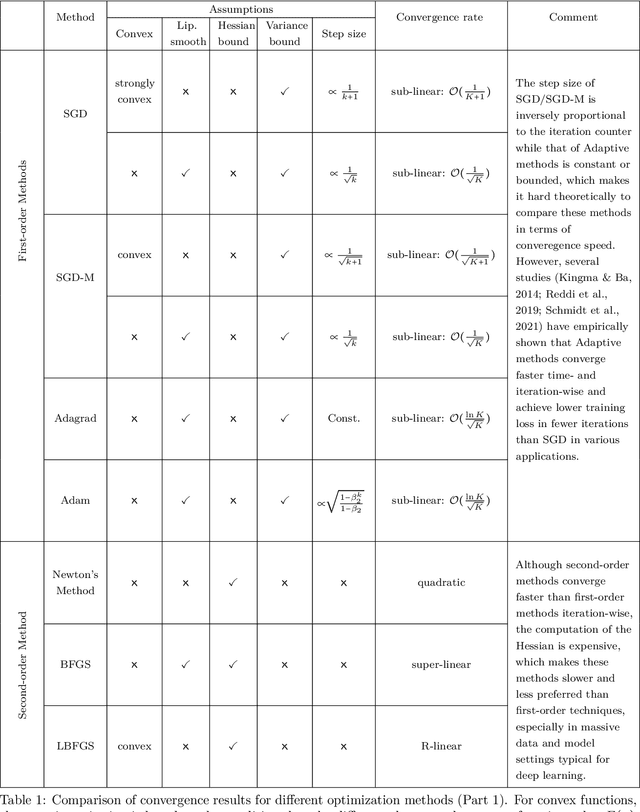


As data sets grow in size and complexity, it is becoming more difficult to pull useful features from them using hand-crafted feature extractors. For this reason, deep learning (DL) frameworks are now widely popular. The Holy Grail of DL and one of the most mysterious challenges in all of modern ML is to develop a fundamental understanding of DL optimization and generalization. While numerous optimization techniques have been introduced in the literature to navigate the exploration of the highly non-convex DL optimization landscape, many survey papers reviewing them primarily focus on summarizing these methodologies, often overlooking the critical theoretical analyses of these methods. In this paper, we provide an extensive summary of the theoretical foundations of optimization methods in DL, including presenting various methodologies, their convergence analyses, and generalization abilities. This paper not only includes theoretical analysis of popular generic gradient-based first-order and second-order methods, but it also covers the analysis of the optimization techniques adapting to the properties of the DL loss landscape and explicitly encouraging the discovery of well-generalizing optimal points. Additionally, we extend our discussion to distributed optimization methods that facilitate parallel computations, including both centralized and decentralized approaches. We provide both convex and non-convex analysis for the optimization algorithms considered in this survey paper. Finally, this paper aims to serve as a comprehensive theoretical handbook on optimization methods for DL, offering insights and understanding to both novice and seasoned researchers in the field.
AD-L-JEPA: Self-Supervised Spatial World Models with Joint Embedding Predictive Architecture for Autonomous Driving with LiDAR Data
Jan 09, 2025



As opposed to human drivers, current autonomous driving systems still require vast amounts of labeled data to train. Recently, world models have been proposed to simultaneously enhance autonomous driving capabilities by improving the way these systems understand complex real-world environments and reduce their data demands via self-supervised pre-training. In this paper, we present AD-L-JEPA (aka Autonomous Driving with LiDAR data via a Joint Embedding Predictive Architecture), a novel self-supervised pre-training framework for autonomous driving with LiDAR data that, as opposed to existing methods, is neither generative nor contrastive. Our method learns spatial world models with a joint embedding predictive architecture. Instead of explicitly generating masked unknown regions, our self-supervised world models predict Bird's Eye View (BEV) embeddings to represent the diverse nature of autonomous driving scenes. Our approach furthermore eliminates the need to manually create positive and negative pairs, as is the case in contrastive learning. AD-L-JEPA leads to simpler implementation and enhanced learned representations. We qualitatively and quantitatively demonstrate high-quality of embeddings learned with AD-L-JEPA. We furthermore evaluate the accuracy and label efficiency of AD-L-JEPA on popular downstream tasks such as LiDAR 3D object detection and associated transfer learning. Our experimental evaluation demonstrates that AD-L-JEPA is a plausible approach for self-supervised pre-training in autonomous driving applications and is the best available approach outperforming SOTA, including most recently proposed Occupancy-MAE [1] and ALSO [2]. The source code of AD-L-JEPA is available at https://github.com/HaoranZhuExplorer/AD-L-JEPA-Release.
Adjacent Leader Decentralized Stochastic Gradient Descent
May 18, 2024



This work focuses on the decentralized deep learning optimization framework. We propose Adjacent Leader Decentralized Gradient Descent (AL-DSGD), for improving final model performance, accelerating convergence, and reducing the communication overhead of decentralized deep learning optimizers. AL-DSGD relies on two main ideas. Firstly, to increase the influence of the strongest learners on the learning system it assigns weights to different neighbor workers according to both their performance and the degree when averaging among them, and it applies a corrective force on the workers dictated by both the currently best-performing neighbor and the neighbor with the maximal degree. Secondly, to alleviate the problem of the deterioration of the convergence speed and performance of the nodes with lower degrees, AL-DSGD relies on dynamic communication graphs, which effectively allows the workers to communicate with more nodes while keeping the degrees of the nodes low. Experiments demonstrate that AL-DSGD accelerates the convergence of the decentralized state-of-the-art techniques and improves their test performance especially in the communication constrained environments. We also theoretically prove the convergence of the proposed scheme. Finally, we release to the community a highly general and concise PyTorch-based library for distributed training of deep learning models that supports easy implementation of any distributed deep learning approach ((a)synchronous, (de)centralized).