 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
$P^2$GNN: Two Prototype Sets to boost GNN Performance
Mar 10, 2026Message Passing Graph Neural Networks (MP-GNNs) have garnered attention for addressing various industry challenges, such as user recommendation and fraud detection. However, they face two major hurdles: (1) heavy reliance on local context, often lacking information about the global context or graph-level features, and (2) assumption of strong homophily among connected nodes, struggling with noisy local neighborhoods. To tackle these, we introduce $P^2$GNN, a plug-and-play technique leveraging prototypes to optimize message passing, enhancing the performance of the base GNN model. Our approach views the prototypes in two ways: (1) as universally accessible neighbors for all nodes, enriching global context, and (2) aligning messages to clustered prototypes, offering a denoising effect. We demonstrate the extensibility of our proposed method to all message-passing GNNs and conduct extensive experiments across 18 datasets, including proprietary e-commerce datasets and open-source datasets, on node recommendation and node classification tasks. Results show that $P^2$GNN outperforms production models in e-commerce and achieves the top average rank on open-source datasets, establishing it as a leading approach. Qualitative analysis supports the value of global context and noise mitigation in the local neighborhood in enhancing performance.
Knowledge Models for Cancer Clinical Practice Guidelines : Construction, Management and Usage in Question Answering
Jul 23, 2024An automated knowledge modeling algorithm for Cancer Clinical Practice Guidelines (CPGs) extracts the knowledge contained in the CPG documents and transforms it into a programmatically interactable, easy-to-update structured model with minimal human intervention. The existing automated algorithms have minimal scope and cannot handle the varying complexity of the knowledge content in the CPGs for different cancer types. This work proposes an improved automated knowledge modeling algorithm to create knowledge models from the National Comprehensive Cancer Network (NCCN) CPGs in Oncology for different cancer types. The proposed algorithm has been evaluated with NCCN CPGs for four different cancer types. We also proposed an algorithm to compare the knowledge models for different versions of a guideline to discover the specific changes introduced in the treatment protocol of a new version. We created a question-answering (Q&A) framework with the guideline knowledge models as the augmented knowledge base to study our ability to query the knowledge models. We compiled a set of 32 question-answer pairs derived from two reliable data sources for the treatment of Non-Small Cell Lung Cancer (NSCLC) to evaluate the Q&A framework. The framework was evaluated against the question-answer pairs from one data source, and it can generate the answers with 54.5% accuracy from the treatment algorithm and 81.8% accuracy from the discussion part of the NCCN NSCLC guideline knowledge model.
Automated Knowledge Modeling for Cancer Clinical Practice Guidelines
Jul 15, 2023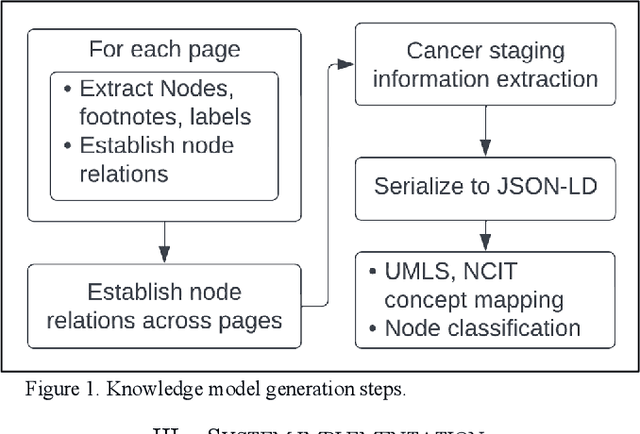
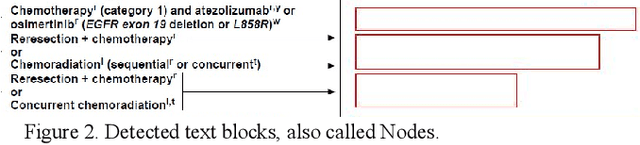
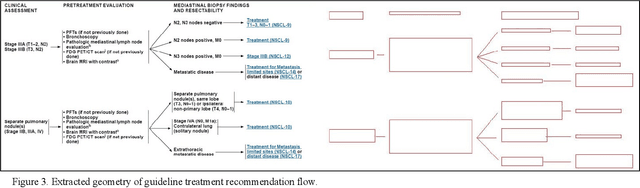

Clinical Practice Guidelines (CPGs) for cancer diseases evolve rapidly due to new evidence generated by active research. Currently, CPGs are primarily published in a document format that is ill-suited for managing this developing knowledge. A knowledge model of the guidelines document suitable for programmatic interaction is required. This work proposes an automated method for extraction of knowledge from National Comprehensive Cancer Network (NCCN) CPGs in Oncology and generating a structured model containing the retrieved knowledge. The proposed method was tested using two versions of NCCN Non-Small Cell Lung Cancer (NSCLC) CPG to demonstrate the effectiveness in faithful extraction and modeling of knowledge. Three enrichment strategies using Cancer staging information, Unified Medical Language System (UMLS) Metathesaurus & National Cancer Institute thesaurus (NCIt) concepts, and Node classification are also presented to enhance the model towards enabling programmatic traversal and querying of cancer care guidelines. The Node classification was performed using a Support Vector Machine (SVM) model, achieving a classification accuracy of 0.81 with 10-fold cross-validation.
TAME: Task Agnostic Continual Learning using Multiple Experts
Oct 08, 2022
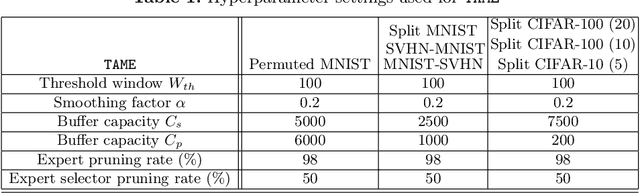

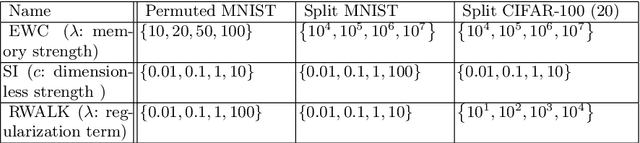
The goal of lifelong learning is to continuously learn from non-stationary distributions, where the non-stationarity is typically imposed by a sequence of distinct tasks. Prior works have mostly considered idealistic settings, where the identity of tasks is known at least at training. In this paper we focus on a fundamentally harder, so-called task-agnostic setting where the task identities are not known and the learning machine needs to infer them from the observations. Our algorithm, which we call TAME (Task-Agnostic continual learning using Multiple Experts), automatically detects the shift in data distributions and switches between task expert networks in an online manner. At training, the strategy for switching between tasks hinges on an extremely simple observation that for each new coming task there occurs a statistically-significant deviation in the value of the loss function that marks the onset of this new task. At inference, the switching between experts is governed by the selector network that forwards the test sample to its relevant expert network. The selector network is trained on a small subset of data drawn uniformly at random. We control the growth of the task expert networks as well as selector network by employing online pruning. Our experimental results show the efficacy of our approach on benchmark continual learning data sets, outperforming the previous task-agnostic methods and even the techniques that admit task identities at both training and testing, while at the same time using a comparable model size.
A Closer Look at Smoothness in Domain Adversarial Training
Jun 16, 2022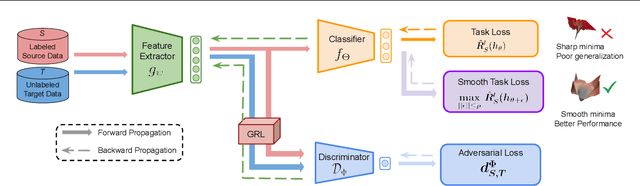
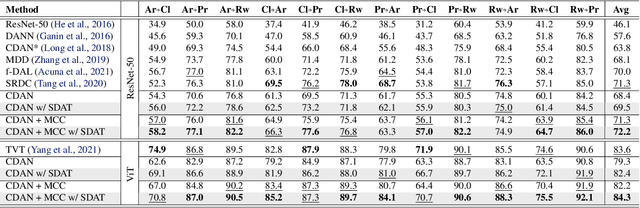
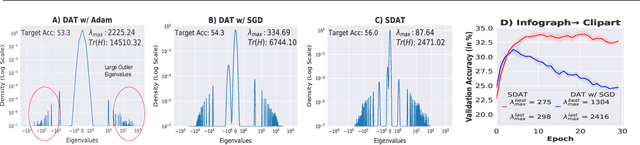
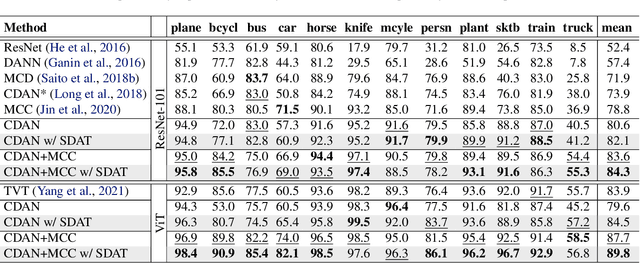
Domain adversarial training has been ubiquitous for achieving invariant representations and is used widely for various domain adaptation tasks. In recent times, methods converging to smooth optima have shown improved generalization for supervised learning tasks like classification. In this work, we analyze the effect of smoothness enhancing formulations on domain adversarial training, the objective of which is a combination of task loss (eg. classification, regression, etc.) and adversarial terms. We find that converging to a smooth minima with respect to (w.r.t.) task loss stabilizes the adversarial training leading to better performance on target domain. In contrast to task loss, our analysis shows that converging to smooth minima w.r.t. adversarial loss leads to sub-optimal generalization on the target domain. Based on the analysis, we introduce the Smooth Domain Adversarial Training (SDAT) procedure, which effectively enhances the performance of existing domain adversarial methods for both classification and object detection tasks. Our analysis also provides insight into the extensive usage of SGD over Adam in the community for domain adversarial training.
S$^3$VAADA: Submodular Subset Selection for Virtual Adversarial Active Domain Adaptation
Sep 18, 2021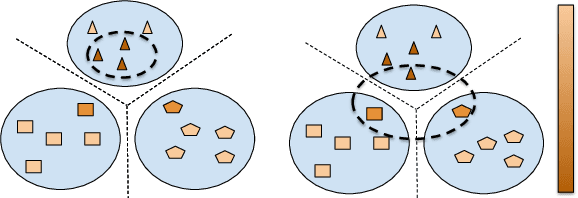
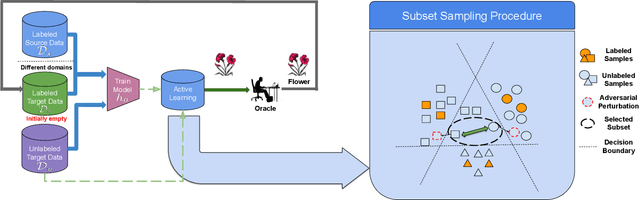

Unsupervised domain adaptation (DA) methods have focused on achieving maximal performance through aligning features from source and target domains without using labeled data in the target domain. Whereas, in the real-world scenario's it might be feasible to get labels for a small proportion of target data. In these scenarios, it is important to select maximally-informative samples to label and find an effective way to combine them with the existing knowledge from source data. Towards achieving this, we propose S$^3$VAADA which i) introduces a novel submodular criterion to select a maximally informative subset to label and ii) enhances a cluster-based DA procedure through novel improvements to effectively utilize all the available data for improving generalization on target. Our approach consistently outperforms the competing state-of-the-art approaches on datasets with varying degrees of domain shifts.
A Novel Hybrid CNN-AIS Visual Pattern Recognition Engine
Mar 11, 2015
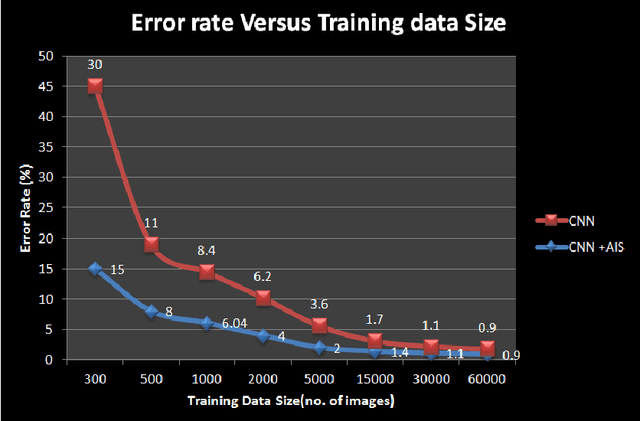
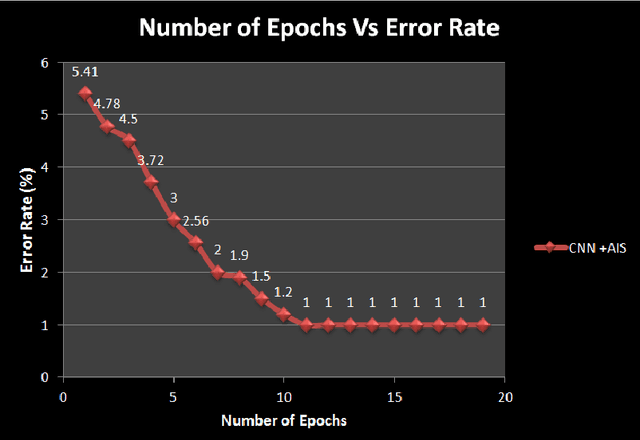
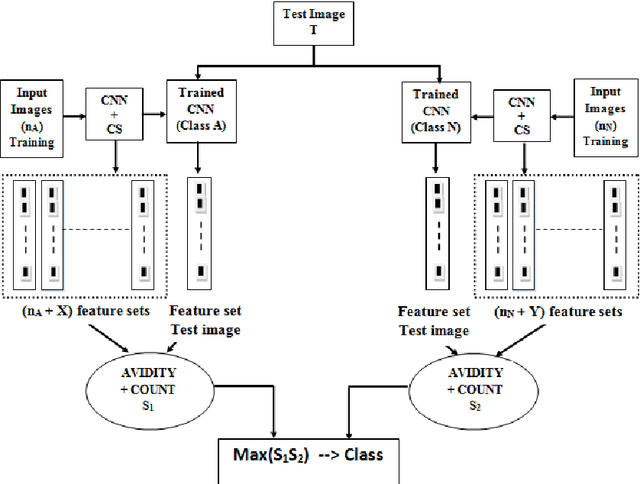
Machine learning methods are used today for most recognition problems. Convolutional Neural Networks (CNN) have time and again proved successful for many image processing tasks primarily for their architecture. In this paper we propose to apply CNN to small data sets like for example, personal albums or other similar environs where the size of training dataset is a limitation, within the framework of a proposed hybrid CNN-AIS model. We use Artificial Immune System Principles to enhance small size of training data set. A layer of Clonal Selection is added to the local filtering and max pooling of CNN Architecture. The proposed Architecture is evaluated using the standard MNIST dataset by limiting the data size and also with a small personal data sample belonging to two different classes. Experimental results show that the proposed hybrid CNN-AIS based recognition engine works well when the size of training data is limited in size