 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefProtoFL: Communication-Efficient Federated Learning via External-Referenced Prototype Alignment
Jan 21, 2026Federated learning (FL) enables collaborative model training without sharing raw data in edge environments, but is constrained by limited communication bandwidth and heterogeneous client data distributions. Prototype-based FL mitigates this issue by exchanging class-wise feature prototypes instead of full model parameters; however, existing methods still suffer from suboptimal generalization under severe communication constraints. In this paper, we propose RefProtoFL, a communication-efficient FL framework that integrates External-Referenced Prototype Alignment (ERPA) for representation consistency with Adaptive Probabilistic Update Dropping (APUD) for communication efficiency. Specifically, we decompose the model into a private backbone and a lightweight shared adapter, and restrict federated communication to the adapter parameters only. To further reduce uplink cost, APUD performs magnitude-aware Top-K sparsification, transmitting only the most significant adapter updates for server-side aggregation. To address representation inconsistency across heterogeneous clients, ERPA leverages a small server-held public dataset to construct external reference prototypes that serve as shared semantic anchors. For classes covered by public data, clients directly align local representations to public-induced prototypes, whereas for uncovered classes, alignment relies on server-aggregated global reference prototypes via weighted averaging. Extensive experiments on standard benchmarks demonstrate that RefProtoFL attains higher classification accuracy than state-of-the-art prototype-based FL baselines.
Machine Unlearning for Robust DNNs: Attribution-Guided Partitioning and Neuron Pruning in Noisy Environments
Jun 13, 2025Deep neural networks (DNNs) have achieved remarkable success across diverse domains, but their performance can be severely degraded by noisy or corrupted training data. Conventional noise mitigation methods often rely on explicit assumptions about noise distributions or require extensive retraining, which can be impractical for large-scale models. Inspired by the principles of machine unlearning, we propose a novel framework that integrates attribution-guided data partitioning, discriminative neuron pruning, and targeted fine-tuning to mitigate the impact of noisy samples. Our approach employs gradient-based attribution to probabilistically distinguish high-quality examples from potentially corrupted ones without imposing restrictive assumptions on the noise. It then applies regression-based sensitivity analysis to identify and prune neurons that are most vulnerable to noise. Finally, the resulting network is fine-tuned on the high-quality data subset to efficiently recover and enhance its generalization performance. This integrated unlearning-inspired framework provides several advantages over conventional noise-robust learning approaches. Notably, it combines data-level unlearning with model-level adaptation, thereby avoiding the need for full model retraining or explicit noise modeling. We evaluate our method on representative tasks (e.g., CIFAR-10 image classification and speech recognition) under various noise levels and observe substantial gains in both accuracy and efficiency. For example, our framework achieves approximately a 10% absolute accuracy improvement over standard retraining on CIFAR-10 with injected label noise, while reducing retraining time by up to 47% in some settings. These results demonstrate the effectiveness and scalability of the proposed approach for achieving robust generalization in noisy environments.
AD-L-JEPA: Self-Supervised Spatial World Models with Joint Embedding Predictive Architecture for Autonomous Driving with LiDAR Data
Jan 09, 2025



As opposed to human drivers, current autonomous driving systems still require vast amounts of labeled data to train. Recently, world models have been proposed to simultaneously enhance autonomous driving capabilities by improving the way these systems understand complex real-world environments and reduce their data demands via self-supervised pre-training. In this paper, we present AD-L-JEPA (aka Autonomous Driving with LiDAR data via a Joint Embedding Predictive Architecture), a novel self-supervised pre-training framework for autonomous driving with LiDAR data that, as opposed to existing methods, is neither generative nor contrastive. Our method learns spatial world models with a joint embedding predictive architecture. Instead of explicitly generating masked unknown regions, our self-supervised world models predict Bird's Eye View (BEV) embeddings to represent the diverse nature of autonomous driving scenes. Our approach furthermore eliminates the need to manually create positive and negative pairs, as is the case in contrastive learning. AD-L-JEPA leads to simpler implementation and enhanced learned representations. We qualitatively and quantitatively demonstrate high-quality of embeddings learned with AD-L-JEPA. We furthermore evaluate the accuracy and label efficiency of AD-L-JEPA on popular downstream tasks such as LiDAR 3D object detection and associated transfer learning. Our experimental evaluation demonstrates that AD-L-JEPA is a plausible approach for self-supervised pre-training in autonomous driving applications and is the best available approach outperforming SOTA, including most recently proposed Occupancy-MAE [1] and ALSO [2]. The source code of AD-L-JEPA is available at https://github.com/HaoranZhuExplorer/AD-L-JEPA-Release.
Oriented Tiny Object Detection: A Dataset, Benchmark, and Dynamic Unbiased Learning
Dec 16, 2024Detecting oriented tiny objects, which are limited in appearance information yet prevalent in real-world applications, remains an intricate and under-explored problem. To address this, we systemically introduce a new dataset, benchmark, and a dynamic coarse-to-fine learning scheme in this study. Our proposed dataset, AI-TOD-R, features the smallest object sizes among all oriented object detection datasets. Based on AI-TOD-R, we present a benchmark spanning a broad range of detection paradigms, including both fully-supervised and label-efficient approaches. Through investigation, we identify a learning bias presents across various learning pipelines: confident objects become increasingly confident, while vulnerable oriented tiny objects are further marginalized, hindering their detection performance. To mitigate this issue, we propose a Dynamic Coarse-to-Fine Learning (DCFL) scheme to achieve unbiased learning. DCFL dynamically updates prior positions to better align with the limited areas of oriented tiny objects, and it assigns samples in a way that balances both quantity and quality across different object shapes, thus mitigating biases in prior settings and sample selection. Extensive experiments across eight challenging object detection datasets demonstrate that DCFL achieves state-of-the-art accuracy, high efficiency, and remarkable versatility. The dataset, benchmark, and code are available at https://chasel-tsui.github.io/AI-TOD-R/.
Tiny Object Detection with Single Point Supervision
Dec 08, 2024



Tiny objects, with their limited spatial resolution, often resemble point-like distributions. As a result, bounding box prediction using point-level supervision emerges as a natural and cost-effective alternative to traditional box-level supervision. However, the small scale and lack of distinctive features of tiny objects make point annotations prone to noise, posing significant hurdles for model robustness. To tackle these challenges, we propose Point Teacher--the first end-to-end point-supervised method for robust tiny object detection in aerial images. To handle label noise from scale ambiguity and location shifts in point annotations, Point Teacher employs the teacher-student architecture and decouples the learning into a two-phase denoising process. In this framework, the teacher network progressively denoises the pseudo boxes derived from noisy point annotations, guiding the student network's learning. Specifically, in the first phase, random masking of image regions facilitates regression learning, enabling the teacher to transform noisy point annotations into coarse pseudo boxes. In the second phase, these coarse pseudo boxes are refined using dynamic multiple instance learning, which adaptively selects the most reliable instance from dynamically constructed proposal bags around the coarse pseudo boxes. Extensive experiments on three tiny object datasets (i.e., AI-TOD-v2, SODA-A, and TinyPerson) validate the proposed method's effectiveness and robustness against point location shifts. Notably, relying solely on point supervision, our Point Teacher already shows comparable performance with box-supervised learning methods. Codes and models will be made publicly available.
AuditWen:An Open-Source Large Language Model for Audit
Oct 09, 2024



Intelligent auditing represents a crucial advancement in modern audit practices, enhancing both the quality and efficiency of audits within the realm of artificial intelligence. With the rise of large language model (LLM), there is enormous potential for intelligent models to contribute to audit domain. However, general LLMs applied in audit domain face the challenges of lacking specialized knowledge and the presence of data biases. To overcome these challenges, this study introduces AuditWen, an open-source audit LLM by fine-tuning Qwen with constructing instruction data from audit domain. We first outline the application scenarios for LLMs in the audit and extract requirements that shape the development of LLMs tailored for audit purposes. We then propose an audit LLM, called AuditWen, by fine-tuning Qwen with constructing 28k instruction dataset from 15 audit tasks and 3 layers. In evaluation stage, we proposed a benchmark with 3k instructions that covers a set of critical audit tasks derived from the application scenarios. With the benchmark, we compare AuditWen with other existing LLMs from information extraction, question answering and document generation. The experimental results demonstrate superior performance of AuditWen both in question understanding and answer generation, making it an immediately valuable tool for audit.
Enhancing Fine-grained Object Detection in Aerial Images via Orthogonal Mapping
Jul 25, 2024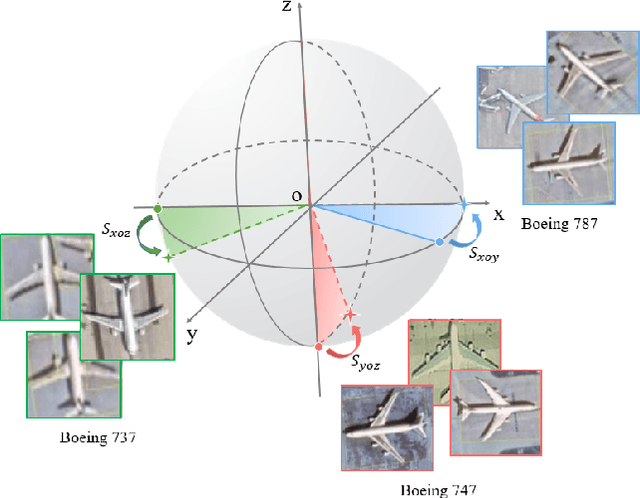
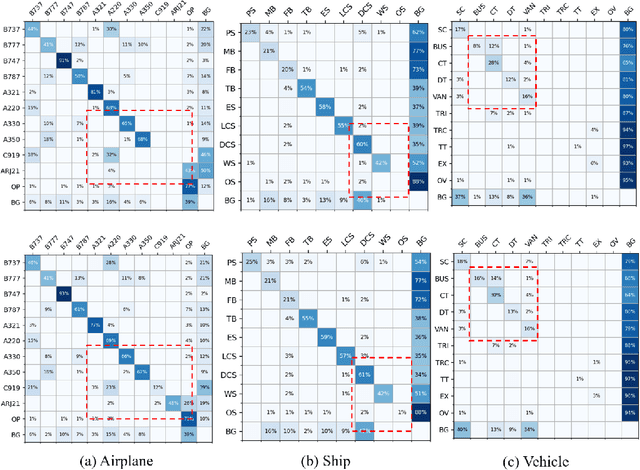
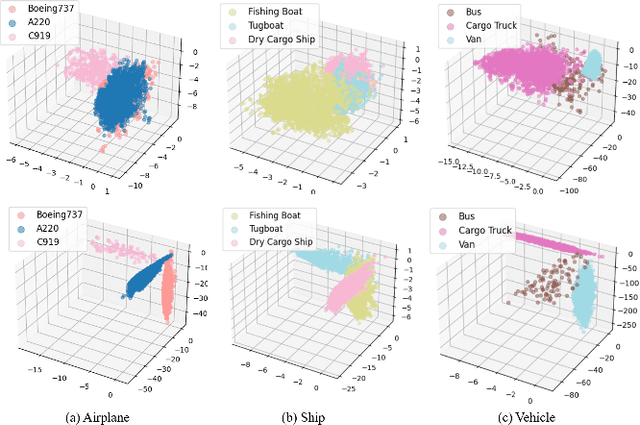
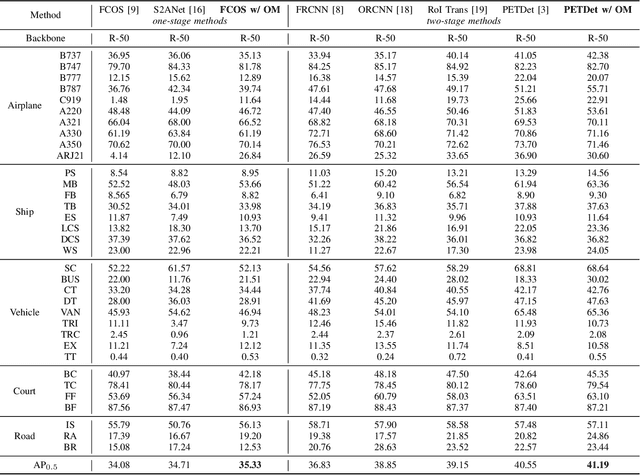
Fine-Grained Object Detection (FGOD) is a critical task in high-resolution aerial image analysis. This letter introduces Orthogonal Mapping (OM), a simple yet effective method aimed at addressing the challenge of semantic confusion inherent in FGOD. OM introduces orthogonal constraints in the feature space by decoupling features from the last layer of the classification branch with a class-wise orthogonal vector basis. This effectively mitigates semantic confusion and enhances classification accuracy. Moreover, OM can be seamlessly integrated into mainstream object detectors. Extensive experiments conducted on three FGOD datasets (FAIR1M, ShipRSImageNet, and MAR20) demonstrate the effectiveness and superiority of the proposed approach. Notably, with just one line of code, OM achieves a 4.08% improvement in mean Average Precision (mAP) over FCOS on the ShipRSImageNet dataset. Codes are released at https://github.com/ZhuHaoranEIS/Orthogonal-FGOD.
Robust Tiny Object Detection in Aerial Images amidst Label Noise
Jan 16, 2024Precise detection of tiny objects in remote sensing imagery remains a significant challenge due to their limited visual information and frequent occurrence within scenes. This challenge is further exacerbated by the practical burden and inherent errors associated with manual annotation: annotating tiny objects is laborious and prone to errors (i.e., label noise). Training detectors for such objects using noisy labels often leads to suboptimal performance, with networks tending to overfit on noisy labels. In this study, we address the intricate issue of tiny object detection under noisy label supervision. We systematically investigate the impact of various types of noise on network training, revealing the vulnerability of object detectors to class shifts and inaccurate bounding boxes for tiny objects. To mitigate these challenges, we propose a DeNoising Tiny Object Detector (DN-TOD), which incorporates a Class-aware Label Correction (CLC) scheme to address class shifts and a Trend-guided Learning Strategy (TLS) to handle bounding box noise. CLC mitigates inaccurate class supervision by identifying and filtering out class-shifted positive samples, while TLS reduces noisy box-induced erroneous supervision through sample reweighting and bounding box regeneration. Additionally, Our method can be seamlessly integrated into both one-stage and two-stage object detection pipelines. Comprehensive experiments conducted on synthetic (i.e., noisy AI-TOD-v2.0 and DOTA-v2.0) and real-world (i.e., AI-TOD) noisy datasets demonstrate the robustness of DN-TOD under various types of label noise. Notably, when applied to the strong baseline RFLA, DN-TOD exhibits a noteworthy performance improvement of 4.9 points under 40% mixed noise. Datasets, codes, and models will be made publicly available.
Understanding Why ViT Trains Badly on Small Datasets: An Intuitive Perspective
Feb 07, 2023Vision transformer (ViT) is an attention neural network architecture that is shown to be effective for computer vision tasks. However, compared to ResNet-18 with a similar number of parameters, ViT has a significantly lower evaluation accuracy when trained on small datasets. To facilitate studies in related fields, we provide a visual intuition to help understand why it is the case. We first compare the performance of the two models and confirm that ViT has less accuracy than ResNet-18 when trained on small datasets. We then interpret the results by showing attention map visualization for ViT and feature map visualization for ResNet-18. The difference is further analyzed through a representation similarity perspective. We conclude that the representation of ViT trained on small datasets is hugely different from ViT trained on large datasets, which may be the reason why the performance drops a lot on small datasets.
TAME: Task Agnostic Continual Learning using Multiple Experts
Oct 08, 2022
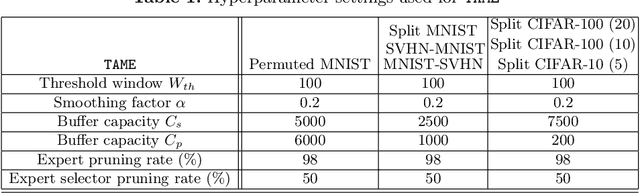

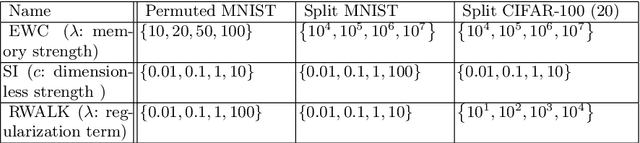
The goal of lifelong learning is to continuously learn from non-stationary distributions, where the non-stationarity is typically imposed by a sequence of distinct tasks. Prior works have mostly considered idealistic settings, where the identity of tasks is known at least at training. In this paper we focus on a fundamentally harder, so-called task-agnostic setting where the task identities are not known and the learning machine needs to infer them from the observations. Our algorithm, which we call TAME (Task-Agnostic continual learning using Multiple Experts), automatically detects the shift in data distributions and switches between task expert networks in an online manner. At training, the strategy for switching between tasks hinges on an extremely simple observation that for each new coming task there occurs a statistically-significant deviation in the value of the loss function that marks the onset of this new task. At inference, the switching between experts is governed by the selector network that forwards the test sample to its relevant expert network. The selector network is trained on a small subset of data drawn uniformly at random. We control the growth of the task expert networks as well as selector network by employing online pruning. Our experimental results show the efficacy of our approach on benchmark continual learning data sets, outperforming the previous task-agnostic methods and even the techniques that admit task identities at both training and testing, while at the same time using a comparable model size.