 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Fine-Grained Aerial Object Detection
Jun 15, 2026Fine-grained aerial object detection, driven by the intrinsic granularity of real-world object categories, is crucial for advanced scene understanding in remote sensing. Existing methods largely inherit the paradigm of coarse-grained object detection, relying solely on single-label supervision and thus struggling to distinguish model-level categories with subtle structural differences. However, for each specific model (e.g., Boeing 787), structured prior knowledge such as attributes and hierarchies offers discriminative semantics across multiple granularities. Motivated by this, we present ExpertDet, a scheme that incorporates expert-informed cues to enhance fine-grained aerial object detection. Specifically, we design Vision-aware Masked Attribute Modeling (VMAM), which aligns attribute semantics with visual structures by reconstructing randomly masked attributes from visual cues, enabling the detector to capture subtle structural distinctions. We further propose Hierarchical Visual Instance Promotion (HierVIP), which builds a visual prototype tree based on hierarchical relations and imposes taxonomy-aware constraints to preserve cross-level semantic continuity while enhancing category discrimination. Moreover, we curate a new fine-grained object detection benchmark for Precise recognition of model-specific Ships and Planes from aerial imagery, PSP, covering 106 ship classes and 30 airplane models, respectively, featuring the most extensive collection of model-specific categories among existing aerial object detection datasets to date. We benchmark state-of-the-art object detection algorithms on the PSP benchmark. Extensive evaluation demonstrates that ExpertDet consistently outperforms other fine-grained competitors across hierarchy levels. The dataset, benchmark, and code are available at https://nnnnerd.github.io/PSP-Benchmark/.
AndroidDaily: A Verifiable Benchmark for Mobile GUI Agents on Real-World Closed-Source Applications
May 26, 2026The rapid development of GUI foundation models and mobile GUI agents has spurred numerous evaluation benchmarks, yet most rely on simulated environments or open-source applications, leaving real-world closed-source applications largely unevaluated. The core difficulty is that closed-source applications do not expose internal states, making traditional automatic verification inapplicable. To bridge this gap, we introduce AndroidDaily, a large-scale benchmark comprising 350 realistic daily-use tasks across 94 high-frequency Android applications spanning transportation, shopping, local services, entertainment, content creation, social media, and everyday utilities. To enable automatic and verifiable assessment in these opaque environments, we propose Guideline-grounded Reviewer for Automatic Diagnostic Evaluation (GRADE), a process-aware evaluator built on a three-tiered system of observable external guidelines: operational obligations, output quality, and negative constraints. GRADE tracks the agent's visual trajectory against these criteria and produces step-level diagnostic judgments, turning long-horizon, open-ended mobile interactions into verifiable evaluation without relying on hidden internal states. Experiments show that GRADE achieves 87.37\% agreement with human evaluators. The strongest model reaches a 62.0\% success rate on AndroidDaily, highlighting a substantial gap between current reasoning capabilities and practical execution in realistic mobile workflows.
UHR-DETR: Efficient End-to-End Small Object Detection for Ultra-High-Resolution Remote Sensing Imagery
Apr 23, 2026Ultra-High-Resolution (UHR) imagery has become essential for modern remote sensing, offering unprecedented spatial coverage. However, detecting small objects in such vast scenes presents a critical dilemma: retaining the original resolution for small objects causes prohibitive memory bottlenecks. Conversely, conventional compromises like image downsampling or patch cropping either erase small objects or destroy context. To break this dilemma, we propose UHR-DETR, an efficient end-to-end transformer-based detector designed for UHR imagery. First, we introduce a Coverage-Maximizing Sparse Encoder that dynamically allocates finite computational resources to informative high-resolution regions, ensuring maximum object coverage with minimal spatial redundancy. Second, we design a Global-Local Decoupled Decoder. By integrating macroscopic scene awareness with microscopic object details, this module resolves semantic ambiguities and prevents scene fragmentation. Extensive experiments on the UHR imagery datasets (e.g., STAR and SODA-A) demonstrate the superiority of UHR-DETR under strict hardware constraints (e.g., a single 24GB RTX 3090). It achieves a 2.8\% mAP improvement while delivering a 10$\times$ inference speedup compared to standard sliding-window baselines on the STAR dataset. Our codes and models will be available at https://github.com/Li-JingFang/UHR-DETR.
LSGS-Loc: Towards Robust 3DGS-Based Visual Localization for Large-Scale UAV Scenarios
Apr 07, 2026Visual localization in large-scale UAV scenarios is a critical capability for autonomous systems, yet it remains challenging due to geometric complexity and environmental variations. While 3D Gaussian Splatting (3DGS) has emerged as a promising scene representation, existing 3DGS-based visual localization methods struggle with robust pose initialization and sensitivity to rendering artifacts in large-scale settings. To address these limitations, we propose LSGS-Loc, a novel visual localization pipeline tailored for large-scale 3DGS scenes. Specifically, we introduce a scale-aware pose initialization strategy that combines scene-agnostic relative pose estimation with explicit 3DGS scale constraints, enabling geometrically grounded localization without scene-specific training. Furthermore, in the pose refinement, to mitigate the impact of reconstruction artifacts such as blur and floaters, we develop a Laplacian-based reliability masking mechanism that guides photometric refinement toward high-quality regions. Extensive experiments on large-scale UAV benchmarks demonstrate that our method achieves state-of-the-art accuracy and robustness for unordered image queries, significantly outperforming existing 3DGS-based approaches. Code is available at: https://github.com/xzhang-z/LSGS-Loc
Generalized Small Object Detection:A Point-Prompted Paradigm and Benchmark
Apr 03, 2026Small object detection (SOD) remains challenging due to extremely limited pixels and ambiguous object boundaries. These characteristics lead to challenging annotation, limited availability of large-scale high-quality datasets, and inherently weak semantic representations for small objects. In this work, we first address the data limitation by introducing TinySet-9M, the first large-scale, multi-domain dataset for small object detection. Beyond filling the gap in large-scale datasets, we establish a benchmark to evaluate the effectiveness of existing label-efficient detection methods for small objects. Our evaluation reveals that weak visual cues further exacerbate the performance degradation of label-efficient methods in small object detection, highlighting a critical challenge in label-efficient SOD. Secondly, to tackle the limitation of insufficient semantic representation, we move beyond training-time feature enhancement and propose a new paradigm termed Point-Prompt Small Object Detection (P2SOD). This paradigm introduces sparse point prompts at inference time as an efficient information bridge for category-level localization, enabling semantic augmentation. Building upon the P2SOD paradigm and the large-scale TinySet-9M dataset, we further develop DEAL (DEtect Any smalL object), a scalable and transferable point-prompted detection framework that learns robust, prompt-conditioned representations from large-scale data. With only a single click at inference time, DEAL achieves a 31.4% relative improvement over fully supervised baselines under strict localization metrics (e.g., AP75) on TinySet-9M, while generalizing effectively to unseen categories and unseen datasets. Our project is available at https://zhuhaoraneis.github.io/TinySet-9M/.
Unifying UAV Cross-View Geo-Localization via 3D Geometric Perception
Apr 02, 2026Cross-view geo-localization for Unmanned Aerial Vehicles (UAVs) operating in GNSS-denied environments remains challenging due to the severe geometric discrepancy between oblique UAV imagery and orthogonal satellite maps. Most existing methods address this problem through a decoupled pipeline of place retrieval and pose estimation, implicitly treating perspective distortion as appearance noise rather than an explicit geometric transformation. In this work, we propose a geometry-aware UAV geo-localization framework that explicitly models the 3D scene geometry to unify coarse place recognition and fine-grained pose estimation within a single inference pipeline. Our approach reconstructs a local 3D scene from multi-view UAV image sequences using a Visual Geometry Grounded Transformer (VGGT), and renders a virtual Bird's-Eye View (BEV) representation that orthorectifies the UAV perspective to align with satellite imagery. This BEV serves as a geometric intermediary that enables robust cross-view retrieval and provides spatial priors for accurate 3 Degrees of Freedom (3-DoF) pose regression. To efficiently handle multiple location hypotheses, we introduce a Satellite-wise Attention Block that isolates the interaction between each satellite candidate and the reconstructed UAV scene, preventing inter-candidate interference while maintaining linear computational complexity. In addition, we release a recalibrated version of the University-1652 dataset with precise coordinate annotations and spatial overlap analysis, enabling rigorous evaluation of end-to-end localization accuracy. Extensive experiments on the refined University-1652 benchmark and SUES-200 demonstrate that our method significantly outperforms state-of-the-art baselines, achieving robust meter-level localization accuracy and improved generalization in complex urban environments.
Unified ROI-based Image Compression Paradigm with Generalized Gaussian Model
Feb 01, 2026Region-of-Interest (ROI)-based image compression allocates bits unevenly according to the semantic importance of different regions. Such differentiated coding typically induces a sharp-peaked and heavy-tailed distribution. This distribution characteristic mathematically necessitates a probability model with adaptable shape parameters for accurate description. However, existing methods commonly use a Gaussian model to fit this distribution, resulting in a loss of coding performance. To systematically analyze the impact of this distribution on ROI coding, we develop a unified rate-distortion optimization theoretical paradigm. Building on this paradigm, we propose a novel Generalized Gaussian Model (GGM) to achieve flexible modeling of the latent variables distribution. To support stable optimization of GGM, we introduce effective differentiable functions and further propose a dynamic lower bound to alleviate train-test mismatch. Moreover, finite differences are introduced to solve the gradient computation after GGM fits the distribution. Experiments on COCO2017 demonstrate that our method achieves state-of-the-art in both ROI reconstruction and downstream tasks (e.g., Segmentation, Object Detection). Furthermore, compared to classical probability models, our GGM provides a more precise fit to feature distributions and achieves superior coding performance. The project page is at https://github.com/hukai-tju/ROIGGM.
An effective interactive brain cytoarchitectonic parcellation framework using pretrained foundation model
Jan 15, 2026Cytoarchitectonic mapping provides anatomically grounded parcellations of brain structure and forms a foundation for integrative, multi-modal neuroscience analyses. These parcellations are defined based on the shape, density, and spatial arrangement of neuronal cell bodies observed in histological imaging. Recent works have demonstrated the potential of using deep learning models toward fully automatic segmentation of cytoarchitectonic areas in large-scale datasets, but performance is mainly constrained by the scarcity of training labels and the variability of staining and imaging conditions. To address these challenges, we propose an interactive cytoarchitectonic parcellation framework that leverages the strong transferability of the DINOv3 vision transformer. Our framework combines (i) multi-layer DINOv3 feature fusion, (ii) a lightweight segmentation decoder, and (iii) real-time user-guided training from sparse scribbles. This design enables rapid human-in-the-loop refinement while maintaining high segmentation accuracy. Compared with training an nnU-Net from scratch, transfer learning with DINOv3 yields markedly improved performance. We also show that features extracted by DINOv3 exhibit clear anatomical correspondence and demonstrate the method's practical utility for brain region segmentation using sparse labels. These results highlight the potential of foundation-model-driven interactive segmentation for scalable and efficient cytoarchitectonic mapping.
EpiPlanAgent: Agentic Automated Epidemic Response Planning
Dec 12, 2025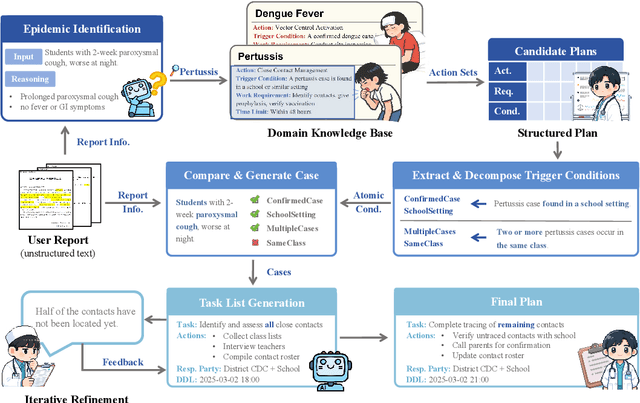

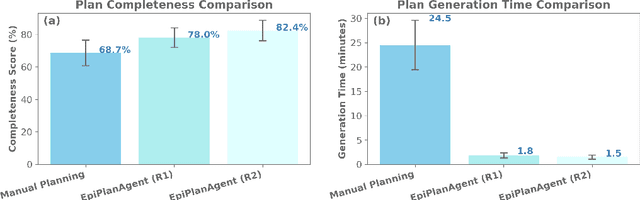

Epidemic response planning is essential yet traditionally reliant on labor-intensive manual methods. This study aimed to design and evaluate EpiPlanAgent, an agent-based system using large language models (LLMs) to automate the generation and validation of digital emergency response plans. The multi-agent framework integrated task decomposition, knowledge grounding, and simulation modules. Public health professionals tested the system using real-world outbreak scenarios in a controlled evaluation. Results demonstrated that EpiPlanAgent significantly improved the completeness and guideline alignment of plans while drastically reducing development time compared to manual workflows. Expert evaluation confirmed high consistency between AI-generated and human-authored content. User feedback indicated strong perceived utility. In conclusion, EpiPlanAgent provides an effective, scalable solution for intelligent epidemic response planning, demonstrating the potential of agentic AI to transform public health preparedness.
Mitigating the Impact of Prominent Position Shift in Drone-based RGBT Object Detection
Feb 13, 2025Drone-based RGBT object detection plays a crucial role in many around-the-clock applications. However, real-world drone-viewed RGBT data suffers from the prominent position shift problem, i.e., the position of a tiny object differs greatly in different modalities. For instance, a slight deviation of a tiny object in the thermal modality will induce it to drift from the main body of itself in the RGB modality. Considering RGBT data are usually labeled on one modality (reference), this will cause the unlabeled modality (sensed) to lack accurate supervision signals and prevent the detector from learning a good representation. Moreover, the mismatch of the corresponding feature point between the modalities will make the fused features confusing for the detection head. In this paper, we propose to cast the cross-modality box shift issue as the label noise problem and address it on the fly via a novel Mean Teacher-based Cross-modality Box Correction head ensemble (CBC). In this way, the network can learn more informative representations for both modalities. Furthermore, to alleviate the feature map mismatch problem in RGBT fusion, we devise a Shifted Window-Based Cascaded Alignment (SWCA) module. SWCA mines long-range dependencies between the spatially unaligned features inside shifted windows and cascaded aligns the sensed features with the reference ones. Extensive experiments on two drone-based RGBT object detection datasets demonstrate that the correction results are both visually and quantitatively favorable, thereby improving the detection performance. In particular, our CBC module boosts the precision of the sensed modality ground truth by 25.52 aSim points. Overall, the proposed detector achieves an mAP_50 of 43.55 points on RGBTDronePerson and surpasses a state-of-the-art method by 8.6 mAP50 on a shift subset of DroneVehicle dataset. The code and data will be made publicly available.