 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility of Pancreas Surface Lobularity as a CT Biomarker for Opportunistic Screening of Type 2 Diabetes
Nov 13, 2025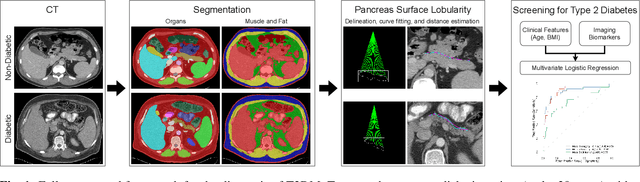
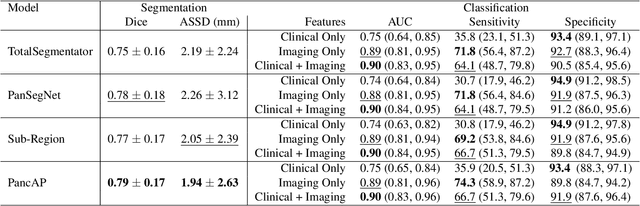
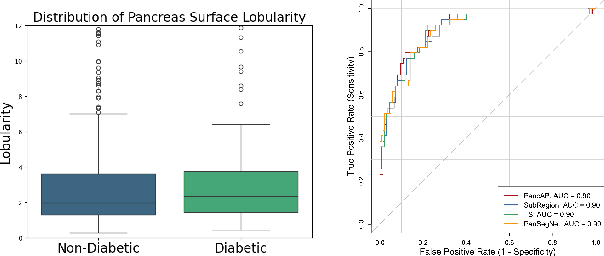
Type 2 Diabetes Mellitus (T2DM) is a chronic metabolic disease that affects millions of people worldwide. Early detection is crucial as it can alter pancreas function through morphological changes and increased deposition of ectopic fat, eventually leading to organ damage. While studies have shown an association between T2DM and pancreas volume and fat content, the role of increased pancreatic surface lobularity (PSL) in patients with T2DM has not been fully investigated. In this pilot work, we propose a fully automated approach to delineate the pancreas and other abdominal structures, derive CT imaging biomarkers, and opportunistically screen for T2DM. Four deep learning-based models were used to segment the pancreas in an internal dataset of 584 patients (297 males, 437 non-diabetic, age: 45$\pm$15 years). PSL was automatically detected and it was higher for diabetic patients (p=0.01) at 4.26 $\pm$ 8.32 compared to 3.19 $\pm$ 3.62 for non-diabetic patients. The PancAP model achieved the highest Dice score of 0.79 $\pm$ 0.17 and lowest ASSD error of 1.94 $\pm$ 2.63 mm (p$<$0.05). For predicting T2DM, a multivariate model trained with CT biomarkers attained 0.90 AUC, 66.7\% sensitivity, and 91.9\% specificity. Our results suggest that PSL is useful for T2DM screening and could potentially help predict the early onset of T2DM.
Efficient 2D CT Foundation Model for Contrast Phase Classification
Jan 23, 2025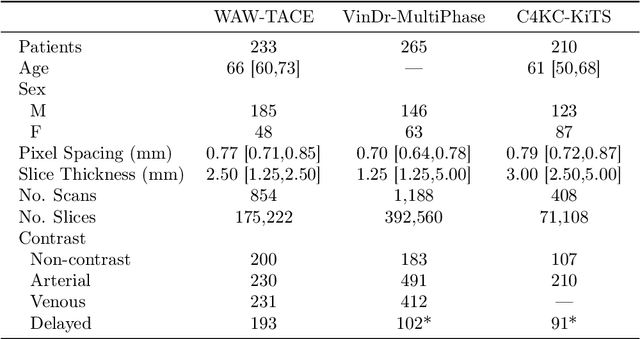
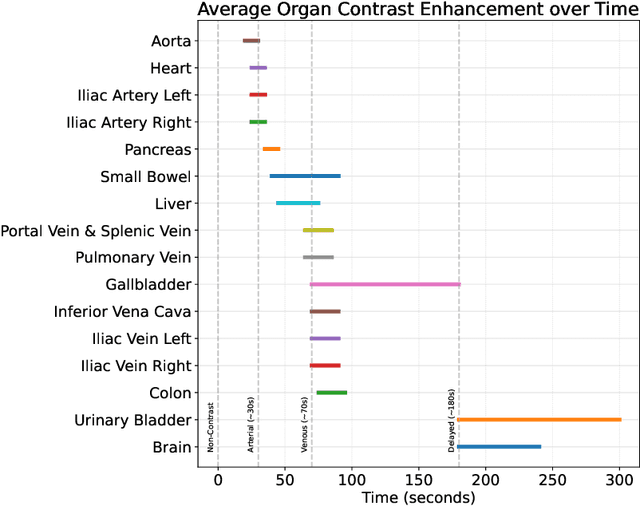
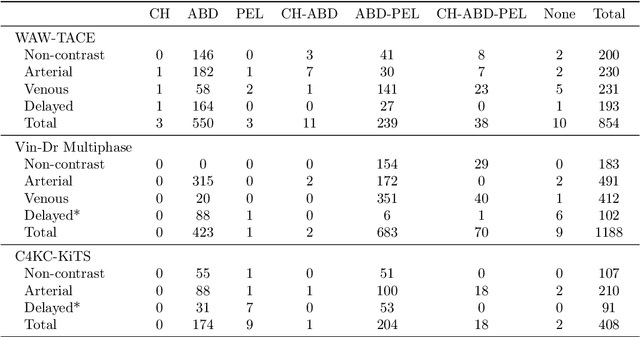
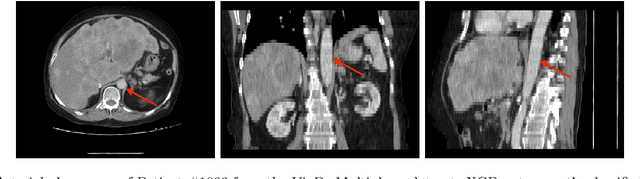
Purpose: The purpose of this study is to harness the efficiency of a 2D foundation model to develop a robust phase classifier that is resilient to domain shifts. Materials and Methods: This retrospective study utilized three public datasets from separate institutions. A 2D foundation model was trained on the DeepLesion dataset (mean age: 51.2, s.d.: 17.6; 2398 males) to generate embeddings from 2D CT slices for downstream contrast phase classification. The classifier was trained on the VinDr Multiphase dataset and externally validated on the WAW-TACE dataset. The 2D model was also compared to three 3D supervised models. Results: On the VinDr dataset (146 male, 63 female, 56 unidentified), the model achieved near-perfect AUROC scores and F1 scores of 99.2%, 94.2%, and 93.1% for non-contrast, arterial, and venous phases, respectively. The `Other' category scored lower (F1: 73.4%) due to combining multiple contrast phases into one class. On the WAW-TACE dataset (mean age: 66.1, s.d.: 10.0; 185 males), the model showed strong performance with AUROCs of 91.0% and 85.6%, and F1 scores of 87.3% and 74.1% for non-contrast and arterial phases. Venous phase performance was lower, with AUROC and F1 scores of 81.7% and 70.2% respectively, due to label mismatches. Compared to 3D supervised models, the approach trained faster, performed as well or better, and showed greater robustness to domain shifts. Conclusion: The robustness of the 2D Foundation model may be potentially useful for automation of hanging protocols and data orchestration for clinical deployment of AI algorithms.
Leveraging Multiphase CT for Quality Enhancement of Portal Venous CT: Utility for Pancreas Segmentation
Jan 23, 2025



Multiphase CT studies are routinely obtained in clinical practice for diagnosis and management of various diseases, such as cancer. However, the CT studies can be acquired with low radiation doses, different scanners, and are frequently affected by motion and metal artifacts. Prior approaches have targeted the quality improvement of one specific CT phase (e.g., non-contrast CT). In this work, we hypothesized that leveraging multiple CT phases for the quality enhancement of one phase may prove advantageous for downstream tasks, such as segmentation. A 3D progressive fusion and non-local (PFNL) network was developed. It was trained with three degraded (low-quality) phases (non-contrast, arterial, and portal venous) to enhance the quality of the portal venous phase. Then, the effect of scan quality enhancement was evaluated using a proxy task of pancreas segmentation, which is useful for tracking pancreatic cancer. The proposed approach improved the pancreas segmentation by 3% over the corresponding low-quality CT scan. To the best of our knowledge, we are the first to harness multiphase CT for scan quality enhancement and improved pancreas segmentation.
Frequency-Adaptive Low-Latency Object Detection Using Events and Frames
Dec 05, 2024



Fusing Events and RGB images for object detection leverages the robustness of Event cameras in adverse environments and the rich semantic information provided by RGB cameras. However, two critical mismatches: low-latency Events \textit{vs.}~high-latency RGB frames; temporally sparse labels in training \textit{vs.}~continuous flow in inference, significantly hinder the high-frequency fusion-based object detection. To address these challenges, we propose the \textbf{F}requency-\textbf{A}daptive Low-Latency \textbf{O}bject \textbf{D}etector (FAOD). FAOD aligns low-frequency RGB frames with high-frequency Events through an Align Module, which reinforces cross-modal style and spatial proximity to address the Event-RGB Mismatch. We further propose a training strategy, Time Shift, which enforces the module to align the prediction from temporally shifted Event-RGB pairs and their original representation, that is, consistent with Event-aligned annotations. This strategy enables the network to use high-frequency Event data as the primary reference while treating low-frequency RGB images as supplementary information, retaining the low-latency nature of the Event stream toward high-frequency detection. Furthermore, we observe that these corrected Event-RGB pairs demonstrate better generalization from low training frequency to higher inference frequencies compared to using Event data alone. Extensive experiments on the PKU-DAVIS-SOD and DSEC-Detection datasets demonstrate that our FAOD achieves SOTA performance. Specifically, in the PKU-DAVIS-SOD Dataset, FAOD achieves 9.8 points improvement in terms of the mAP in fully paired Event-RGB data with only a quarter of the parameters compared to SODFormer, and even maintains robust performance (only a 3 points drop in mAP) under 80$\times$ Event-RGB frequency mismatch.
Detecting Every Object from Events
Apr 08, 2024



Object detection is critical in autonomous driving, and it is more practical yet challenging to localize objects of unknown categories: an endeavour known as Class-Agnostic Object Detection (CAOD). Existing studies on CAOD predominantly rely on ordinary cameras, but these frame-based sensors usually have high latency and limited dynamic range, leading to safety risks in real-world scenarios. In this study, we turn to a new modality enabled by the so-called event camera, featured by its sub-millisecond latency and high dynamic range, for robust CAOD. We propose Detecting Every Object in Events (DEOE), an approach tailored for achieving high-speed, class-agnostic open-world object detection in event-based vision. Built upon the fast event-based backbone: recurrent vision transformer, we jointly consider the spatial and temporal consistencies to identify potential objects. The discovered potential objects are assimilated as soft positive samples to avoid being suppressed as background. Moreover, we introduce a disentangled objectness head to separate the foreground-background classification and novel object discovery tasks, enhancing the model's generalization in localizing novel objects while maintaining a strong ability to filter out the background. Extensive experiments confirm the superiority of our proposed DEOE in comparison with three strong baseline methods that integrate the state-of-the-art event-based object detector with advancements in RGB-based CAOD. Our code is available at https://github.com/Hatins/DEOE.