 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
A first-order method for nonconvex-nonconcave minimax problems under a local Kurdyka-Łojasiewicz condition
Jul 02, 2025We study a class of nonconvex-nonconcave minimax problems in which the inner maximization problem satisfies a local Kurdyka-{\L}ojasiewicz (KL) condition that may vary with the outer minimization variable. In contrast to the global KL or Polyak-{\L}ojasiewicz (PL) conditions commonly assumed in the literature -- which are significantly stronger and often too restrictive in practice -- this local KL condition accommodates a broader range of practical scenarios. However, it also introduces new analytical challenges. In particular, as an optimization algorithm progresses toward a stationary point of the problem, the region over which the KL condition holds may shrink, resulting in a more intricate and potentially ill-conditioned landscape. To address this challenge, we show that the associated maximal function is locally H\"older smooth. Leveraging this key property, we develop an inexact proximal gradient method for solving the minimax problem, where the inexact gradient of the maximal function is computed by applying a proximal gradient method to a KL-structured subproblem. Under mild assumptions, we establish complexity guarantees for computing an approximate stationary point of the minimax problem.
Frequency-Adaptive Low-Latency Object Detection Using Events and Frames
Dec 05, 2024



Fusing Events and RGB images for object detection leverages the robustness of Event cameras in adverse environments and the rich semantic information provided by RGB cameras. However, two critical mismatches: low-latency Events \textit{vs.}~high-latency RGB frames; temporally sparse labels in training \textit{vs.}~continuous flow in inference, significantly hinder the high-frequency fusion-based object detection. To address these challenges, we propose the \textbf{F}requency-\textbf{A}daptive Low-Latency \textbf{O}bject \textbf{D}etector (FAOD). FAOD aligns low-frequency RGB frames with high-frequency Events through an Align Module, which reinforces cross-modal style and spatial proximity to address the Event-RGB Mismatch. We further propose a training strategy, Time Shift, which enforces the module to align the prediction from temporally shifted Event-RGB pairs and their original representation, that is, consistent with Event-aligned annotations. This strategy enables the network to use high-frequency Event data as the primary reference while treating low-frequency RGB images as supplementary information, retaining the low-latency nature of the Event stream toward high-frequency detection. Furthermore, we observe that these corrected Event-RGB pairs demonstrate better generalization from low training frequency to higher inference frequencies compared to using Event data alone. Extensive experiments on the PKU-DAVIS-SOD and DSEC-Detection datasets demonstrate that our FAOD achieves SOTA performance. Specifically, in the PKU-DAVIS-SOD Dataset, FAOD achieves 9.8 points improvement in terms of the mAP in fully paired Event-RGB data with only a quarter of the parameters compared to SODFormer, and even maintains robust performance (only a 3 points drop in mAP) under 80$\times$ Event-RGB frequency mismatch.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
MMFace4D: A Large-Scale Multi-Modal 4D Face Dataset for Audio-Driven 3D Face Animation
Mar 17, 2023



Audio-Driven Face Animation is an eagerly anticipated technique for applications such as VR/AR, games, and movie making. With the rapid development of 3D engines, there is an increasing demand for driving 3D faces with audio. However, currently available 3D face animation datasets are either scale-limited or quality-unsatisfied, which hampers further developments of audio-driven 3D face animation. To address this challenge, we propose MMFace4D, a large-scale multi-modal 4D (3D sequence) face dataset consisting of 431 identities, 35,904 sequences, and 3.9 million frames. MMFace4D has three appealing characteristics: 1) highly diversified subjects and corpus, 2) synchronized audio and 3D mesh sequence with high-resolution face details, and 3) low storage cost with a new efficient compression algorithm on 3D mesh sequences. These characteristics enable the training of high-fidelity, expressive, and generalizable face animation models. Upon MMFace4D, we construct a challenging benchmark of audio-driven 3D face animation with a strong baseline, which enables non-autoregressive generation with fast inference speed and outperforms the state-of-the-art autoregressive method. The whole benchmark will be released.
High-Quality Real Time Facial Capture Based on Single Camera
Nov 15, 2021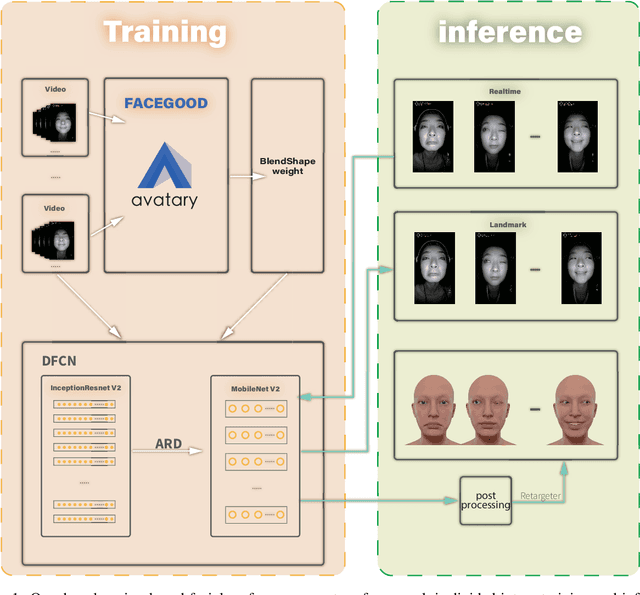



We propose a real time deep learning framework for video-based facial expression capture. Our process uses a high-end facial capture pipeline based on FACEGOOD to capture facial expression. We train a convolutional neural network to produce high-quality continuous blendshape weight output from video training. Since this facial capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We demonstrate compelling animation inference in challenging areas such as eyes and lips.