 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
Mar 20, 2024



Choreographers determine what the dances look like, while cameramen determine the final presentation of dances. Recently, various methods and datasets have showcased the feasibility of dance synthesis. However, camera movement synthesis with music and dance remains an unsolved challenging problem due to the scarcity of paired data. Thus, we present DCM, a new multi-modal 3D dataset, which for the first time combines camera movement with dance motion and music audio. This dataset encompasses 108 dance sequences (3.2 hours) of paired dance-camera-music data from the anime community, covering 4 music genres. With this dataset, we uncover that dance camera movement is multifaceted and human-centric, and possesses multiple influencing factors, making dance camera synthesis a more challenging task compared to camera or dance synthesis alone. To overcome these difficulties, we propose DanceCamera3D, a transformer-based diffusion model that incorporates a novel body attention loss and a condition separation strategy. For evaluation, we devise new metrics measuring camera movement quality, diversity, and dancer fidelity. Utilizing these metrics, we conduct extensive experiments on our DCM dataset, providing both quantitative and qualitative evidence showcasing the effectiveness of our DanceCamera3D model. Code and video demos are available at https://github.com/Carmenw1203/DanceCamera3D-Official.
Versatile Face Animator: Driving Arbitrary 3D Facial Avatar in RGBD Space
Aug 11, 2023



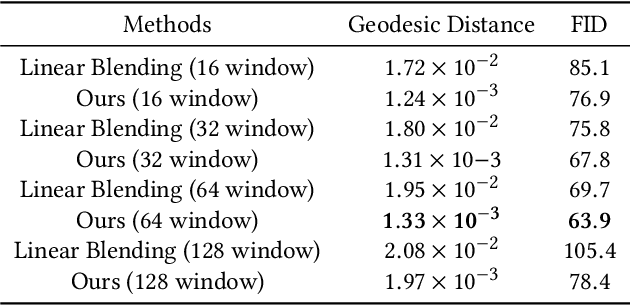
Creating realistic 3D facial animation is crucial for various applications in the movie production and gaming industry, especially with the burgeoning demand in the metaverse. However, prevalent methods such as blendshape-based approaches and facial rigging techniques are time-consuming, labor-intensive, and lack standardized configurations, making facial animation production challenging and costly. In this paper, we propose a novel self-supervised framework, Versatile Face Animator, which combines facial motion capture with motion retargeting in an end-to-end manner, eliminating the need for blendshapes or rigs. Our method has the following two main characteristics: 1) we propose an RGBD animation module to learn facial motion from raw RGBD videos by hierarchical motion dictionaries and animate RGBD images rendered from 3D facial mesh coarse-to-fine, enabling facial animation on arbitrary 3D characters regardless of their topology, textures, blendshapes, and rigs; and 2) we introduce a mesh retarget module to utilize RGBD animation to create 3D facial animation by manipulating facial mesh with controller transformations, which are estimated from dense optical flow fields and blended together with geodesic-distance-based weights. Comprehensive experiments demonstrate the effectiveness of our proposed framework in generating impressive 3D facial animation results, highlighting its potential as a promising solution for the cost-effective and efficient production of facial animation in the metaverse.
Speech-Driven 3D Face Animation with Composite and Regional Facial Movements
Aug 10, 2023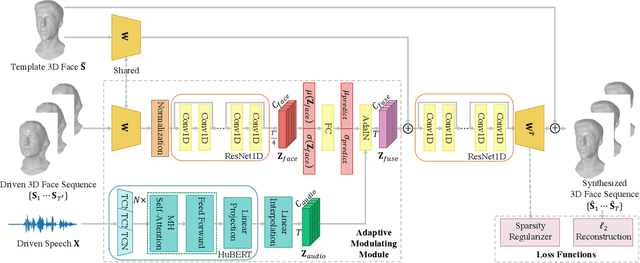
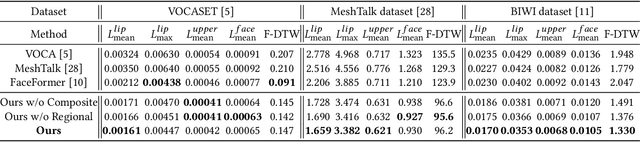
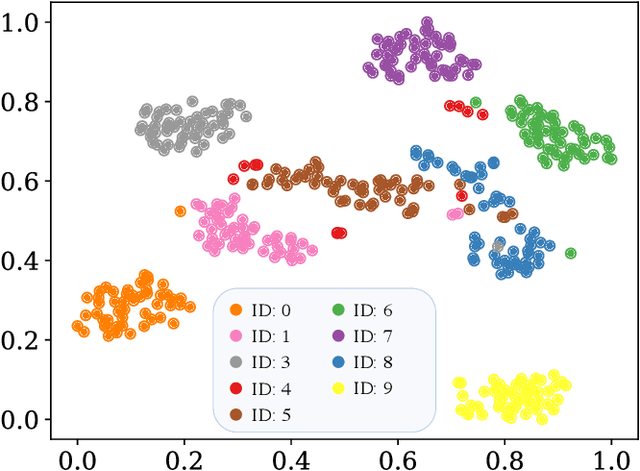
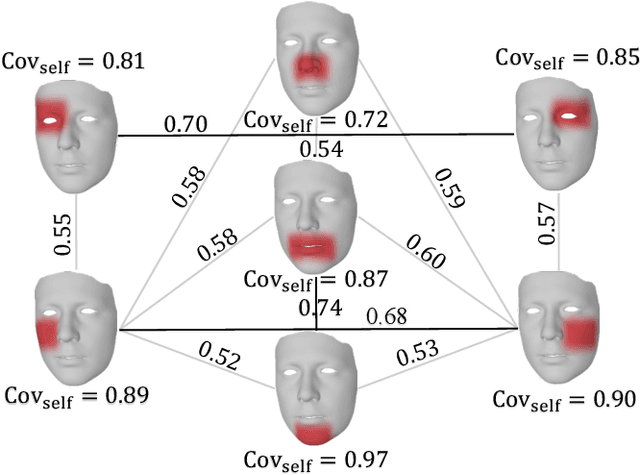
Speech-driven 3D face animation poses significant challenges due to the intricacy and variability inherent in human facial movements. This paper emphasizes the importance of considering both the composite and regional natures of facial movements in speech-driven 3D face animation. The composite nature pertains to how speech-independent factors globally modulate speech-driven facial movements along the temporal dimension. Meanwhile, the regional nature alludes to the notion that facial movements are not globally correlated but are actuated by local musculature along the spatial dimension. It is thus indispensable to incorporate both natures for engendering vivid animation. To address the composite nature, we introduce an adaptive modulation module that employs arbitrary facial movements to dynamically adjust speech-driven facial movements across frames on a global scale. To accommodate the regional nature, our approach ensures that each constituent of the facial features for every frame focuses on the local spatial movements of 3D faces. Moreover, we present a non-autoregressive backbone for translating audio to 3D facial movements, which maintains high-frequency nuances of facial movements and facilitates efficient inference. Comprehensive experiments and user studies demonstrate that our method surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively.
Shuffled Autoregression For Motion Interpolation
Jun 10, 2023



This work aims to provide a deep-learning solution for the motion interpolation task. Previous studies solve it with geometric weight functions. Some other works propose neural networks for different problem settings with consecutive pose sequences as input. However, motion interpolation is a more complex problem that takes isolated poses (e.g., only one start pose and one end pose) as input. When applied to motion interpolation, these deep learning methods have limited performance since they do not leverage the flexible dependencies between interpolation frames as the original geometric formulas do. To realize this interpolation characteristic, we propose a novel framework, referred to as \emph{Shuffled AutoRegression}, which expands the autoregression to generate in arbitrary (shuffled) order and models any inter-frame dependencies as a directed acyclic graph. We further propose an approach to constructing a particular kind of dependency graph, with three stages assembled into an end-to-end spatial-temporal motion Transformer. Experimental results on one of the current largest datasets show that our model generates vivid and coherent motions from only one start frame to one end frame and outperforms competing methods by a large margin. The proposed model is also extensible to multiple keyframes' motion interpolation tasks and other areas' interpolation.
MMFace4D: A Large-Scale Multi-Modal 4D Face Dataset for Audio-Driven 3D Face Animation
Mar 17, 2023



Audio-Driven Face Animation is an eagerly anticipated technique for applications such as VR/AR, games, and movie making. With the rapid development of 3D engines, there is an increasing demand for driving 3D faces with audio. However, currently available 3D face animation datasets are either scale-limited or quality-unsatisfied, which hampers further developments of audio-driven 3D face animation. To address this challenge, we propose MMFace4D, a large-scale multi-modal 4D (3D sequence) face dataset consisting of 431 identities, 35,904 sequences, and 3.9 million frames. MMFace4D has three appealing characteristics: 1) highly diversified subjects and corpus, 2) synchronized audio and 3D mesh sequence with high-resolution face details, and 3) low storage cost with a new efficient compression algorithm on 3D mesh sequences. These characteristics enable the training of high-fidelity, expressive, and generalizable face animation models. Upon MMFace4D, we construct a challenging benchmark of audio-driven 3D face animation with a strong baseline, which enables non-autoregressive generation with fast inference speed and outperforms the state-of-the-art autoregressive method. The whole benchmark will be released.
Imitating Arbitrary Talking Style for Realistic Audio-DrivenTalking Face Synthesis
Oct 30, 2021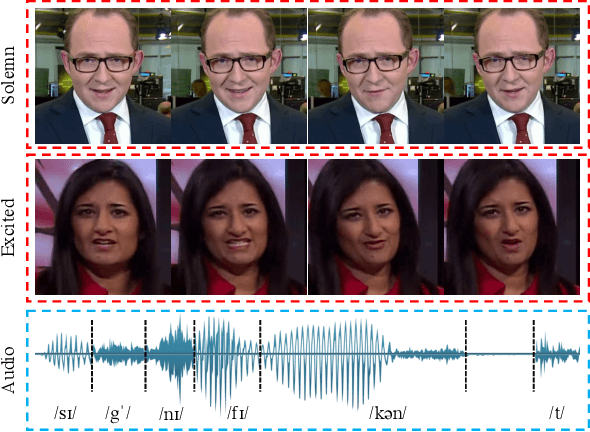
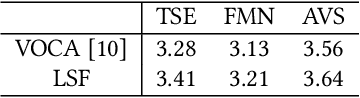
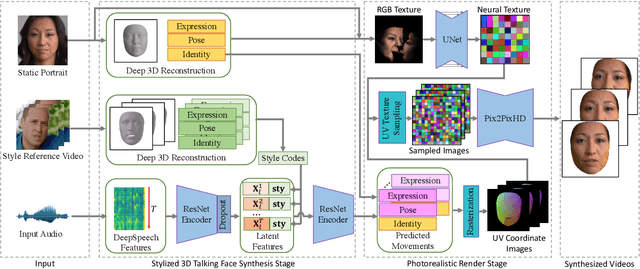
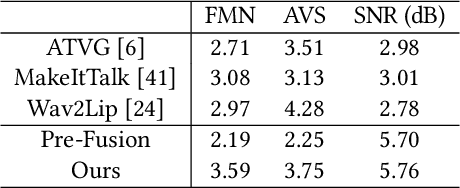
People talk with diversified styles. For one piece of speech, different talking styles exhibit significant differences in the facial and head pose movements. For example, the "excited" style usually talks with the mouth wide open, while the "solemn" style is more standardized and seldomly exhibits exaggerated motions. Due to such huge differences between different styles, it is necessary to incorporate the talking style into audio-driven talking face synthesis framework. In this paper, we propose to inject style into the talking face synthesis framework through imitating arbitrary talking style of the particular reference video. Specifically, we systematically investigate talking styles with our collected \textit{Ted-HD} dataset and construct style codes as several statistics of 3D morphable model~(3DMM) parameters. Afterwards, we devise a latent-style-fusion~(LSF) model to synthesize stylized talking faces by imitating talking styles from the style codes. We emphasize the following novel characteristics of our framework: (1) It doesn't require any annotation of the style, the talking style is learned in an unsupervised manner from talking videos in the wild. (2) It can imitate arbitrary styles from arbitrary videos, and the style codes can also be interpolated to generate new styles. Extensive experiments demonstrate that the proposed framework has the ability to synthesize more natural and expressive talking styles compared with baseline methods.
ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020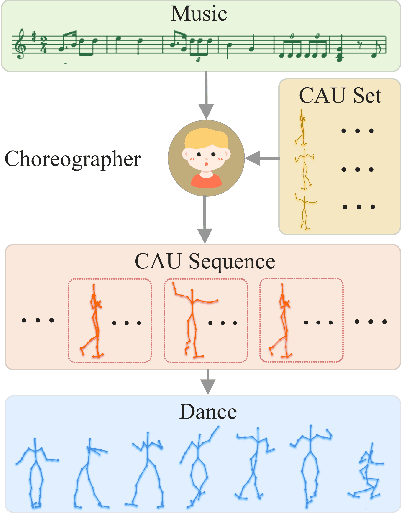

Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).
Disassembling the Dataset: A Camera Alignment Mechanism for Multiple Tasks in Person Re-identification
Jan 23, 2020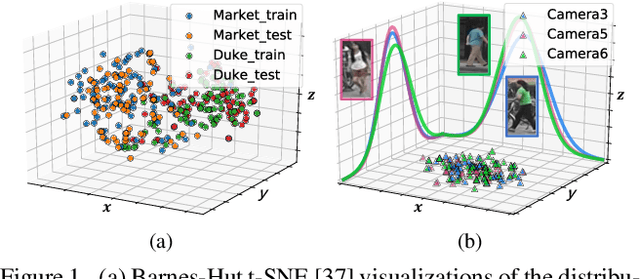
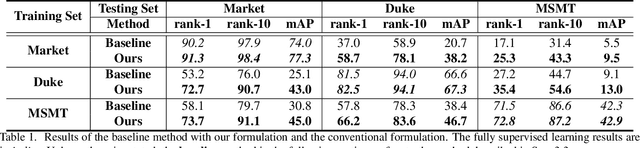
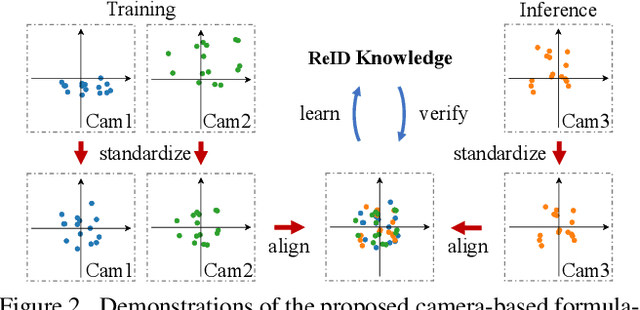
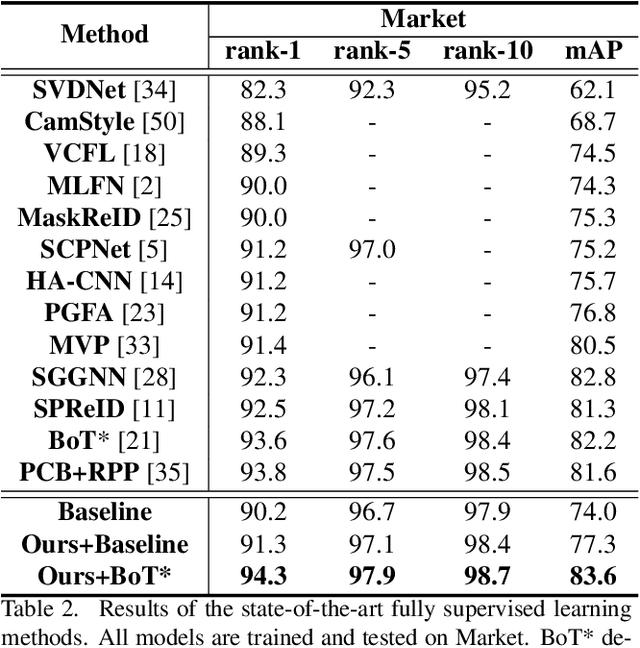
In person re-identification (ReID), one of the main challenges is the distribution inconsistency among different datasets. Previous researchers have defined several seemingly individual topics, such as fully supervised learning, direct transfer, domain adaptation, and incremental learning, each with different settings of training and testing scenarios. These topics are designed in a dataset-wise manner, i.e., images from the same dataset, even from disjoint cameras, are presumed to follow the same distribution. However, such distribution is coarse and training-set-specific, and the ReID knowledge learned in such manner works well only on the corresponding scenarios. To address this issue, we propose a fine-grained distribution alignment formulation, which disassembles the dataset and aligns all training and testing cameras. It connects all topics above and guarantees that ReID knowledge is always learned, accumulated, and verified in the aligned distributions. In practice, we devise the Camera-based Batch Normalization, which is easy for integration and nearly cost-free for existing ReID methods. Extensive experiments on the above four ReID tasks demonstrate the superiority of our approach. The code will be publicly available.
Mining Unfollow Behavior in Large-Scale Online Social Networks via Spatial-Temporal Interaction
Nov 17, 2019
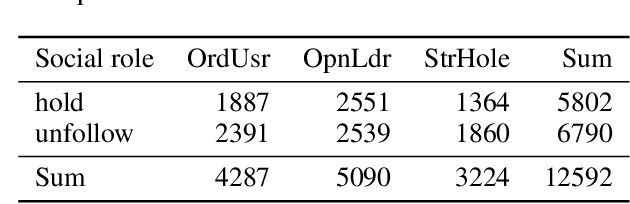
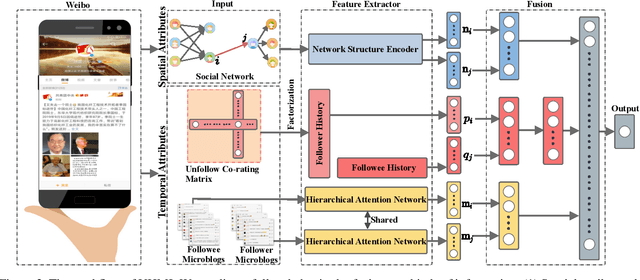
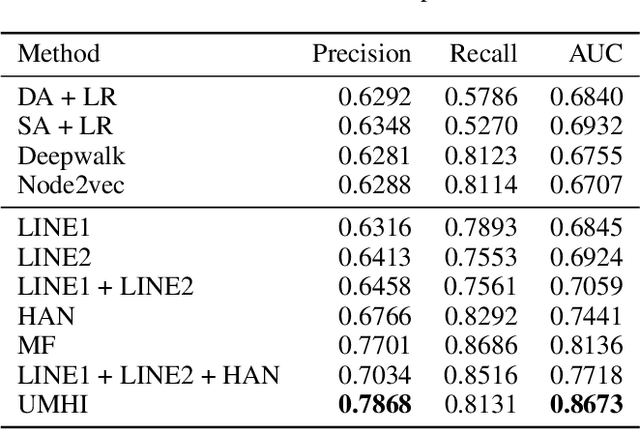
Online Social Networks (OSNs) evolve through two pervasive behaviors: follow and unfollow, which respectively signify relationship creation and relationship dissolution. Researches on social network evolution mainly focus on the follow behavior, while the unfollow behavior has largely been ignored. Mining unfollow behavior is challenging because user's decision on unfollow is not only affected by the simple combination of user's attributes like informativeness and reciprocity, but also affected by the complex interaction among them. Meanwhile, prior datasets seldom contain sufficient records for inferring such complex interaction. To address these issues, we first construct a large-scale real-world Weibo dataset, which records detailed post content and relationship dynamics of 1.8 million Chinese users. Next, we define user's attributes as two categories: spatial attributes (e.g., social role of user) and temporal attributes (e.g., post content of user). Leveraging the constructed dataset, we systematically study how the interaction effects between user's spatial and temporal attributes contribute to the unfollow behavior. Afterwards, we propose a novel unified model with heterogeneous information (UMHI) for unfollow prediction. Specifically, our UMHI model: 1) captures user's spatial attributes through social network structure; 2) infers user's temporal attributes through user-posted content and unfollow history; and 3) models the interaction between spatial and temporal attributes by the nonlinear MLP layers. Comprehensive evaluations on the constructed dataset demonstrate that the proposed UMHI model outperforms baseline methods by 16.44% on average in terms of precision. In addition, factor analyses verify that both spatial attributes and temporal attributes are essential for mining unfollow behavior.