 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant Skeleton-based Action Recognition via Global-Local Contrastive Learning
Sep 23, 2022
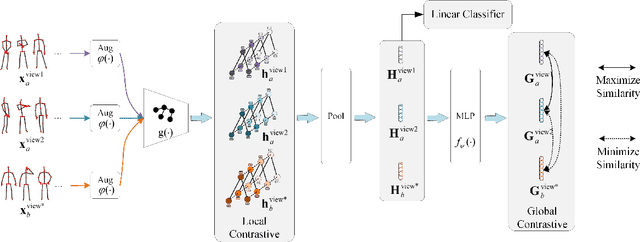
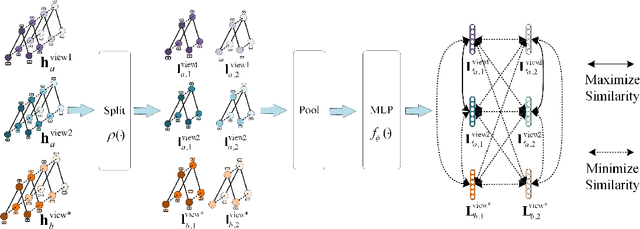
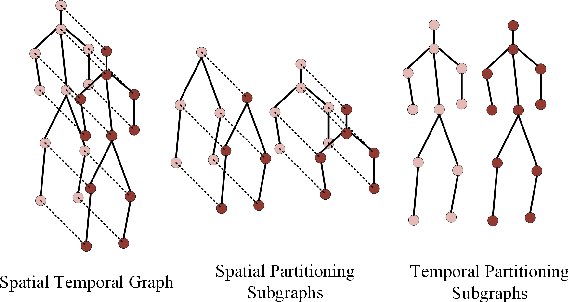
Skeleton-based human action recognition has been drawing more interest recently due to its low sensitivity to appearance changes and the accessibility of more skeleton data. However, even the 3D skeletons captured in practice are still sensitive to the viewpoint and direction gave the occlusion of different human-body joints and the errors in human joint localization. Such view variance of skeleton data may significantly affect the performance of action recognition. To address this issue, we propose in this paper a new view-invariant representation learning approach, without any manual action labeling, for skeleton-based human action recognition. Specifically, we leverage the multi-view skeleton data simultaneously taken for the same person in the network training, by maximizing the mutual information between the representations extracted from different views, and then propose a global-local contrastive loss to model the multi-scale co-occurrence relationships in both spatial and temporal domains. Extensive experimental results show that the proposed method is robust to the view difference of the input skeleton data and significantly boosts the performance of unsupervised skeleton-based human action methods, resulting in new state-of-the-art accuracies on two challenging multi-view benchmarks of PKUMMD and NTU RGB+D.
Improving Adversarial Waveform Generation based Singing Voice Conversion with Harmonic Signals
Jan 25, 2022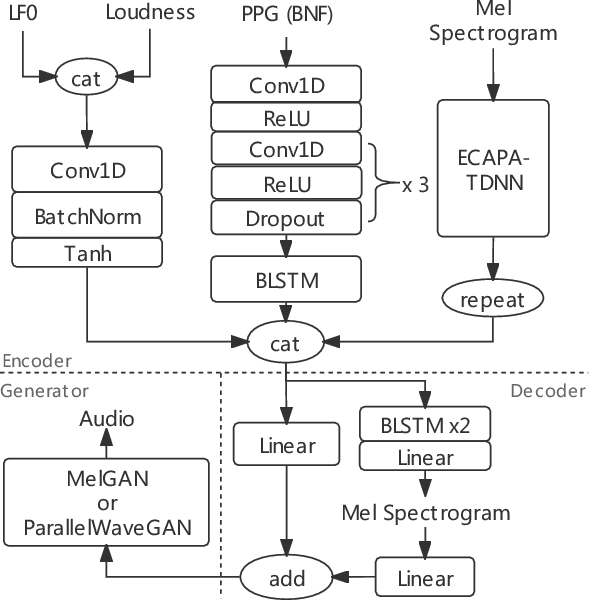
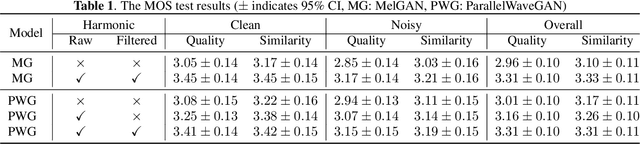
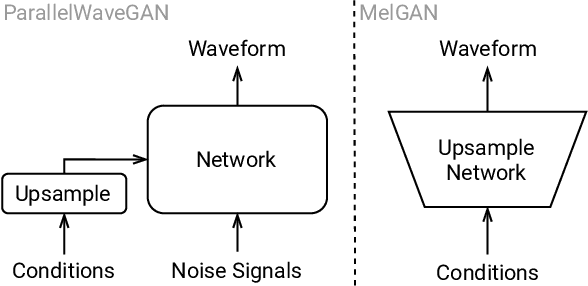
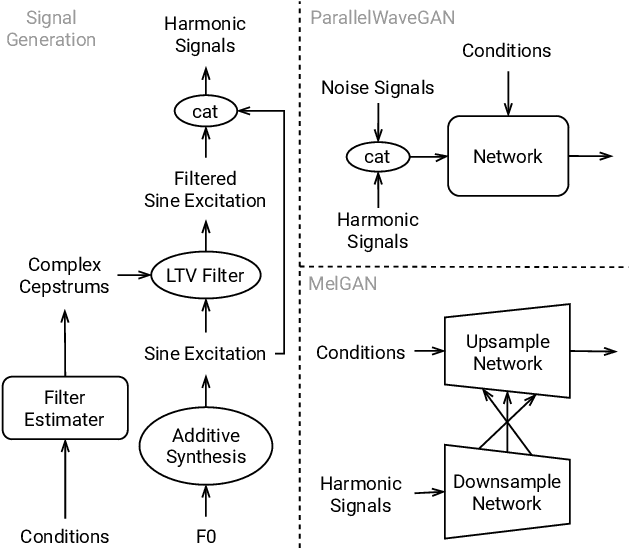
Adversarial waveform generation has been a popular approach as the backend of singing voice conversion (SVC) to generate high-quality singing audio. However, the instability of GAN also leads to other problems, such as pitch jitters and U/V errors. It affects the smoothness and continuity of harmonics, hence degrades the conversion quality seriously. This paper proposes to feed harmonic signals to the SVC model in advance to enhance audio generation. We extract the sine excitation from the pitch, and filter it with a linear time-varying (LTV) filter estimated by a neural network. Both these two harmonic signals are adopted as the inputs to generate the singing waveform. In our experiments, two mainstream models, MelGAN and ParallelWaveGAN, are investigated to validate the effectiveness of the proposed approach. We conduct a MOS test on clean and noisy test sets. The result shows that both signals significantly improve SVC in fidelity and timbre similarity. Besides, the case analysis further validates that this method enhances the smoothness and continuity of harmonics in the generated audio, and the filtered excitation better matches the target audio.
ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020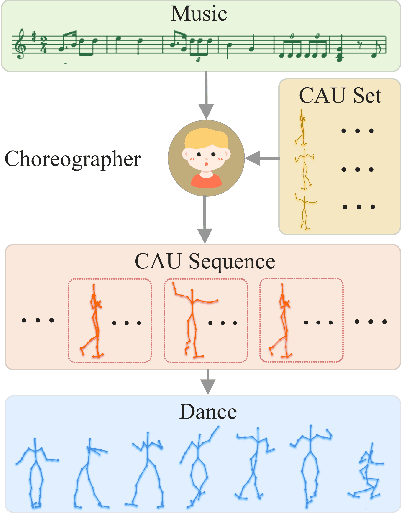

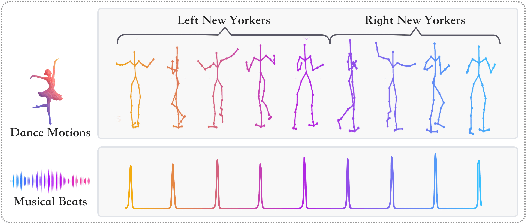
Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).