 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant Skeleton-based Action Recognition via Global-Local Contrastive Learning
Paper and Code
Sep 23, 2022
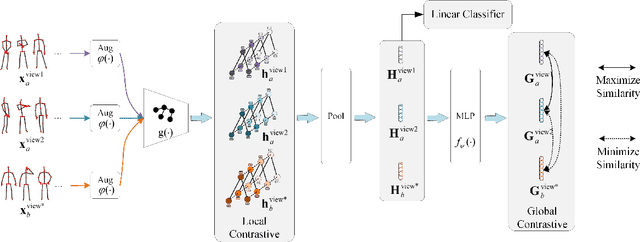
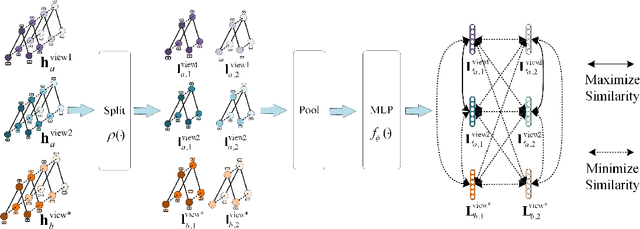
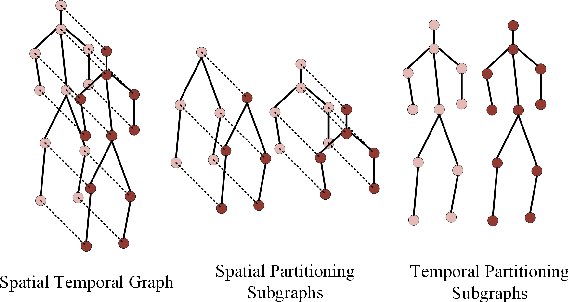
Skeleton-based human action recognition has been drawing more interest recently due to its low sensitivity to appearance changes and the accessibility of more skeleton data. However, even the 3D skeletons captured in practice are still sensitive to the viewpoint and direction gave the occlusion of different human-body joints and the errors in human joint localization. Such view variance of skeleton data may significantly affect the performance of action recognition. To address this issue, we propose in this paper a new view-invariant representation learning approach, without any manual action labeling, for skeleton-based human action recognition. Specifically, we leverage the multi-view skeleton data simultaneously taken for the same person in the network training, by maximizing the mutual information between the representations extracted from different views, and then propose a global-local contrastive loss to model the multi-scale co-occurrence relationships in both spatial and temporal domains. Extensive experimental results show that the proposed method is robust to the view difference of the input skeleton data and significantly boosts the performance of unsupervised skeleton-based human action methods, resulting in new state-of-the-art accuracies on two challenging multi-view benchmarks of PKUMMD and NTU RGB+D.