 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Secure Code Generation: A Dataset-driven Study on Vulnerability Mitigation
Oct 25, 2023



Large language models (LLMs) have brought significant advancements to code generation, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, introduces the risk of inadvertently propagating security vulnerabilities. To effectively mitigate this concern, this paper presents a comprehensive study focused on evaluating and enhancing code LLMs from a software security perspective. We introduce SecuCoGen\footnote{SecuCoGen has been uploaded as supplemental material and will be made publicly available after publication.}, a meticulously curated dataset targeting 21 critical vulnerability types. SecuCoGen comprises 180 samples and serves as the foundation for conducting experiments on three crucial code-related tasks: code generation, code repair and vulnerability classification, with a strong emphasis on security. Our experimental results reveal that existing models often overlook security concerns during code generation, leading to the generation of vulnerable code. To address this, we propose effective approaches to mitigate the security vulnerabilities and enhance the overall robustness of code generated by LLMs. Moreover, our study identifies weaknesses in existing models' ability to repair vulnerable code, even when provided with vulnerability information. Additionally, certain vulnerability types pose challenges for the models, hindering their performance in vulnerability classification. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Improving Adversarial Waveform Generation based Singing Voice Conversion with Harmonic Signals
Jan 25, 2022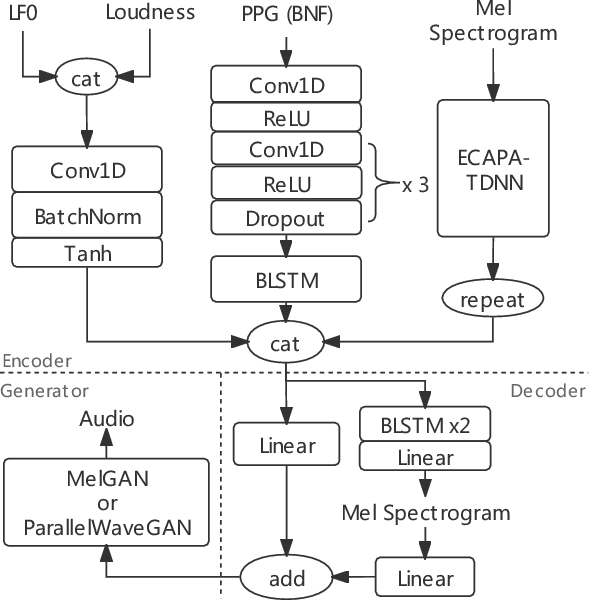
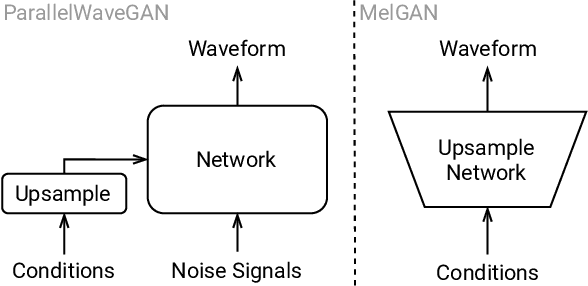
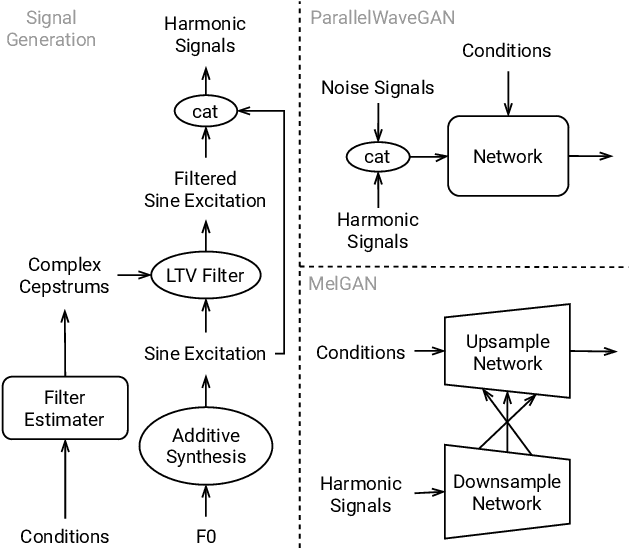
Adversarial waveform generation has been a popular approach as the backend of singing voice conversion (SVC) to generate high-quality singing audio. However, the instability of GAN also leads to other problems, such as pitch jitters and U/V errors. It affects the smoothness and continuity of harmonics, hence degrades the conversion quality seriously. This paper proposes to feed harmonic signals to the SVC model in advance to enhance audio generation. We extract the sine excitation from the pitch, and filter it with a linear time-varying (LTV) filter estimated by a neural network. Both these two harmonic signals are adopted as the inputs to generate the singing waveform. In our experiments, two mainstream models, MelGAN and ParallelWaveGAN, are investigated to validate the effectiveness of the proposed approach. We conduct a MOS test on clean and noisy test sets. The result shows that both signals significantly improve SVC in fidelity and timbre similarity. Besides, the case analysis further validates that this method enhances the smoothness and continuity of harmonics in the generated audio, and the filtered excitation better matches the target audio.