 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGE-MIL: Anchor-Guided Evidence Learning for Patient-Level Prediction
Jun 10, 2026Existing computational pathology methods predominantly operate within whole-slide image (WSI)-level multiple instance learning (MIL) paradigms, while patient-level modeling remains underexplored. In routine pathological practice, however, pathologists derive diagnostic and prognostic conclusions by integrating evidence across multiple WSIs rather than relying on any single slide. This discrepancy creates a fundamental misalignment when patient-level supervision is directly imposed on conventional MIL frameworks, often leading to unstable optimization and degraded predictive reliability. To address this issue, we propose Anchor-Guided Evidence MIL (AGE-MIL), a weakly supervised framework for patient-level prediction. AGE-MIL constructs a patient-level anchor from slide representations to capture global pathological context and guide the retrieval and integration of diagnostically relevant local patches, enabling robust patient-level modeling. Patient-level risk is further modeled as an evidence accumulation process, promoting stable optimization under weak supervision. AGE-MIL is evaluated on six clinically relevant patient-level prediction tasks from two independent cohorts. Experimental results show that the proposed framework consistently outperforms eight state-of-the-art MIL methods. Code is available at https://github.com/wodeniua/AGE-MIL.
SMADE-IE: Sparse Multi-Agent Framework with Evidence-Driven Debate for Zero-Shot Information Extraction
Jun 03, 2026Zero-shot information extraction (IE) with large language models (LLMs) has attracted increasing attention due to its flexibility in adapting to new schemas and domains without task-specific training. Existing approaches mainly rely on monolithic prompting, each-type prompting, or multi-agent debate. However, monolithic prompting often suffers from boundary and type errors, while each-type prompting and multi-agent debate introduce cross-type conflicts, redundant agent interactions, and substantial token overhead. To address these challenges, we propose SMADE-IE, a sparse and evidence-driven multi-agent framework for zero-shot IE. SMADE-IE first employs an Adaptive Mode Selector to dynamically route inputs into either a lightweight Global Extraction Mode or a Type-Centric Extraction Mode, reducing unnecessary type selection and reasoning noise. For conflicting predictions, we further introduce an Evidence-Driven Debate mechanism that structures arguments into Toulmin-style components and performs confidence aggregation through external evidence scoring and Bayesian updates. Experimental results on 9 benchmark datasets across NER, RE, and JERE tasks show that SMADE-IE consistently outperforms existing zero-shot IE baselines while also improving token efficiency through sparse agent selection and early-stopping debate.
Strat-Reasoner: Reinforcing Strategic Reasoning of LLMs in Multi-Agent Games
May 06, 2026While Large Language Models (LLMs) excel in certain reasoning tasks, they struggle in multi-agent games where the final outcome depends on the joint strategies of all agents. In multi-agent games, the non-stationarity of other agents brings significant challenges on the evaluation of the reasoning process and the credit assignment over multiple reasoning steps. Existing single-agent reinforcement learning (RL) approaches and their multi-agent extensions fail to address these challenges as they do not incorporate other agents in the reasoning process. In this work, we propose Strat-Reasoner, a novel RL-based framework that improves LLMs' strategic reasoning ability in multi-agent games. We introduce a novel recursive reasoning paradigm where an agent's reasoning also integrates other agents' reasoning processes. To provide effective reward signals for the intermediate reasoning sequences, we employ a centralized Chain-of-Thought (CoT) comparison module to evaluate the reasoning quality. Finally, we compute an accurate hybrid advantage and develop a group-relative RL approach to optimize the LLM policy. Experimental results show that Strat-Reasoner substantially improves strategic abilities of underlying LLMs, achieving 22.1\% average performance improvements across various multi-agent games.
An Unsupervised Normalizing Flow-Based Neyman-Pearson Detector for Covert Communications in the Presence of Disco Reconfigurable Intelligent Surfaces
Feb 10, 2026Covert communications, also known as low probability of detection (LPD) communications, offer a higher level of privacy protection compared to cryptography and physical-layer security (PLS) by hiding the transmission within ambient environments. Here, we investigate covert communications in the presence of a disco reconfigurable intelligent surface (DRIS) deployed by the warden Willie, which simultaneously reduces his detection error probabilities and degrades the communication performance between Alice and Bob, without relying on either channel state information (CSI) or additional jamming power. However, the introduction of the DRIS renders it intractable for Willie to construct a Neyman-Pearson (NP) detector, since the probability density function (PDF) of the test statistic is analytically intractable under the Alice-Bob transmission hypothesis. Moreover, given the adversarial relationship between Willie and Alice/Bob, it is unrealistic to assume that Willie has access to a labeled training dataset. To address these challenges, we propose an unsupervised masked autoregressive flow (MAF)-based NP detection framework that exploits prior knowledge inherent in covert communications. We further define the false alarm rate (FAR) and the missed detection rate (MDR) as monitoring performance metrics for Willie, and the signal-to-jamming-plus-noise ratio (SJNR) as a communication performance metric for Alice-Bob transmissions. Furthermore, we derive theoretical expressions for SJNR and uncover unique properties of covert communications in the presence of a DRIS. Simulations validate the theory and show that the proposed unsupervised MAF-based NP detector achieves performance comparable to its supervised counterpart.
Comparison of Single Carrier FTN-QAM and PCS-QAM for Amplifier-less Coherent Communication Systems
Jan 25, 2026A performance comparison of FTN-QAM and PCS-QAM for amplifier-less short-reach coherent communication systems is provided. With the applications of phase tracking partial response DFE and turbo equalization strategy, FTN-16QAM exhibits about 0.9dB power margin advantage over PCS-64QAM.
Rethinking Explanation Evaluation under the Retraining Scheme
Nov 11, 2025



Feature attribution has gained prominence as a tool for explaining model decisions, yet evaluating explanation quality remains challenging due to the absence of ground-truth explanations. To circumvent this, explanation-guided input manipulation has emerged as an indirect evaluation strategy, measuring explanation effectiveness through the impact of input modifications on model outcomes during inference. Despite the widespread use, a major concern with inference-based schemes is the distribution shift caused by such manipulations, which undermines the reliability of their assessments. The retraining-based scheme ROAR overcomes this issue by adapting the model to the altered data distribution. However, its evaluation results often contradict the theoretical foundations of widely accepted explainers. This work investigates this misalignment between empirical observations and theoretical expectations. In particular, we identify the sign issue as a key factor responsible for residual information that ultimately distorts retraining-based evaluation. Based on the analysis, we show that a straightforward reframing of the evaluation process can effectively resolve the identified issue. Building on the existing framework, we further propose novel variants that jointly structure a comprehensive perspective on explanation evaluation. These variants largely improve evaluation efficiency over the standard retraining protocol, thereby enhancing practical applicability for explainer selection and benchmarking. Following our proposed schemes, empirical results across various data scales provide deeper insights into the performance of carefully selected explainers, revealing open challenges and future directions in explainability research.
CADReview: Automatically Reviewing CAD Programs with Error Detection and Correction
May 28, 2025Computer-aided design (CAD) is crucial in prototyping 3D objects through geometric instructions (i.e., CAD programs). In practical design workflows, designers often engage in time-consuming reviews and refinements of these prototypes by comparing them with reference images. To bridge this gap, we introduce the CAD review task to automatically detect and correct potential errors, ensuring consistency between the constructed 3D objects and reference images. However, recent advanced multimodal large language models (MLLMs) struggle to recognize multiple geometric components and perform spatial geometric operations within the CAD program, leading to inaccurate reviews. In this paper, we propose the CAD program repairer (ReCAD) framework to effectively detect program errors and provide helpful feedback on error correction. Additionally, we create a dataset, CADReview, consisting of over 20K program-image pairs, with diverse errors for the CAD review task. Extensive experiments demonstrate that our ReCAD significantly outperforms existing MLLMs, which shows great potential in design applications.
Simultaneously Exposing and Jamming Covert Communications via Disco Reconfigurable Intelligent Surfaces
May 18, 2025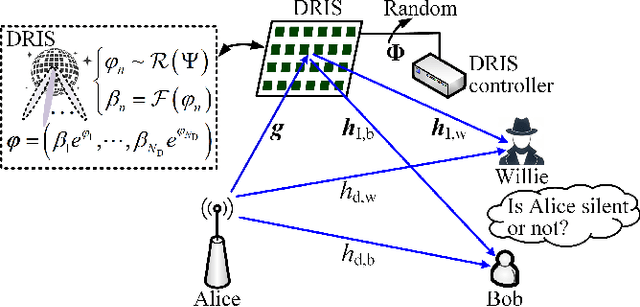
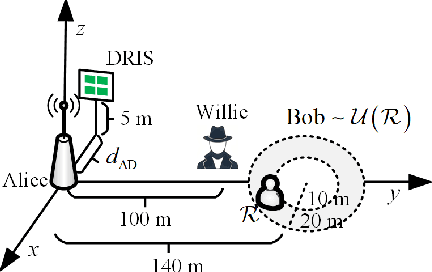
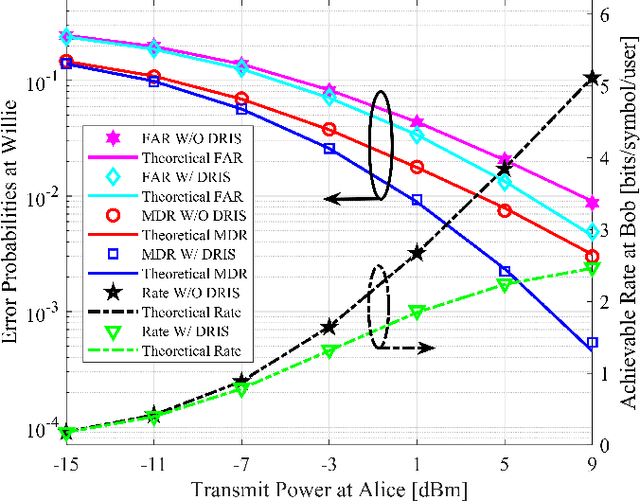
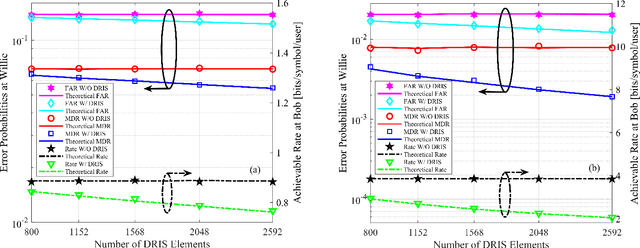
Covert communications provide a stronger privacy protection than cryptography and physical-layer security (PLS). However, previous works on covert communications have implicitly assumed the validity of channel reciprocity, i.e., wireless channels remain constant or approximately constant during their coherence time. In this work, we investigate covert communications in the presence of a disco RIS (DRIS) deployed by the warden Willie, where the DRIS with random and time-varying reflective coefficients acts as a "disco ball", introducing timevarying fully-passive jamming (FPJ). Consequently, the channel reciprocity assumption no longer holds. The DRIS not only jams the covert transmissions between Alice and Bob, but also decreases the error probabilities of Willie's detections, without either Bob's channel knowledge or additional jamming power. To quantify the impact of the DRIS on covert communications, we first design a detection rule for the warden Willie in the presence of time-varying FPJ introduced by the DRIS. Then, we define the detection error probabilities, i.e., the false alarm rate (FAR) and the missed detection rate (MDR), as the monitoring performance metrics for Willie's detections, and the signal-to-jamming-plusnoise ratio (SJNR) as a communication performance metric for the covert transmissions between Alice and Bob. Based on the detection rule, we derive the detection threshold for the warden Willie to detect whether communications between Alice and Bob is ongoing, considering the time-varying DRIS-based FPJ. Moreover, we conduct theoretical analyses of the FAR and the MDR at the warden Willie, as well as SJNR at Bob, and then present unique properties of the DRIS-based FPJ in covert communications. We present numerical results to validate the derived theoretical analyses and evaluate the impact of DRIS on covert communications.
Seeing Beyond the Scene: Enhancing Vision-Language Models with Interactional Reasoning
May 14, 2025Traditional scene graphs primarily focus on spatial relationships, limiting vision-language models' (VLMs) ability to reason about complex interactions in visual scenes. This paper addresses two key challenges: (1) conventional detection-to-construction methods produce unfocused, contextually irrelevant relationship sets, and (2) existing approaches fail to form persistent memories for generalizing interaction reasoning to new scenes. We propose Interaction-augmented Scene Graph Reasoning (ISGR), a framework that enhances VLMs' interactional reasoning through three complementary components. First, our dual-stream graph constructor combines SAM-powered spatial relation extraction with interaction-aware captioning to generate functionally salient scene graphs with spatial grounding. Second, we employ targeted interaction queries to activate VLMs' latent knowledge of object functionalities, converting passive recognition into active reasoning about how objects work together. Finally, we introduce a lone-term memory reinforcement learning strategy with a specialized interaction-focused reward function that transforms transient patterns into long-term reasoning heuristics. Extensive experiments demonstrate that our approach significantly outperforms baseline methods on interaction-heavy reasoning benchmarks, with particularly strong improvements on complex scene understanding tasks. The source code can be accessed at https://github.com/open_upon_acceptance.
A Reputation System for Large Language Model-based Multi-agent Systems to Avoid the Tragedy of the Commons
May 08, 2025The tragedy of the commons, where individual self-interest leads to collectively disastrous outcomes, is a pervasive challenge in human society. Recent studies have demonstrated that similar phenomena can arise in generative multi-agent systems (MASs). To address this challenge, this paper explores the use of reputation systems as a remedy. We propose RepuNet, a dynamic, dual-level reputation framework that models both agent-level reputation dynamics and system-level network evolution. Specifically, driven by direct interactions and indirect gossip, agents form reputations for both themselves and their peers, and decide whether to connect or disconnect other agents for future interactions. Through two distinct scenarios, we show that RepuNet effectively mitigates the 'tragedy of the commons', promoting and sustaining cooperation in generative MASs. Moreover, we find that reputation systems can give rise to rich emergent behaviors in generative MASs, such as the formation of cooperative clusters, the social isolation of exploitative agents, and the preference for sharing positive gossip rather than negative ones.