 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveyLens: A Research Discipline-Aware Benchmark for Automatic Survey Generation
Feb 11, 2026The exponential growth of scientific literature has driven the evolution of Automatic Survey Generation (ASG) from simple pipelines to multi-agent frameworks and commercial Deep Research agents. However, current ASG evaluation methods rely on generic metrics and are heavily biased toward Computer Science (CS), failing to assess whether ASG methods adhere to the distinct standards of various academic disciplines. Consequently, researchers, especially those outside CS, lack clear guidance on using ASG systems to yield high-quality surveys compliant with specific discipline standards. To bridge this gap, we introduce SurveyLens, the first discipline-aware benchmark evaluating ASG methods across diverse research disciplines. We construct SurveyLens-1k, a curated dataset of 1,000 high-quality human-written surveys spanning 10 disciplines. Subsequently, we propose a dual-lens evaluation framework: (1) Discipline-Aware Rubric Evaluation, which utilizes LLMs with human preference-aligned weights to assess adherence to domain-specific writing standards; and (2) Canonical Alignment Evaluation to rigorously measure content coverage and synthesis quality against human-written survey papers. We conduct extensive experiments by evaluating 11 state-of-the-art ASG methods on SurveyLens, including Vanilla LLMs, ASG systems, and Deep Research agents. Our analysis reveals the distinct strengths and weaknesses of each paradigm across fields, providing essential guidance for selecting tools tailored to specific disciplinary requirements.
Improved Masked Image Generation with Knowledge-Augmented Token Representations
Nov 15, 2025Masked image generation (MIG) has demonstrated remarkable efficiency and high-fidelity images by enabling parallel token prediction. Existing methods typically rely solely on the model itself to learn semantic dependencies among visual token sequences. However, directly learning such semantic dependencies from data is challenging because the individual tokens lack clear semantic meanings, and these sequences are usually long. To address this limitation, we propose a novel Knowledge-Augmented Masked Image Generation framework, named KA-MIG, which introduces explicit knowledge of token-level semantic dependencies (\emph{i.e.}, extracted from the training data) as priors to learn richer representations for improving performance. In particular, we explore and identify three types of advantageous token knowledge graphs, including two positive and one negative graphs (\emph{i.e.}, the co-occurrence graph, the semantic similarity graph, and the position-token incompatibility graph). Based on three prior knowledge graphs, we design a graph-aware encoder to learn token and position-aware representations. After that, a lightweight fusion mechanism is introduced to integrate these enriched representations into the existing MIG methods. Resorting to such prior knowledge, our method effectively enhances the model's ability to capture semantic dependencies, leading to improved generation quality. Experimental results demonstrate that our method improves upon existing MIG for class-conditional image generation on ImageNet.
Seeing Beyond the Scene: Enhancing Vision-Language Models with Interactional Reasoning
May 14, 2025Traditional scene graphs primarily focus on spatial relationships, limiting vision-language models' (VLMs) ability to reason about complex interactions in visual scenes. This paper addresses two key challenges: (1) conventional detection-to-construction methods produce unfocused, contextually irrelevant relationship sets, and (2) existing approaches fail to form persistent memories for generalizing interaction reasoning to new scenes. We propose Interaction-augmented Scene Graph Reasoning (ISGR), a framework that enhances VLMs' interactional reasoning through three complementary components. First, our dual-stream graph constructor combines SAM-powered spatial relation extraction with interaction-aware captioning to generate functionally salient scene graphs with spatial grounding. Second, we employ targeted interaction queries to activate VLMs' latent knowledge of object functionalities, converting passive recognition into active reasoning about how objects work together. Finally, we introduce a lone-term memory reinforcement learning strategy with a specialized interaction-focused reward function that transforms transient patterns into long-term reasoning heuristics. Extensive experiments demonstrate that our approach significantly outperforms baseline methods on interaction-heavy reasoning benchmarks, with particularly strong improvements on complex scene understanding tasks. The source code can be accessed at https://github.com/open_upon_acceptance.
Towards Improved Text-Aligned Codebook Learning: Multi-Hierarchical Codebook-Text Alignment with Long Text
Mar 03, 2025Image quantization is a crucial technique in image generation, aimed at learning a codebook that encodes an image into a discrete token sequence. Recent advancements have seen researchers exploring learning multi-modal codebook (i.e., text-aligned codebook) by utilizing image caption semantics, aiming to enhance codebook performance in cross-modal tasks. However, existing image-text paired datasets exhibit a notable flaw in that the text descriptions tend to be overly concise, failing to adequately describe the images and provide sufficient semantic knowledge, resulting in limited alignment of text and codebook at a fine-grained level. In this paper, we propose a novel Text-Augmented Codebook Learning framework, named TA-VQ, which generates longer text for each image using the visual-language model for improved text-aligned codebook learning. However, the long text presents two key challenges: how to encode text and how to align codebook and text. To tackle two challenges, we propose to split the long text into multiple granularities for encoding, i.e., word, phrase, and sentence, so that the long text can be fully encoded without losing any key semantic knowledge. Following this, a hierarchical encoder and novel sampling-based alignment strategy are designed to achieve fine-grained codebook-text alignment. Additionally, our method can be seamlessly integrated into existing VQ models. Extensive experiments in reconstruction and various downstream tasks demonstrate its effectiveness compared to previous state-of-the-art approaches.
Self-assessment, Exhibition, and Recognition: a Review of Personality in Large Language Models
Jun 25, 2024



As large language models (LLMs) appear to behave increasingly human-like in text-based interactions, more and more researchers become interested in investigating personality in LLMs. However, the diversity of psychological personality research and the rapid development of LLMs have led to a broad yet fragmented landscape of studies in this interdisciplinary field. Extensive studies across different research focuses, different personality psychometrics, and different LLMs make it challenging to have a holistic overview and further pose difficulties in applying findings to real-world applications. In this paper, we present a comprehensive review by categorizing current studies into three research problems: self-assessment, exhibition, and recognition, based on the intrinsic characteristics and external manifestations of personality in LLMs. For each problem, we provide a thorough analysis and conduct in-depth comparisons of their corresponding solutions. Besides, we summarize research findings and open challenges from current studies and further discuss their underlying causes. We also collect extensive publicly available resources to facilitate interested researchers and developers. Lastly, we discuss the potential future research directions and application scenarios. Our paper is the first comprehensive survey of up-to-date literature on personality in LLMs. By presenting a clear taxonomy, in-depth analysis, promising future directions, and extensive resource collections, we aim to provide a better understanding and facilitate further advancements in this emerging field.
Personality-affected Emotion Generation in Dialog Systems
Apr 03, 2024



Generating appropriate emotions for responses is essential for dialog systems to provide human-like interaction in various application scenarios. Most previous dialog systems tried to achieve this goal by learning empathetic manners from anonymous conversational data. However, emotional responses generated by those methods may be inconsistent, which will decrease user engagement and service quality. Psychological findings suggest that the emotional expressions of humans are rooted in personality traits. Therefore, we propose a new task, Personality-affected Emotion Generation, to generate emotion based on the personality given to the dialog system and further investigate a solution through the personality-affected mood transition. Specifically, we first construct a daily dialog dataset, Personality EmotionLines Dataset (PELD), with emotion and personality annotations. Subsequently, we analyze the challenges in this task, i.e., (1) heterogeneously integrating personality and emotional factors and (2) extracting multi-granularity emotional information in the dialog context. Finally, we propose to model the personality as the transition weight by simulating the mood transition process in the dialog system and solve the challenges above. We conduct extensive experiments on PELD for evaluation. Results suggest that by adopting our method, the emotion generation performance is improved by 13% in macro-F1 and 5% in weighted-F1 from the BERT-base model.
Affective-NLI: Towards Accurate and Interpretable Personality Recognition in Conversation
Apr 03, 2024



Personality Recognition in Conversation (PRC) aims to identify the personality traits of speakers through textual dialogue content. It is essential for providing personalized services in various applications of Human-Computer Interaction (HCI), such as AI-based mental therapy and companion robots for the elderly. Most recent studies analyze the dialog content for personality classification yet overlook two major concerns that hinder their performance. First, crucial implicit factors contained in conversation, such as emotions that reflect the speakers' personalities are ignored. Second, only focusing on the input dialog content disregards the semantic understanding of personality itself, which reduces the interpretability of the results. In this paper, we propose Affective Natural Language Inference (Affective-NLI) for accurate and interpretable PRC. To utilize affectivity within dialog content for accurate personality recognition, we fine-tuned a pre-trained language model specifically for emotion recognition in conversations, facilitating real-time affective annotations for utterances. For interpretability of recognition results, we formulate personality recognition as an NLI problem by determining whether the textual description of personality labels is entailed by the dialog content. Extensive experiments on two daily conversation datasets suggest that Affective-NLI significantly outperforms (by 6%-7%) state-of-the-art approaches. Additionally, our Flow experiment demonstrates that Affective-NLI can accurately recognize the speaker's personality in the early stages of conversations by surpassing state-of-the-art methods with 22%-34%.
Low-Resource Court Judgment Summarization for Common Law Systems
Mar 07, 2024



Common law courts need to refer to similar precedents' judgments to inform their current decisions. Generating high-quality summaries of court judgment documents can facilitate legal practitioners to efficiently review previous cases and assist the general public in accessing how the courts operate and how the law is applied. Previous court judgment summarization research focuses on civil law or a particular jurisdiction's judgments. However, judges can refer to the judgments from all common law jurisdictions. Current summarization datasets are insufficient to satisfy the demands of summarizing precedents across multiple jurisdictions, especially when labeled data are scarce for many jurisdictions. To address the lack of datasets, we present CLSum, the first dataset for summarizing multi-jurisdictional common law court judgment documents. Besides, this is the first court judgment summarization work adopting large language models (LLMs) in data augmentation, summary generation, and evaluation. Specifically, we design an LLM-based data augmentation method incorporating legal knowledge. We also propose a legal knowledge enhanced evaluation metric based on LLM to assess the quality of generated judgment summaries. Our experimental results verify that the LLM-based summarization methods can perform well in the few-shot and zero-shot settings. Our LLM-based data augmentation method can mitigate the impact of low data resources. Furthermore, we carry out comprehensive comparative experiments to find essential model components and settings that are capable of enhancing summarization performance.
Generating a Structured Summary of Numerous Academic Papers: Dataset and Method
Feb 09, 2023



Writing a survey paper on one research topic usually needs to cover the salient content from numerous related papers, which can be modeled as a multi-document summarization (MDS) task. Existing MDS datasets usually focus on producing the structureless summary covering a few input documents. Meanwhile, previous structured summary generation works focus on summarizing a single document into a multi-section summary. These existing datasets and methods cannot meet the requirements of summarizing numerous academic papers into a structured summary. To deal with the scarcity of available data, we propose BigSurvey, the first large-scale dataset for generating comprehensive summaries of numerous academic papers on each topic. We collect target summaries from more than seven thousand survey papers and utilize their 430 thousand reference papers' abstracts as input documents. To organize the diverse content from dozens of input documents and ensure the efficiency of processing long text sequences, we propose a summarization method named category-based alignment and sparse transformer (CAST). The experimental results show that our CAST method outperforms various advanced summarization methods.
Long Text and Multi-Table Summarization: Dataset and Method
Feb 08, 2023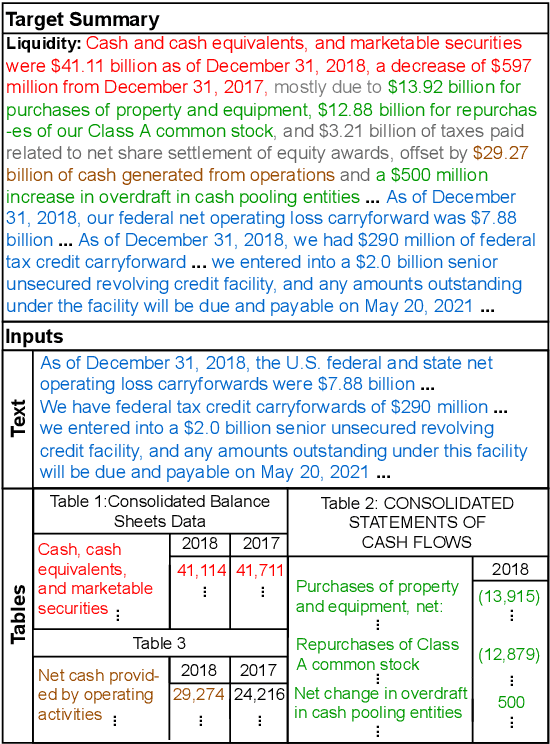
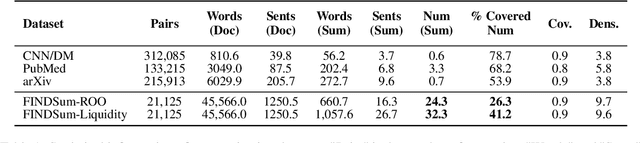
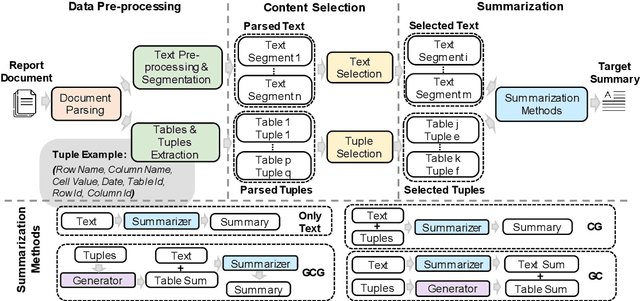
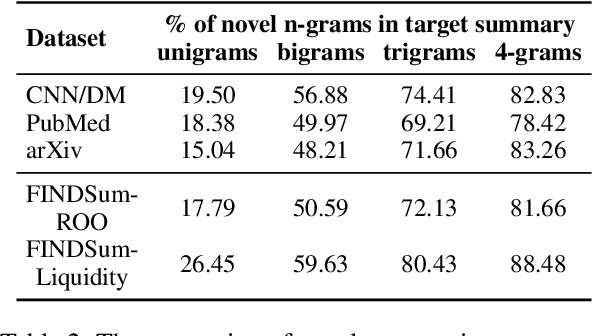
Automatic document summarization aims to produce a concise summary covering the input document's salient information. Within a report document, the salient information can be scattered in the textual and non-textual content. However, existing document summarization datasets and methods usually focus on the text and filter out the non-textual content. Missing tabular data can limit produced summaries' informativeness, especially when summaries require covering quantitative descriptions of critical metrics in tables. Existing datasets and methods cannot meet the requirements of summarizing long text and multiple tables in each report. To deal with the scarcity of available data, we propose FINDSum, the first large-scale dataset for long text and multi-table summarization. Built on 21,125 annual reports from 3,794 companies, it has two subsets for summarizing each company's results of operations and liquidity. To summarize the long text and dozens of tables in each report, we present three types of summarization methods. Besides, we propose a set of evaluation metrics to assess the usage of numerical information in produced summaries. Dataset analyses and experimental results indicate the importance of jointly considering input textual and tabular data when summarizing report documents.