 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Design of Metamaterials with Manufacturing-Guiding Spectrum-to-Structure Conditional Diffusion Model
Jun 08, 2025Metamaterials are artificially engineered structures that manipulate electromagnetic waves, having optical properties absent in natural materials. Recently, machine learning for the inverse design of metamaterials has drawn attention. However, the highly nonlinear relationship between the metamaterial structures and optical behaviour, coupled with fabrication difficulties, poses challenges for using machine learning to design and manufacture complex metamaterials. Herein, we propose a general framework that implements customised spectrum-to-shape and size parameters to address one-to-many metamaterial inverse design problems using conditional diffusion models. Our method exhibits superior spectral prediction accuracy, generates a diverse range of patterns compared to other typical generative models, and offers valuable prior knowledge for manufacturing through the subsequent analysis of the diverse generated results, thereby facilitating the experimental fabrication of metamaterial designs. We demonstrate the efficacy of the proposed method by successfully designing and fabricating a free-form metamaterial with a tailored selective emission spectrum for thermal camouflage applications.
FairTP: A Prolonged Fairness Framework for Traffic Prediction
Dec 18, 2024Traffic prediction plays a crucial role in intelligent transportation systems. Existing approaches primarily focus on improving overall accuracy, often neglecting a critical issue: whether predictive models lead to biased decisions by transportation authorities. In practice, the uneven deployment of traffic sensors across urban areas results in imbalanced data, causing prediction models to perform poorly in certain regions and leading to unfair decision-making. This imbalance ultimately harms the equity and quality of life for residents. Moreover, current fairness-aware machine learning models only ensure fairness at specific time points, failing to maintain fairness over extended periods. As traffic conditions change, such static fairness approaches become ineffective. To address this gap, we propose FairTP, a framework for prolonged fair traffic prediction. We introduce two new fairness definitions tailored for dynamic traffic scenarios. Fairness in traffic prediction is not static; it varies over time and across regions. Each sensor or urban area can alternate between two states: "sacrifice" (low prediction accuracy) and "benefit" (high prediction accuracy). Prolonged fairness is achieved when the overall states of sensors remain similar over a given period. We define two types of fairness: region-based static fairness and sensor-based dynamic fairness. To implement this, FairTP incorporates a state identification module to classify sensors' states as either "sacrifice" or "benefit," enabling prolonged fairness-aware predictions. Additionally, we introduce a state-guided balanced sampling strategy to further enhance fairness, addressing performance disparities among regions with uneven sensor distributions. Extensive experiments on two real-world datasets demonstrate that FairTP significantly improves prediction fairness while minimizing accuracy degradation.
ViDSOD-100: A New Dataset and a Baseline Model for RGB-D Video Salient Object Detection
Jun 18, 2024With the rapid development of depth sensor, more and more RGB-D videos could be obtained. Identifying the foreground in RGB-D videos is a fundamental and important task. However, the existing salient object detection (SOD) works only focus on either static RGB-D images or RGB videos, ignoring the collaborating of RGB-D and video information. In this paper, we first collect a new annotated RGB-D video SOD (ViDSOD-100) dataset, which contains 100 videos within a total of 9,362 frames, acquired from diverse natural scenes. All the frames in each video are manually annotated to a high-quality saliency annotation. Moreover, we propose a new baseline model, named attentive triple-fusion network (ATF-Net), for RGB-D video salient object detection. Our method aggregates the appearance information from an input RGB image, spatio-temporal information from an estimated motion map, and the geometry information from the depth map by devising three modality-specific branches and a multi-modality integration branch. The modality-specific branches extract the representation of different inputs, while the multi-modality integration branch combines the multi-level modality-specific features by introducing the encoder feature aggregation (MEA) modules and decoder feature aggregation (MDA) modules. The experimental findings conducted on both our newly introduced ViDSOD-100 dataset and the well-established DAVSOD dataset highlight the superior performance of the proposed ATF-Net. This performance enhancement is demonstrated both quantitatively and qualitatively, surpassing the capabilities of current state-of-the-art techniques across various domains, including RGB-D saliency detection, video saliency detection, and video object segmentation. Our data and our code are available at github.com/jhl-Det/RGBD_Video_SOD.
Personality-affected Emotion Generation in Dialog Systems
Apr 03, 2024



Generating appropriate emotions for responses is essential for dialog systems to provide human-like interaction in various application scenarios. Most previous dialog systems tried to achieve this goal by learning empathetic manners from anonymous conversational data. However, emotional responses generated by those methods may be inconsistent, which will decrease user engagement and service quality. Psychological findings suggest that the emotional expressions of humans are rooted in personality traits. Therefore, we propose a new task, Personality-affected Emotion Generation, to generate emotion based on the personality given to the dialog system and further investigate a solution through the personality-affected mood transition. Specifically, we first construct a daily dialog dataset, Personality EmotionLines Dataset (PELD), with emotion and personality annotations. Subsequently, we analyze the challenges in this task, i.e., (1) heterogeneously integrating personality and emotional factors and (2) extracting multi-granularity emotional information in the dialog context. Finally, we propose to model the personality as the transition weight by simulating the mood transition process in the dialog system and solve the challenges above. We conduct extensive experiments on PELD for evaluation. Results suggest that by adopting our method, the emotion generation performance is improved by 13% in macro-F1 and 5% in weighted-F1 from the BERT-base model.
Prompting Explicit and Implicit Knowledge for Multi-hop Question Answering Based on Human Reading Process
Mar 04, 2024Pre-trained language models (PLMs) leverage chains-of-thought (CoT) to simulate human reasoning and inference processes, achieving proficient performance in multi-hop QA. However, a gap persists between PLMs' reasoning abilities and those of humans when tackling complex problems. Psychological studies suggest a vital connection between explicit information in passages and human prior knowledge during reading. Nevertheless, current research has given insufficient attention to linking input passages and PLMs' pre-training-based knowledge from the perspective of human cognition studies. In this study, we introduce a Prompting Explicit and Implicit knowledge (PEI) framework, which uses prompts to connect explicit and implicit knowledge, aligning with human reading process for multi-hop QA. We consider the input passages as explicit knowledge, employing them to elicit implicit knowledge through unified prompt reasoning. Furthermore, our model incorporates type-specific reasoning via prompts, a form of implicit knowledge. Experimental results show that PEI performs comparably to the state-of-the-art on HotpotQA. Ablation studies confirm the efficacy of our model in bridging and integrating explicit and implicit knowledge.
Take Your Pick: Enabling Effective Personalized Federated Learning within Low-dimensional Feature Space
Jul 26, 2023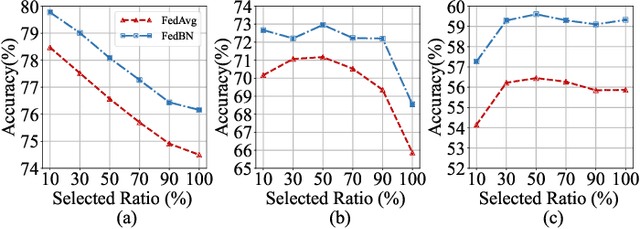

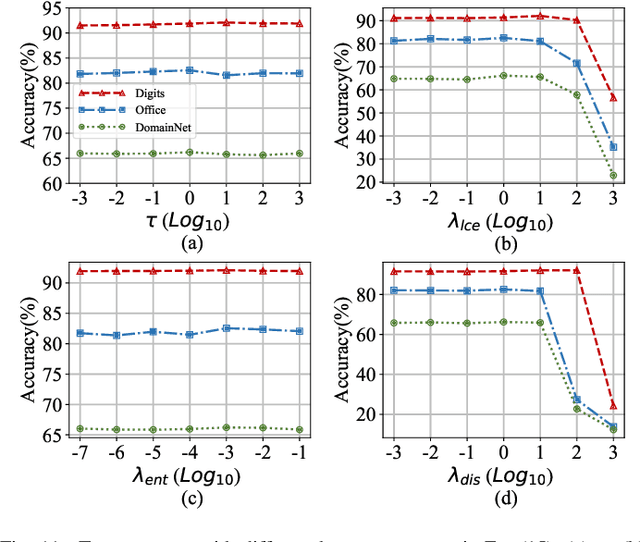
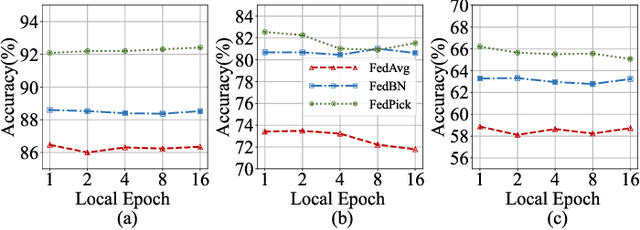
Personalized federated learning (PFL) is a popular framework that allows clients to have different models to address application scenarios where clients' data are in different domains. The typical model of a client in PFL features a global encoder trained by all clients to extract universal features from the raw data and personalized layers (e.g., a classifier) trained using the client's local data. Nonetheless, due to the differences between the data distributions of different clients (aka, domain gaps), the universal features produced by the global encoder largely encompass numerous components irrelevant to a certain client's local task. Some recent PFL methods address the above problem by personalizing specific parameters within the encoder. However, these methods encounter substantial challenges attributed to the high dimensionality and non-linearity of neural network parameter space. In contrast, the feature space exhibits a lower dimensionality, providing greater intuitiveness and interpretability as compared to the parameter space. To this end, we propose a novel PFL framework named FedPick. FedPick achieves PFL in the low-dimensional feature space by selecting task-relevant features adaptively for each client from the features generated by the global encoder based on its local data distribution. It presents a more accessible and interpretable implementation of PFL compared to those methods working in the parameter space. Extensive experimental results show that FedPick could effectively select task-relevant features for each client and improve model performance in cross-domain FL.
Unlocking the Potential of Federated Learning for Deeper Models
Jun 05, 2023Federated learning (FL) is a new paradigm for distributed machine learning that allows a global model to be trained across multiple clients without compromising their privacy. Although FL has demonstrated remarkable success in various scenarios, recent studies mainly utilize shallow and small neural networks. In our research, we discover a significant performance decline when applying the existing FL framework to deeper neural networks, even when client data are independently and identically distributed (i.i.d.). Our further investigation shows that the decline is due to the continuous accumulation of dissimilarities among client models during the layer-by-layer back-propagation process, which we refer to as "divergence accumulation." As deeper models involve a longer chain of divergence accumulation, they tend to manifest greater divergence, subsequently leading to performance decline. Both theoretical derivations and empirical evidence are proposed to support the existence of divergence accumulation and its amplified effects in deeper models. To address this issue, we propose several technical guidelines based on reducing divergence, such as using wider models and reducing the receptive field. These approaches can greatly improve the accuracy of FL on deeper models. For example, the application of these guidelines can boost the ResNet101 model's performance by as much as 43\% on the Tiny-ImageNet dataset.
EPARS: Early Prediction of At-risk Students with Online and Offline Learning Behaviors
Jun 06, 2020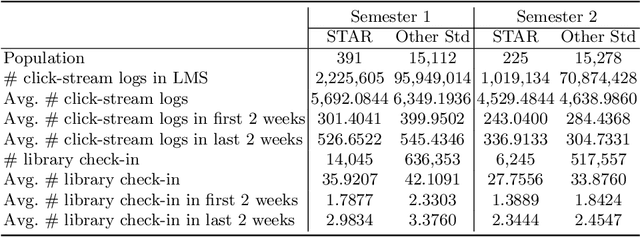
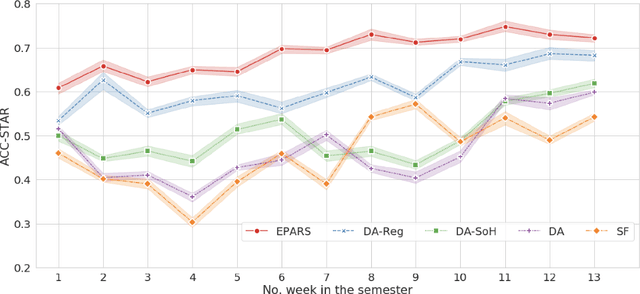
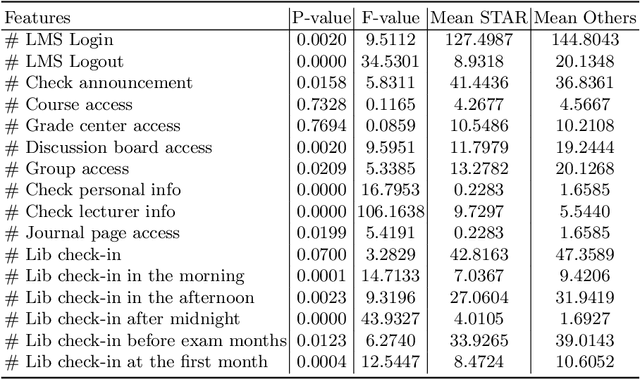
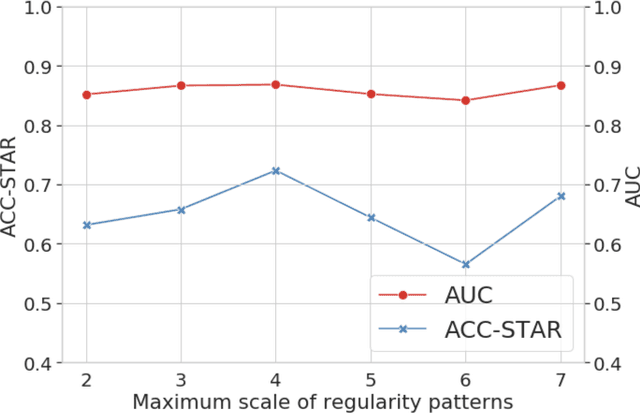
Early prediction of students at risk (STAR) is an effective and significant means to provide timely intervention for dropout and suicide. Existing works mostly rely on either online or offline learning behaviors which are not comprehensive enough to capture the whole learning processes and lead to unsatisfying prediction performance. We propose a novel algorithm (EPARS) that could early predict STAR in a semester by modeling online and offline learning behaviors. The online behaviors come from the log of activities when students use the online learning management system. The offline behaviors derive from the check-in records of the library. Our main observations are two folds. Significantly different from good students, STAR barely have regular and clear study routines. We devised a multi-scale bag-of-regularity method to extract the regularity of learning behaviors that is robust to sparse data. Second, friends of STAR are more likely to be at risk. We constructed a co-occurrence network to approximate the underlying social network and encode the social homophily as features through network embedding. To validate the proposed algorithm, extensive experiments have been conducted among an Asian university with 15,503 undergraduate students. The results indicate EPARS outperforms baselines by 14.62% ~ 38.22% in predicting STAR.