 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Strongest Teacher Is Not Always the Best Teacher: Student-Centric Answer Selection
May 26, 2026LLM training increasingly relies on teacher-generated supervision, from synthetic responses to reasoning traces and tool-use demonstrations. Current practice often chooses the highest-performing teacher to generate student training data, implicitly treating teacher test performance as a proxy for teaching quality. We show that this assumption can fail: even when multiple teachers provide correct answers to the same question, the answer from the strongest teacher is not necessarily the best supervision for a given student. To address this gap, we propose Student-Centric Answer Sampling (SCAS), a framework that selects from verified teacher-generated answers according to their estimated student-centric learning cost. Motivated by a token-wise gradient decomposition, we derive an efficient forward-only proxy for this cost and use it to guide answer selection during training. Experiments across 30 teacher models, 6 student base models, and 8 tasks show that SCAS consistently improves student performance, suggesting that effective distillation should prioritize supervision matched to the current student rather than teacher strength alone.
ViDSOD-100: A New Dataset and a Baseline Model for RGB-D Video Salient Object Detection
Jun 18, 2024With the rapid development of depth sensor, more and more RGB-D videos could be obtained. Identifying the foreground in RGB-D videos is a fundamental and important task. However, the existing salient object detection (SOD) works only focus on either static RGB-D images or RGB videos, ignoring the collaborating of RGB-D and video information. In this paper, we first collect a new annotated RGB-D video SOD (ViDSOD-100) dataset, which contains 100 videos within a total of 9,362 frames, acquired from diverse natural scenes. All the frames in each video are manually annotated to a high-quality saliency annotation. Moreover, we propose a new baseline model, named attentive triple-fusion network (ATF-Net), for RGB-D video salient object detection. Our method aggregates the appearance information from an input RGB image, spatio-temporal information from an estimated motion map, and the geometry information from the depth map by devising three modality-specific branches and a multi-modality integration branch. The modality-specific branches extract the representation of different inputs, while the multi-modality integration branch combines the multi-level modality-specific features by introducing the encoder feature aggregation (MEA) modules and decoder feature aggregation (MDA) modules. The experimental findings conducted on both our newly introduced ViDSOD-100 dataset and the well-established DAVSOD dataset highlight the superior performance of the proposed ATF-Net. This performance enhancement is demonstrated both quantitatively and qualitatively, surpassing the capabilities of current state-of-the-art techniques across various domains, including RGB-D saliency detection, video saliency detection, and video object segmentation. Our data and our code are available at github.com/jhl-Det/RGBD_Video_SOD.
On the price of exact truthfulness in incentive-compatible online learning with bandit feedback: A regret lower bound for WSU-UX
Apr 08, 2024In one view of the classical game of prediction with expert advice with binary outcomes, in each round, each expert maintains an adversarially chosen belief and honestly reports this belief. We consider a recently introduced, strategic variant of this problem with selfish (reputation-seeking) experts, where each expert strategically reports in order to maximize their expected future reputation based on their belief. In this work, our goal is to design an algorithm for the selfish experts problem that is incentive-compatible (IC, or \emph{truthful}), meaning each expert's best strategy is to report truthfully, while also ensuring the algorithm enjoys sublinear regret with respect to the expert with the best belief. Freeman et al. (2020) recently studied this problem in the full information and bandit settings and obtained truthful, no-regret algorithms by leveraging prior work on wagering mechanisms. While their results under full information match the minimax rate for the classical ("honest experts") problem, the best-known regret for their bandit algorithm WSU-UX is $O(T^{2/3})$, which does not match the minimax rate for the classical ("honest bandits") setting. It was unclear whether the higher regret was an artifact of their analysis or a limitation of WSU-UX. We show, via explicit construction of loss sequences, that the algorithm suffers a worst-case $\Omega(T^{2/3})$ lower bound. Left open is the possibility that a different IC algorithm obtains $O(\sqrt{T})$ regret. Yet, WSU-UX was a natural choice for such an algorithm owing to the limited design room for IC algorithms in this setting.
Shifting More Attention to Breast Lesion Segmentation in Ultrasound Videos
Oct 03, 2023Breast lesion segmentation in ultrasound (US) videos is essential for diagnosing and treating axillary lymph node metastasis. However, the lack of a well-established and large-scale ultrasound video dataset with high-quality annotations has posed a persistent challenge for the research community. To overcome this issue, we meticulously curated a US video breast lesion segmentation dataset comprising 572 videos and 34,300 annotated frames, covering a wide range of realistic clinical scenarios. Furthermore, we propose a novel frequency and localization feature aggregation network (FLA-Net) that learns temporal features from the frequency domain and predicts additional lesion location positions to assist with breast lesion segmentation. We also devise a localization-based contrastive loss to reduce the lesion location distance between neighboring video frames within the same video and enlarge the location distances between frames from different ultrasound videos. Our experiments on our annotated dataset and two public video polyp segmentation datasets demonstrate that our proposed FLA-Net achieves state-of-the-art performance in breast lesion segmentation in US videos and video polyp segmentation while significantly reducing time and space complexity. Our model and dataset are available at https://github.com/jhl-Det/FLA-Net.
A New Dataset and A Baseline Model for Breast Lesion Detection in Ultrasound Videos
Jul 01, 2022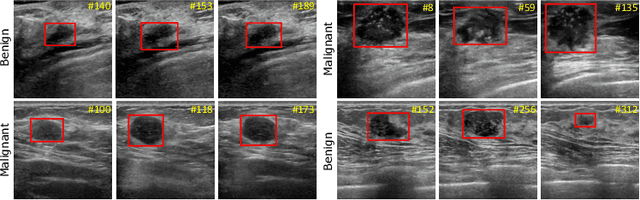
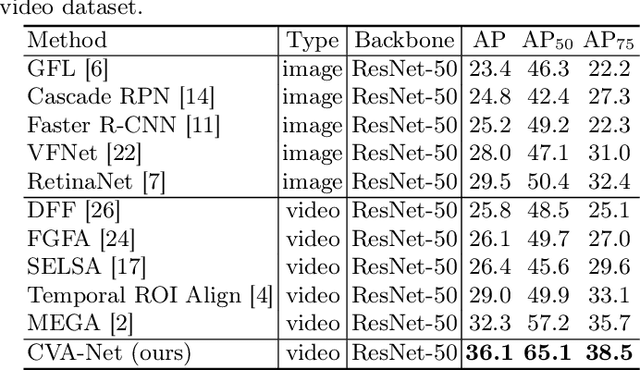
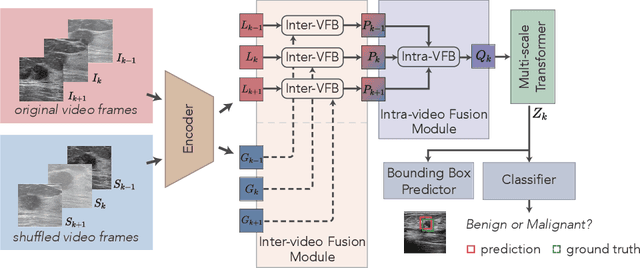
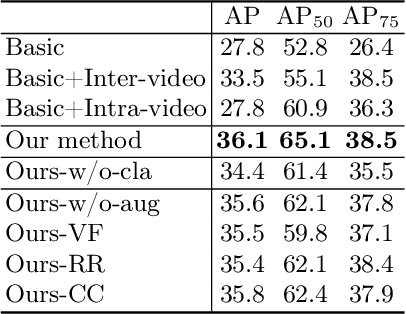
Breast lesion detection in ultrasound is critical for breast cancer diagnosis. Existing methods mainly rely on individual 2D ultrasound images or combine unlabeled video and labeled 2D images to train models for breast lesion detection. In this paper, we first collect and annotate an ultrasound video dataset (188 videos) for breast lesion detection. Moreover, we propose a clip-level and video-level feature aggregated network (CVA-Net) for addressing breast lesion detection in ultrasound videos by aggregating video-level lesion classification features and clip-level temporal features. The clip-level temporal features encode local temporal information of ordered video frames and global temporal information of shuffled video frames. In our CVA-Net, an inter-video fusion module is devised to fuse local features from original video frames and global features from shuffled video frames, and an intra-video fusion module is devised to learn the temporal information among adjacent video frames. Moreover, we learn video-level features to classify the breast lesions of the original video as benign or malignant lesions to further enhance the final breast lesion detection performance in ultrasound videos. Experimental results on our annotated dataset demonstrate that our CVA-Net clearly outperforms state-of-the-art methods. The corresponding code and dataset are publicly available at \url{https://github.com/jhl-Det/CVA-Net}.
* 11 pages, 4 figures