 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-IAP: Training-Free Visual Token Pruning via Interaction Alignment for Vision-Language-Action Models
Mar 24, 2026Vision-Language-Action (VLA) models have rapidly advanced embodied intelligence, enabling robots to execute complex, instruction-driven tasks. However, as model capacity and visual context length grow, the inference cost of VLA systems becomes a major bottleneck for real-world deployment on resource-constrained platforms. Existing visual token pruning methods mainly rely on semantic saliency or simple temporal cues, overlooking the continuous physical interaction, a fundamental property of VLA tasks. Consequently, current approaches often prune visually sparse yet structurally critical regions that support manipulation, leading to unstable behavior during early task phases. To overcome this, we propose a shift toward an explicit Interaction-First paradigm. Our proposed \textbf{training-free} method, VLA-IAP (Interaction-Aligned Pruning), introduces a geometric prior mechanism to preserve structural anchors and a dynamic scheduling strategy that adapts pruning intensity based on semantic-motion alignment. This enables a conservative-to-aggressive transition, ensuring robustness during early uncertainty and efficiency once interaction is locked. Extensive experiments show that VLA-IAP achieves a \textbf{97.8\% success rate} with a \textbf{$1.25\times$ speedup} on the LIBERO benchmark, and up to \textbf{$1.54\times$ speedup} while maintaining performance \textbf{comparable to the unpruned backbone}. Moreover, the method demonstrates superior and consistent performance across multiple model architectures and three different simulation environments, as well as a real robot platform, validating its strong generalization capability and practical applicability. Our project website is: \href{https://chengjt1999.github.io/VLA-IAP.github.io/}{VLA-IAP.com}.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Decoding Ambiguous Emotions with Test-Time Scaling in Audio-Language Models
Feb 01, 2026Emotion recognition from human speech is a critical enabler for socially aware conversational AI. However, while most prior work frames emotion recognition as a categorical classification problem, real-world affective states are often ambiguous, overlapping, and context-dependent, posing significant challenges for both annotation and automatic modeling. Recent large-scale audio language models (ALMs) offer new opportunities for nuanced affective reasoning without explicit emotion supervision, but their capacity to handle ambiguous emotions remains underexplored. At the same time, advances in inference-time techniques such as test-time scaling (TTS) have shown promise for improving generalization and adaptability in hard NLP tasks, but their relevance to affective computing is still largely unknown. In this work, we introduce the first benchmark for ambiguous emotion recognition in speech with ALMs under test-time scaling. Our evaluation systematically compares eight state-of-the-art ALMs and five TTS strategies across three prominent speech emotion datasets. We further provide an in-depth analysis of the interaction between model capacity, TTS, and affective ambiguity, offering new insights into the computational and representational challenges of ambiguous emotion understanding. Our benchmark establishes a foundation for developing more robust, context-aware, and emotionally intelligent speech-based AI systems, and highlights key future directions for bridging the gap between model assumptions and the complexity of real-world human emotion.
AutoHealth: An Uncertainty-Aware Multi-Agent System for Autonomous Health Data Modeling
Feb 01, 2026LLM-based agents have demonstrated strong potential for autonomous machine learning, yet their applicability to health data remains limited. Existing systems often struggle to generalize across heterogeneous health data modalities, rely heavily on predefined solution templates with insufficient adaptation to task-specific objectives, and largely overlook uncertainty estimation, which is essential for reliable decision-making in healthcare. To address these challenges, we propose \textit{AutoHealth}, a novel uncertainty-aware multi-agent system that autonomously models health data and assesses model reliability. \textit{AutoHealth} employs closed-loop coordination among five specialized agents to perform data exploration, task-conditioned model construction, training, and optimization, while jointly prioritizing predictive performance and uncertainty quantification. Beyond producing ready-to-use models, the system generates comprehensive reports to support trustworthy interpretation and risk-aware decision-making. To rigorously evaluate its effectiveness, we curate a challenging real-world benchmark comprising 17 tasks across diverse data modalities and learning settings. \textit{AutoHealth} completes all tasks and outperforms state-of-the-art baselines by 29.2\% in prediction performance and 50.2\% in uncertainty estimation.
Invariance on Manifolds: Understanding Robust Visual Representations for Place Recognition
Jan 31, 2026Visual Place Recognition (VPR) demands representations robust to drastic environmental and viewpoint shifts. Current aggregation paradigms, however, either rely on data-hungry supervision or simplistic first-order statistics, often neglecting intrinsic structural correlations. In this work, we propose a Second-Order Geometric Statistics framework that inherently captures geometric stability without training. We conceptualize scenes as covariance descriptors on the Symmetric Positive Definite (SPD) manifold, where perturbations manifest as tractable congruence transformations. By leveraging geometry-aware Riemannian mappings, we project these descriptors into a linearized Euclidean embedding, effectively decoupling signal structure from noise. Our approach introduces a training-free framework built upon fixed, pre-trained backbones, achieving strong zero-shot generalization without parameter updates. Extensive experiments confirm that our method achieves highly competitive performance against state-of-the-art baselines, particularly excelling in challenging zero-shot scenarios.
DI3CL: Contrastive Learning With Dynamic Instances and Contour Consistency for SAR Land-Cover Classification Foundation Model
Nov 12, 2025Although significant advances have been achieved in SAR land-cover classification, recent methods remain predominantly focused on supervised learning, which relies heavily on extensive labeled datasets. This dependency not only limits scalability and generalization but also restricts adaptability to diverse application scenarios. In this paper, a general-purpose foundation model for SAR land-cover classification is developed, serving as a robust cornerstone to accelerate the development and deployment of various downstream models. Specifically, a Dynamic Instance and Contour Consistency Contrastive Learning (DI3CL) pre-training framework is presented, which incorporates a Dynamic Instance (DI) module and a Contour Consistency (CC) module. DI module enhances global contextual awareness by enforcing local consistency across different views of the same region. CC module leverages shallow feature maps to guide the model to focus on the geometric contours of SAR land-cover objects, thereby improving structural discrimination. Additionally, to enhance robustness and generalization during pre-training, a large-scale and diverse dataset named SARSense, comprising 460,532 SAR images, is constructed to enable the model to capture comprehensive and representative features. To evaluate the generalization capability of our foundation model, we conducted extensive experiments across a variety of SAR land-cover classification tasks, including SAR land-cover mapping, water body detection, and road extraction. The results consistently demonstrate that the proposed DI3CL outperforms existing methods. Our code and pre-trained weights are publicly available at: https://github.com/SARpre-train/DI3CL.
MMCS: A Multimodal Medical Diagnosis System Integrating Image Analysis and Knowledge-based Departmental Consultation
Oct 20, 2024



We present MMCS, a system capable of recognizing medical images and patient facial details, and providing professional medical diagnoses. The system consists of two core components: The first component is the analysis of medical images and videos. We trained a specialized multimodal medical model capable of interpreting medical images and accurately analyzing patients' facial emotions and facial paralysis conditions. The model achieved an accuracy of 72.59% on the FER2013 facial emotion recognition dataset, with a 91.1% accuracy in recognizing the happy emotion. In facial paralysis recognition, the model reached an accuracy of 92%, which is 30% higher than that of GPT-4o. Based on this model, we developed a parser for analyzing facial movement videos of patients with facial paralysis, achieving precise grading of the paralysis severity. In tests on 30 videos of facial paralysis patients, the system demonstrated a grading accuracy of 83.3%.The second component is the generation of professional medical responses. We employed a large language model, integrated with a medical knowledge base, to generate professional diagnoses based on the analysis of medical images or videos. The core innovation lies in our development of a department-specific knowledge base routing management mechanism, in which the large language model categorizes data by medical departments and, during the retrieval process, determines the appropriate knowledge base to query. This significantly improves retrieval accuracy in the RAG (retrieval-augmented generation) process. This mechanism led to an average increase of 4 percentage points in accuracy for various large language models on the MedQA dataset.Our code is open-sourced and available at: https://github.com/renllll/MMCS.
Research on Predicting Public Opinion Event Heat Levels Based on Large Language Models
Sep 27, 2024
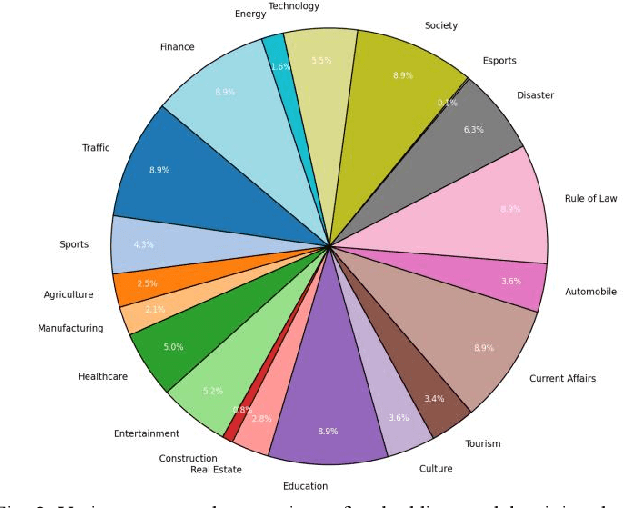
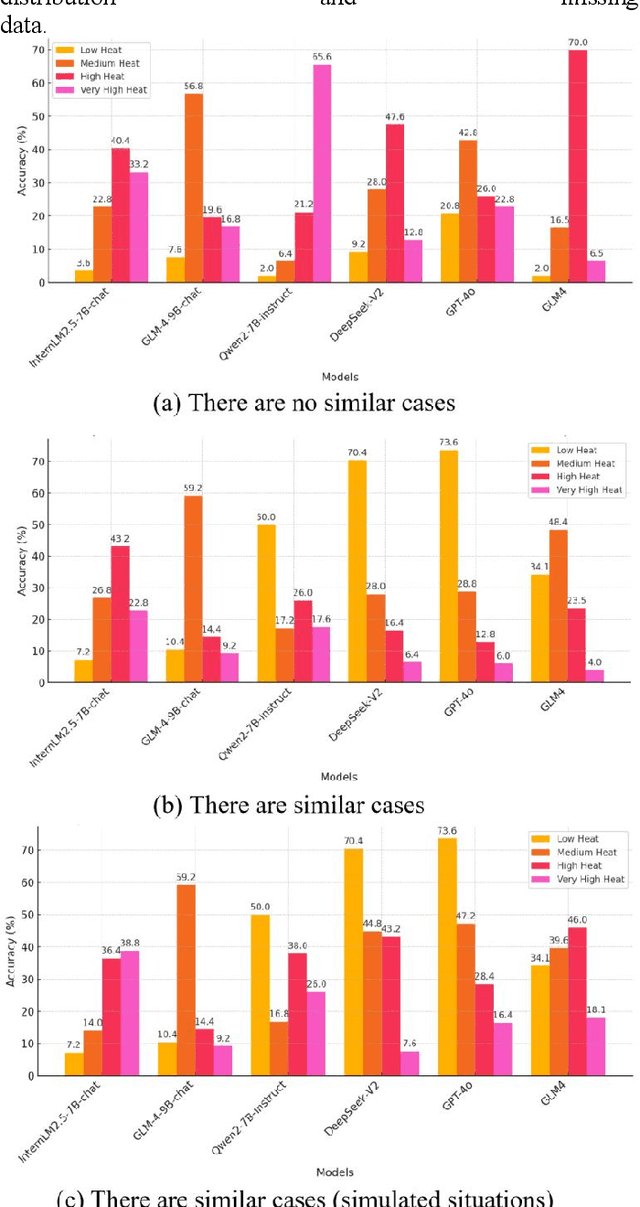

In recent years, with the rapid development of large language models, serval models such as GPT-4o have demonstrated extraordinary capabilities, surpassing human performance in various language tasks. As a result, many researchers have begun exploring their potential applications in the field of public opinion analysis. This study proposes a novel large-language-models-based method for public opinion event heat level prediction. First, we preprocessed and classified 62,836 Chinese hot event data collected between July 2022 and December 2023. Then, based on each event's online dissemination heat index, we used the MiniBatchKMeans algorithm to automatically cluster the events and categorize them into four heat levels (ranging from low heat to very high heat). Next, we randomly selected 250 events from each heat level, totalling 1,000 events, to build the evaluation dataset. During the evaluation process, we employed various large language models to assess their accuracy in predicting event heat levels in two scenarios: without reference cases and with similar case references. The results showed that GPT-4o and DeepseekV2 performed the best in the latter case, achieving prediction accuracies of 41.4% and 41.5%, respectively. Although the overall prediction accuracy remains relatively low, it is worth noting that for low-heat (Level 1) events, the prediction accuracies of these two models reached 73.6% and 70.4%, respectively. Additionally, the prediction accuracy showed a downward trend from Level 1 to Level 4, which correlates with the uneven distribution of data across the heat levels in the actual dataset. This suggests that with the more robust dataset, public opinion event heat level prediction based on large language models will have significant research potential for the future.
Shifting More Attention to Breast Lesion Segmentation in Ultrasound Videos
Oct 03, 2023Breast lesion segmentation in ultrasound (US) videos is essential for diagnosing and treating axillary lymph node metastasis. However, the lack of a well-established and large-scale ultrasound video dataset with high-quality annotations has posed a persistent challenge for the research community. To overcome this issue, we meticulously curated a US video breast lesion segmentation dataset comprising 572 videos and 34,300 annotated frames, covering a wide range of realistic clinical scenarios. Furthermore, we propose a novel frequency and localization feature aggregation network (FLA-Net) that learns temporal features from the frequency domain and predicts additional lesion location positions to assist with breast lesion segmentation. We also devise a localization-based contrastive loss to reduce the lesion location distance between neighboring video frames within the same video and enlarge the location distances between frames from different ultrasound videos. Our experiments on our annotated dataset and two public video polyp segmentation datasets demonstrate that our proposed FLA-Net achieves state-of-the-art performance in breast lesion segmentation in US videos and video polyp segmentation while significantly reducing time and space complexity. Our model and dataset are available at https://github.com/jhl-Det/FLA-Net.
Spectral Heterogeneous Graph Convolutions via Positive Noncommutative Polynomials
May 31, 2023



Heterogeneous Graph Neural Networks (HGNNs) have gained significant popularity in various heterogeneous graph learning tasks. However, most HGNNs rely on spatial domain-based message passing and attention modules for information propagation and aggregation. These spatial-based HGNNs neglect the utilization of spectral graph convolutions, which are the foundation of Graph Convolutional Networks (GCN) on homogeneous graphs. Inspired by the effectiveness and scalability of spectral-based GNNs on homogeneous graphs, this paper explores the extension of spectral-based GNNs to heterogeneous graphs. We propose PSHGCN, a novel heterogeneous convolutional network based on positive noncommutative polynomials. PSHGCN provides a simple yet effective approach for learning spectral graph convolutions on heterogeneous graphs. Moreover, we demonstrate the rationale of PSHGCN in graph optimization. We conducted an extensive experimental study to show that PSHGCN can learn diverse spectral heterogeneous graph convolutions and achieve superior performance in node classification tasks. Our code is available at https://github.com/ivam-he/PSHGCN.