 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Latent Attribute Interaction with Transformer on Heterogeneous Information Networks
Nov 06, 2023Heterogeneous graph neural networks (HGNNs) have recently shown impressive capability in modeling heterogeneous graphs that are ubiquitous in real-world applications. Due to the diversity of attributes of nodes in different types, most existing models first align nodes by mapping them into the same low-dimensional space. However, in this way, they lose the type information of nodes. In addition, most of them only consider the interactions between nodes while neglecting the high-order information behind the latent interactions among different node features. To address these problems, in this paper, we propose a novel heterogeneous graph model MULAN, including two major components, i.e., a type-aware encoder and a dimension-aware encoder. Specifically, the type-aware encoder compensates for the loss of node type information and better leverages graph heterogeneity in learning node representations. Built upon transformer architecture, the dimension-aware encoder is capable of capturing the latent interactions among the diverse node features. With these components, the information of graph heterogeneity, node features and graph structure can be comprehensively encoded in node representations. We conduct extensive experiments on six heterogeneous benchmark datasets, which demonstrates the superiority of MULAN over other state-of-the-art competitors and also shows that MULAN is efficient.
Enhancing Graph Neural Networks with Structure-Based Prompt
Oct 26, 2023Graph Neural Networks (GNNs) are powerful in learning semantics of graph data. Recently, a new paradigm "pre-train, prompt" has shown promising results in adapting GNNs to various tasks with less supervised data. The success of such paradigm can be attributed to the more consistent objectives of pre-training and task-oriented prompt tuning, where the pre-trained knowledge can be effectively transferred to downstream tasks. However, an overlooked issue of existing studies is that the structure information of graph is usually exploited during pre-training for learning node representations, while neglected in the prompt tuning stage for learning task-specific parameters. To bridge this gap, we propose a novel structure-based prompting method for GNNs, namely SAP, which consistently exploits structure information in both pre-training and prompt tuning stages. In particular, SAP 1) employs a dual-view contrastive learning to align the latent semantic spaces of node attributes and graph structure, and 2) incorporates structure information in prompted graph to elicit more pre-trained knowledge in prompt tuning. We conduct extensive experiments on node classification and graph classification tasks to show the effectiveness of SAP. Moreover, we show that SAP can lead to better performance in more challenging few-shot scenarios on both homophilous and heterophilous graphs.
Layout-aware Webpage Quality Assessment
Feb 05, 2023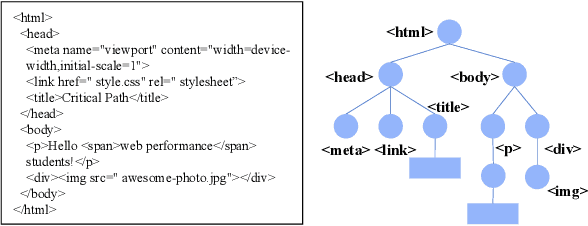

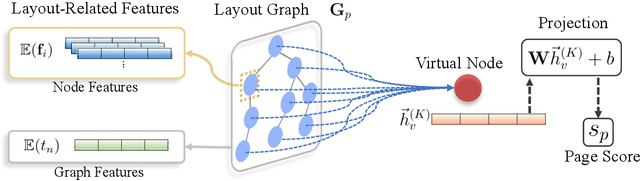
Identifying high-quality webpages is fundamental for real-world search engines, which can fulfil users' information need with the less cognitive burden. Early studies of \emph{webpage quality assessment} usually design hand-crafted features that may only work on particular categories of webpages (e.g., shopping websites, medical websites). They can hardly be applied to real-world search engines that serve trillions of webpages with various types and purposes. In this paper, we propose a novel layout-aware webpage quality assessment model currently deployed in our search engine. Intuitively, layout is a universal and critical dimension for the quality assessment of different categories of webpages. Based on this, we directly employ the meta-data that describes a webpage, i.e., Document Object Model (DOM) tree, as the input of our model. The DOM tree data unifies the representation of webpages with different categories and purposes and indicates the layout of webpages. To assess webpage quality from complex DOM tree data, we propose a graph neural network (GNN) based method that extracts rich layout-aware information that implies webpage quality in an end-to-end manner. Moreover, we improve the GNN method with an attentive readout function, external web categories and a category-aware sampling method. We conduct rigorous offline and online experiments to show that our proposed solution is effective in real search engines, improving the overall usability and user experience.
Geometry Contrastive Learning on Heterogeneous Graphs
Jun 25, 2022
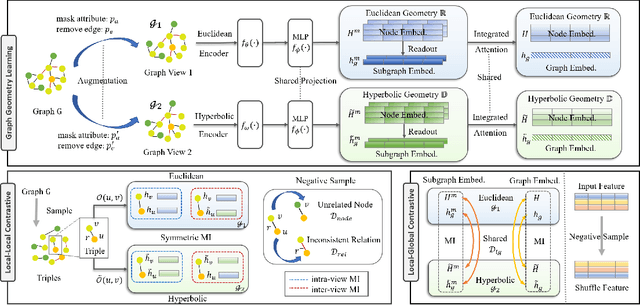

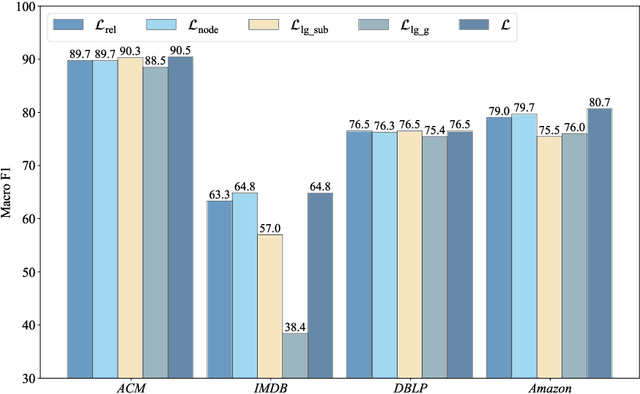
Self-supervised learning (especially contrastive learning) methods on heterogeneous graphs can effectively get rid of the dependence on supervisory data. Meanwhile, most existing representation learning methods embed the heterogeneous graphs into a single geometric space, either Euclidean or hyperbolic. This kind of single geometric view is usually not enough to observe the complete picture of heterogeneous graphs due to their rich semantics and complex structures. Under these observations, this paper proposes a novel self-supervised learning method, termed as Geometry Contrastive Learning (GCL), to better represent the heterogeneous graphs when supervisory data is unavailable. GCL views a heterogeneous graph from Euclidean and hyperbolic perspective simultaneously, aiming to make a strong merger of the ability of modeling rich semantics and complex structures, which is expected to bring in more benefits for downstream tasks. GCL maximizes the mutual information between two geometric views by contrasting representations at both local-local and local-global semantic levels. Extensive experiments on four benchmarks data sets show that the proposed approach outperforms the strong baselines, including both unsupervised methods and supervised methods, on three tasks, including node classification, node clustering and similarity search.
Deep Active Learning for Anchor User Prediction
Jun 25, 2019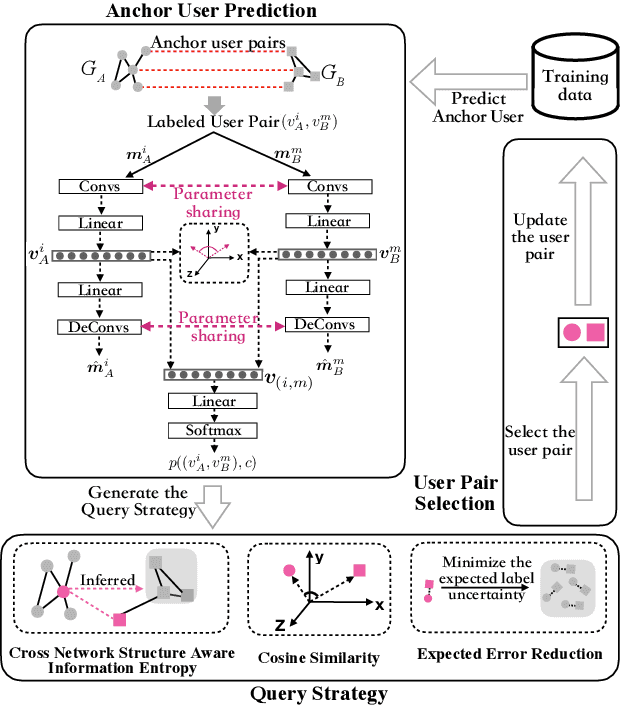
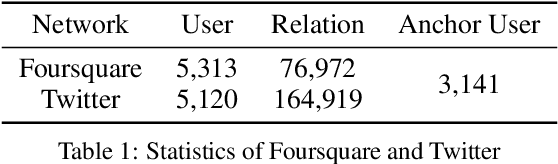
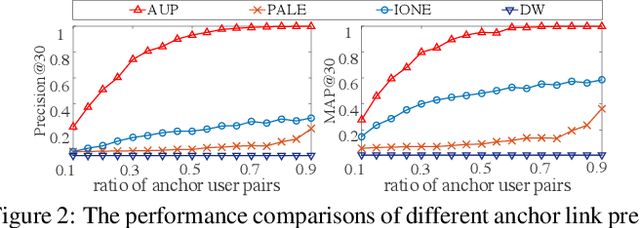
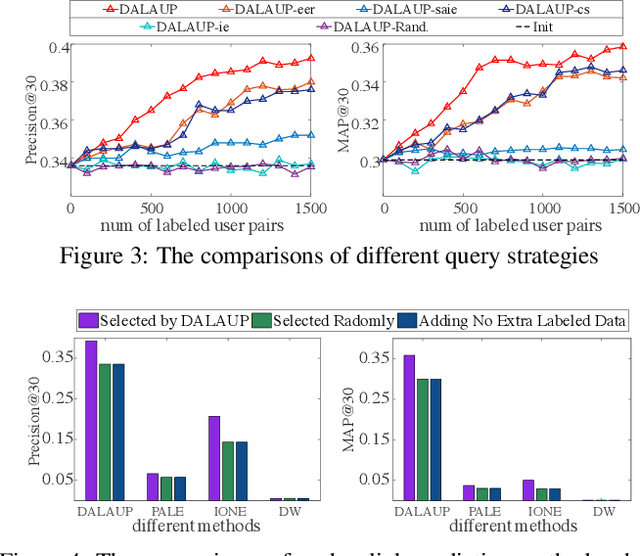
Predicting pairs of anchor users plays an important role in the cross-network analysis. Due to the expensive costs of labeling anchor users for training prediction models, we consider in this paper the problem of minimizing the number of user pairs across multiple networks for labeling as to improve the accuracy of the prediction. To this end, we present a deep active learning model for anchor user prediction (DALAUP for short). However, active learning for anchor user sampling meets the challenges of non-i.i.d. user pair data caused by network structures and the correlation among anchor or non-anchor user pairs. To solve the challenges, DALAUP uses a couple of neural networks with shared-parameter to obtain the vector representations of user pairs, and ensembles three query strategies to select the most informative user pairs for labeling and model training. Experiments on real-world social network data demonstrate that DALAUP outperforms the state-of-the-art approaches.