 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Context of Errors: Black-Box Online Adaptation of Time Series Foundation Models
Jun 12, 2026The rapid evolution of Time Series Foundation Models (TSFMs) has advanced zero-shot forecasting across diverse domains. Inspired by the current form of Large Language Models, future TSFMs may be offered as commercialized, closed-source API services. However, many existing online adaptation methods still rely on white-box access for parameter fine-tuning or gradient backpropagation. This paradigm mismatch raises a question: In black-box online adaptation for TSFMs, what should we learn? We answer this with an insight: the predictive errors of the base model are conditioned on both the input and output of the base model (i.e., the context of errors). To validate this insight, we propose ORCA (Online Residual Contextual Adaptation). We conduct extensive experiments across 5 state-of-the-art TSFMs and 8 datasets to demonstrate the effectiveness of our approach. Furthermore, through ablation studies, we quantitatively analyze the impact of different adapter learning hypotheses on the final adaptation performance in black-box online adaptation. Code available at https://github.com/Fifthky/ORCA.
Existence Precedes Value: Joint Modeling of Observational Existence and Evolving States in Time Series Forecasting
Jun 11, 2026Real-world time series are often highly incomplete and irregular due to sensor dormancy, transmission delays, and event-driven sampling, making reliable forecasting fundamentally challenging. Existing methods have evolved from impute-then-forecast pipelines to continuous-time models such as Neural ODEs and continuous-time graph networks. While these approaches improve the modeling of historical irregularity, they still rely on an implicit oracle assumption at inference time: the timestamps of future valid observations are presumed to be known in advance. This assumption limits practical relevance, since in many real systems the more fundamental question is not only what the future value will be, but also whether a valid observation will occur at all. In this paper, we propose Timeflies, a unified framework that reformulates forecasting as a joint problem of future observability inference and value estimation. To explicitly model the interaction between observation dynamics and state evolution, Timeflies adopts an observation stream and a value stream, coupled through three dedicated modules for reliability-aware embedding, observation-guided dependency modeling, and joint prediction. We further construct Shadow, a benchmark that combines natural missingness from public datasets with real-world industrial data, and introduce the Observation-Value Joint Entropy (OVJE) metric to comprehensively evaluate this coupled predictability. Extensive experiments show that Timeflies consistently outperforms existing methods, highlighting the importance of explicitly modeling future observability in time series forecasting with missing values. Code and dataset are available in https://github.com/ant-intl/Timeflies.
Falcon-X: A Time Series Foundation Model for Heterogeneous Multivariate Modeling
May 26, 2026Time series foundation models (TSFMs) are transforming the forecasting paradigm through large-scale cross-domain pretraining. However, most existing TSFMs remain univariate, and recent efforts to enable cross-variate modeling still operate directly within the raw variate space. This design introduces fundamental limitations in semantic alignment and relational expressivity. Specifically, raw-space group mixing lacks a dedicated mechanism to align heterogeneous physical quantities, while standard non-negative attention fails to capture the complex synergistic and antagonistic interactions ubiquitous in real-world systems. To address these challenges, we propose Falcon-X, decouples variates from the raw space and maps them into a unified latent prototype space. Falcon-X employs a Unified Prototype Diff-Attention mechanism that explicitly evaluates both positive and negative semantic affinities to explicitly align heterogeneous variates. Cross-variate interactions are then efficiently performed within this shared space via Latent Entity Attention, naturally facilitating zero-shot structural transfer. Finally, a Variate Reassembly Router robustly reconstructs variate-specific trajectories via a request-and-dispatch mechanism. Extensive evaluations on the GIFT-Eval and fev-bench benchmarks demonstrate that Falcon-X achieves state-of-the-art forecasting performance, offering a principled and scalable paradigm for complex multivariate environments. Falcon-X is publicly released to support future research.
MMSearch-R1: Incentivizing LMMs to Search
Jun 25, 2025



Robust deployment of large multimodal models (LMMs) in real-world scenarios requires access to external knowledge sources, given the complexity and dynamic nature of real-world information. Existing approaches such as retrieval-augmented generation (RAG) and prompt engineered search agents rely on rigid pipelines, often leading to inefficient or excessive search behaviors. We present MMSearch-R1, the first end-to-end reinforcement learning framework that enables LMMs to perform on-demand, multi-turn search in real-world Internet environments. Our framework integrates both image and text search tools, allowing the model to reason about when and how to invoke them guided by an outcome-based reward with a search penalty. To support training, We collect a multimodal search VQA dataset through a semi-automated pipeline that covers diverse visual and textual knowledge needs and curate a search-balanced subset with both search-required and search-free samples, which proves essential for shaping efficient and on-demand search behavior. Extensive experiments on knowledge-intensive and info-seeking VQA tasks show that our model not only outperforms RAG-based baselines of the same model size, but also matches the performance of a larger RAG-based model while reducing search calls by over 30%. We further analyze key empirical findings to offer actionable insights for advancing research in multimodal search.
Proactive Guidance of Multi-Turn Conversation in Industrial Search
May 30, 2025



The evolution of Large Language Models (LLMs) has significantly advanced multi-turn conversation systems, emphasizing the need for proactive guidance to enhance users' interactions. However, these systems face challenges in dynamically adapting to shifts in users' goals and maintaining low latency for real-time interactions. In the Baidu Search AI assistant, an industrial-scale multi-turn search system, we propose a novel two-phase framework to provide proactive guidance. The first phase, Goal-adaptive Supervised Fine-Tuning (G-SFT), employs a goal adaptation agent that dynamically adapts to user goal shifts and provides goal-relevant contextual information. G-SFT also incorporates scalable knowledge transfer to distill insights from LLMs into a lightweight model for real-time interaction. The second phase, Click-oriented Reinforcement Learning (C-RL), adopts a generate-rank paradigm, systematically constructs preference pairs from user click signals, and proactively improves click-through rates through more engaging guidance. This dual-phase architecture achieves complementary objectives: G-SFT ensures accurate goal tracking, while C-RL optimizes interaction quality through click signal-driven reinforcement learning. Extensive experiments demonstrate that our framework achieves 86.10% accuracy in offline evaluation (+23.95% over baseline) and 25.28% CTR in online deployment (149.06% relative improvement), while reducing inference latency by 69.55% through scalable knowledge distillation.
MAIR: A Massive Benchmark for Evaluating Instructed Retrieval
Oct 14, 2024



Recent information retrieval (IR) models are pre-trained and instruction-tuned on massive datasets and tasks, enabling them to perform well on a wide range of tasks and potentially generalize to unseen tasks with instructions. However, existing IR benchmarks focus on a limited scope of tasks, making them insufficient for evaluating the latest IR models. In this paper, we propose MAIR (Massive Instructed Retrieval Benchmark), a heterogeneous IR benchmark that includes 126 distinct IR tasks across 6 domains, collected from existing datasets. We benchmark state-of-the-art instruction-tuned text embedding models and re-ranking models. Our experiments reveal that instruction-tuned models generally achieve superior performance compared to non-instruction-tuned models on MAIR. Additionally, our results suggest that current instruction-tuned text embedding models and re-ranking models still lack effectiveness in specific long-tail tasks. MAIR is publicly available at https://github.com/sunnweiwei/Mair.
G3: An Effective and Adaptive Framework for Worldwide Geolocalization Using Large Multi-Modality Models
May 23, 2024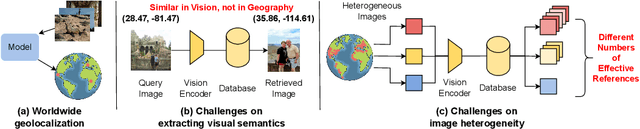


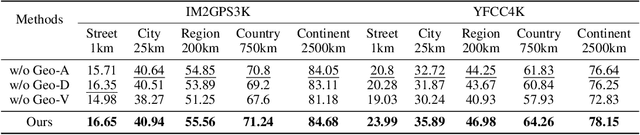
Worldwide geolocalization aims to locate the precise location at the coordinate level of photos taken anywhere on the Earth. It is very challenging due to 1) the difficulty of capturing subtle location-aware visual semantics, and 2) the heterogeneous geographical distribution of image data. As a result, existing studies have clear limitations when scaled to a worldwide context. They may easily confuse distant images with similar visual contents, or cannot adapt to various locations worldwide with different amounts of relevant data. To resolve these limitations, we propose G3, a novel framework based on Retrieval-Augmented Generation (RAG). In particular, G3 consists of three steps, i.e., Geo-alignment, Geo-diversification, and Geo-verification to optimize both retrieval and generation phases of worldwide geolocalization. During Geo-alignment, our solution jointly learns expressive multi-modal representations for images, GPS and textual descriptions, which allows us to capture location-aware semantics for retrieving nearby images for a given query. During Geo-diversification, we leverage a prompt ensembling method that is robust to inconsistent retrieval performance for different image queries. Finally, we combine both retrieved and generated GPS candidates in Geo-verification for location prediction. Experiments on two well-established datasets IM2GPS3k and YFCC4k verify the superiority of G3 compared to other state-of-the-art methods.
ChatASU: Evoking LLM's Reflexion to Truly Understand Aspect Sentiment in Dialogues
Mar 12, 2024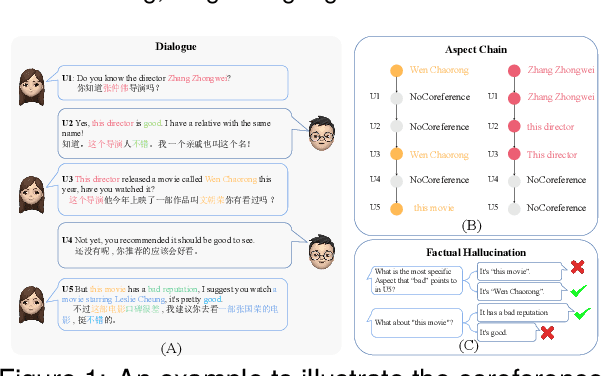
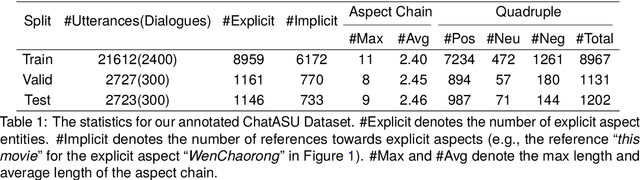
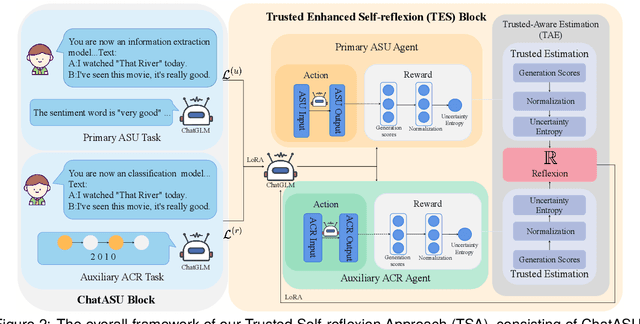

Aspect Sentiment Understanding (ASU) in interactive scenarios (e.g., Question-Answering and Dialogue) has attracted ever-more interest in recent years and achieved important progresses. However, existing studies on interactive ASU largely ignore the coreference issue for opinion targets (i.e., aspects), while this phenomenon is ubiquitous in interactive scenarios especially dialogues, limiting the ASU performance. Recently, large language models (LLMs) shows the powerful ability to integrate various NLP tasks with the chat paradigm. In this way, this paper proposes a new Chat-based Aspect Sentiment Understanding (ChatASU) task, aiming to explore LLMs' ability in understanding aspect sentiments in dialogue scenarios. Particularly, this ChatASU task introduces a sub-task, i.e., Aspect Chain Reasoning (ACR) task, to address the aspect coreference issue. On this basis, we propose a Trusted Self-reflexion Approach (TSA) with ChatGLM as backbone to ChatASU. Specifically, this TSA treats the ACR task as an auxiliary task to boost the performance of the primary ASU task, and further integrates trusted learning into reflexion mechanisms to alleviate the LLMs-intrinsic factual hallucination problem in TSA. Furthermore, a high-quality ChatASU dataset is annotated to evaluate TSA, and extensive experiments show that our proposed TSA can significantly outperform several state-of-the-art baselines, justifying the effectiveness of TSA to ChatASU and the importance of considering the coreference and hallucination issues in ChatASU.
The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation
Feb 23, 2024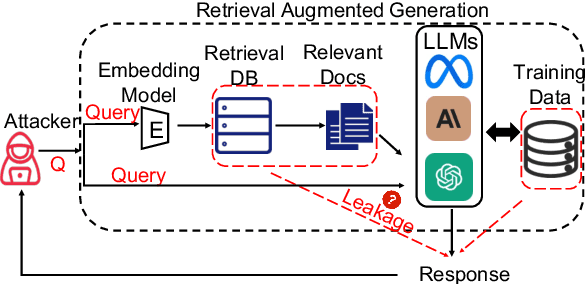
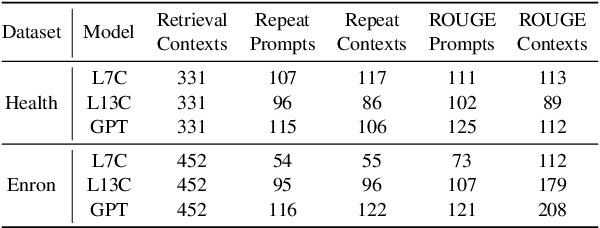
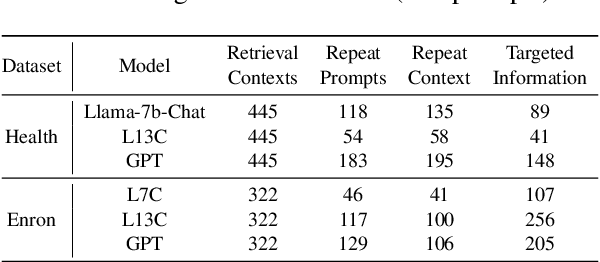
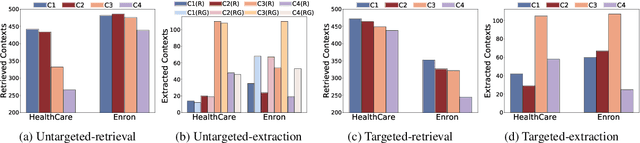
Retrieval-augmented generation (RAG) is a powerful technique to facilitate language model with proprietary and private data, where data privacy is a pivotal concern. Whereas extensive research has demonstrated the privacy risks of large language models (LLMs), the RAG technique could potentially reshape the inherent behaviors of LLM generation, posing new privacy issues that are currently under-explored. In this work, we conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. Despite the new risk brought by RAG on the retrieval data, we further reveal that RAG can mitigate the leakage of the LLMs' training data. Overall, we provide new insights in this paper for privacy protection of retrieval-augmented LLMs, which benefit both LLMs and RAG systems builders. Our code is available at https://github.com/phycholosogy/RAG-privacy.
Self-supervised Heterogeneous Graph Variational Autoencoders
Nov 14, 2023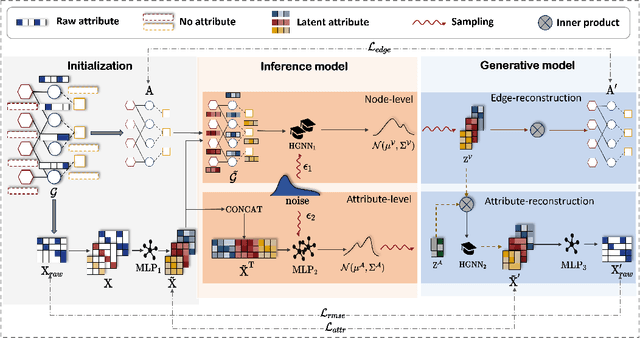
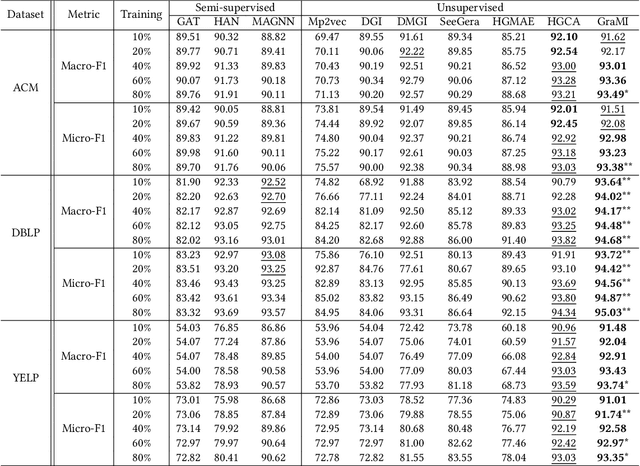
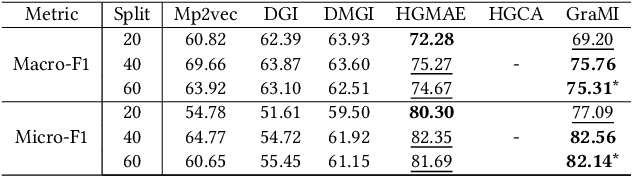
Heterogeneous Information Networks (HINs), which consist of various types of nodes and edges, have recently demonstrated excellent performance in graph mining. However, most existing heterogeneous graph neural networks (HGNNs) ignore the problems of missing attributes, inaccurate attributes and scarce labels for nodes, which limits their expressiveness. In this paper, we propose a generative self-supervised model SHAVA to address these issues simultaneously. Specifically, SHAVA first initializes all the nodes in the graph with a low-dimensional representation matrix. After that, based on the variational graph autoencoder framework, SHAVA learns both node-level and attribute-level embeddings in the encoder, which can provide fine-grained semantic information to construct node attributes. In the decoder, SHAVA reconstructs both links and attributes. Instead of directly reconstructing raw features for attributed nodes, SHAVA generates the initial low-dimensional representation matrix for all the nodes, based on which raw features of attributed nodes are further reconstructed to leverage accurate attributes. In this way, SHAVA can not only complete informative features for non-attributed nodes, but rectify inaccurate ones for attributed nodes. Finally, we conduct extensive experiments to show the superiority of SHAVA in tackling HINs with missing and inaccurate attributes.