 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Perturbation may Better Reflect the Uncertainty in LLM Reasoning
Feb 02, 2026Large language Models (LLMs) have achieved significant breakthroughs across diverse domains; however, they can still produce unreliable or misleading outputs. For responsible LLM application, Uncertainty Quantification (UQ) techniques are used to estimate a model's uncertainty about its outputs, indicating the likelihood that those outputs may be problematic. For LLM reasoning tasks, it is essential to estimate the uncertainty not only for the final answer, but also for the intermediate steps of the reasoning, as this can enable more fine-grained and targeted interventions. In this study, we explore what UQ metrics better reflect the LLM's ``intermediate uncertainty''during reasoning. Our study reveals that an LLMs' incorrect reasoning steps tend to contain tokens which are highly sensitive to the perturbations on the preceding token embeddings. In this way, incorrect (uncertain) intermediate steps can be readily identified using this sensitivity score as guidance in practice. In our experiments, we show such perturbation-based metric achieves stronger uncertainty quantification performance compared with baseline methods such as token (generation) probability and token entropy. Besides, different from approaches that rely on multiple sampling, the perturbation-based metrics offer better simplicity and efficiency.
Interpretable Probability Estimation with LLMs via Shapley Reconstruction
Jan 14, 2026Large Language Models (LLMs) demonstrate potential to estimate the probability of uncertain events, by leveraging their extensive knowledge and reasoning capabilities. This ability can be applied to support intelligent decision-making across diverse fields, such as financial forecasting and preventive healthcare. However, directly prompting LLMs for probability estimation faces significant challenges: their outputs are often noisy, and the underlying predicting process is opaque. In this paper, we propose PRISM: Probability Reconstruction via Shapley Measures, a framework that brings transparency and precision to LLM-based probability estimation. PRISM decomposes an LLM's prediction by quantifying the marginal contribution of each input factor using Shapley values. These factor-level contributions are then aggregated to reconstruct a calibrated final estimate. In our experiments, we demonstrate PRISM improves predictive accuracy over direct prompting and other baselines, across multiple domains including finance, healthcare, and agriculture. Beyond performance, PRISM provides a transparent prediction pipeline: our case studies visualize how individual factors shape the final estimate, helping build trust in LLM-based decision support systems.
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Aug 19, 2025We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
Towards Perfection: Building Inter-component Mutual Correction for Retinex-based Low-light Image Enhancement
Aug 12, 2025In low-light image enhancement, Retinex-based deep learning methods have garnered significant attention due to their exceptional interpretability. These methods decompose images into mutually independent illumination and reflectance components, allows each component to be enhanced separately. In fact, achieving perfect decomposition of illumination and reflectance components proves to be quite challenging, with some residuals still existing after decomposition. In this paper, we formally name these residuals as inter-component residuals (ICR), which has been largely underestimated by previous methods. In our investigation, ICR not only affects the accuracy of the decomposition but also causes enhanced components to deviate from the ideal outcome, ultimately reducing the final synthesized image quality. To address this issue, we propose a novel Inter-correction Retinex model (IRetinex) to alleviate ICR during the decomposition and enhancement stage. In the decomposition stage, we leverage inter-component residual reduction module to reduce the feature similarity between illumination and reflectance components. In the enhancement stage, we utilize the feature similarity between the two components to detect and mitigate the impact of ICR within each enhancement unit. Extensive experiments on three low-light benchmark datasets demonstrated that by reducing ICR, our method outperforms state-of-the-art approaches both qualitatively and quantitatively.
VideoFusion: A Spatio-Temporal Collaborative Network for Mutli-modal Video Fusion and Restoration
Mar 30, 2025Compared to images, videos better align with real-world acquisition scenarios and possess valuable temporal cues. However, existing multi-sensor fusion research predominantly integrates complementary context from multiple images rather than videos. This primarily stems from two factors: 1) the scarcity of large-scale multi-sensor video datasets, limiting research in video fusion, and 2) the inherent difficulty of jointly modeling spatial and temporal dependencies in a unified framework. This paper proactively compensates for the dilemmas. First, we construct M3SVD, a benchmark dataset with $220$ temporally synchronized and spatially registered infrared-visible video pairs comprising 153,797 frames, filling the data gap for the video fusion community. Secondly, we propose VideoFusion, a multi-modal video fusion model that fully exploits cross-modal complementarity and temporal dynamics to generate spatio-temporally coherent videos from (potentially degraded) multi-modal inputs. Specifically, 1) a differential reinforcement module is developed for cross-modal information interaction and enhancement, 2) a complete modality-guided fusion strategy is employed to adaptively integrate multi-modal features, and 3) a bi-temporal co-attention mechanism is devised to dynamically aggregate forward-backward temporal contexts to reinforce cross-frame feature representations. Extensive experiments reveal that VideoFusion outperforms existing image-oriented fusion paradigms in sequential scenarios, effectively mitigating temporal inconsistency and interference.
Multi-Faceted Studies on Data Poisoning can Advance LLM Development
Feb 20, 2025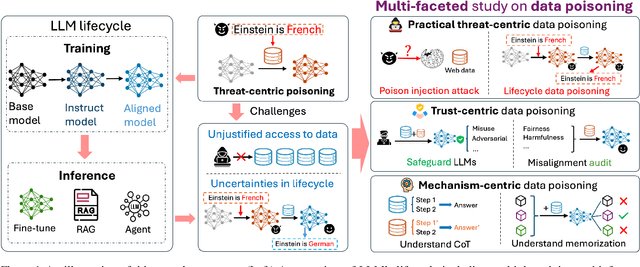
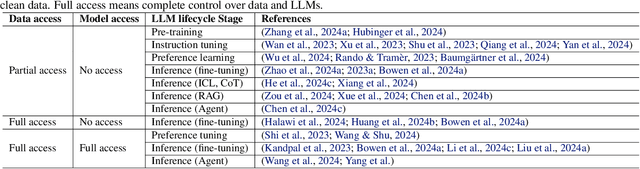
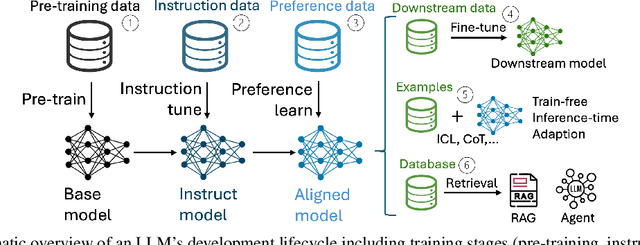
The lifecycle of large language models (LLMs) is far more complex than that of traditional machine learning models, involving multiple training stages, diverse data sources, and varied inference methods. While prior research on data poisoning attacks has primarily focused on the safety vulnerabilities of LLMs, these attacks face significant challenges in practice. Secure data collection, rigorous data cleaning, and the multistage nature of LLM training make it difficult to inject poisoned data or reliably influence LLM behavior as intended. Given these challenges, this position paper proposes rethinking the role of data poisoning and argue that multi-faceted studies on data poisoning can advance LLM development. From a threat perspective, practical strategies for data poisoning attacks can help evaluate and address real safety risks to LLMs. From a trustworthiness perspective, data poisoning can be leveraged to build more robust LLMs by uncovering and mitigating hidden biases, harmful outputs, and hallucinations. Moreover, from a mechanism perspective, data poisoning can provide valuable insights into LLMs, particularly the interplay between data and model behavior, driving a deeper understanding of their underlying mechanisms.
Deep Learning, Machine Learning, Advancing Big Data Analytics and Management
Dec 03, 2024



Advancements in artificial intelligence, machine learning, and deep learning have catalyzed the transformation of big data analytics and management into pivotal domains for research and application. This work explores the theoretical foundations, methodological advancements, and practical implementations of these technologies, emphasizing their role in uncovering actionable insights from massive, high-dimensional datasets. The study presents a systematic overview of data preprocessing techniques, including data cleaning, normalization, integration, and dimensionality reduction, to prepare raw data for analysis. Core analytics methodologies such as classification, clustering, regression, and anomaly detection are examined, with a focus on algorithmic innovation and scalability. Furthermore, the text delves into state-of-the-art frameworks for data mining and predictive modeling, highlighting the role of neural networks, support vector machines, and ensemble methods in tackling complex analytical challenges. Special emphasis is placed on the convergence of big data with distributed computing paradigms, including cloud and edge computing, to address challenges in storage, computation, and real-time analytics. The integration of ethical considerations, including data privacy and compliance with global standards, ensures a holistic perspective on data management. Practical applications across healthcare, finance, marketing, and policy-making illustrate the real-world impact of these technologies. Through comprehensive case studies and Python-based implementations, this work equips researchers, practitioners, and data enthusiasts with the tools to navigate the complexities of modern data analytics. It bridges the gap between theory and practice, fostering the development of innovative solutions for managing and leveraging data in the era of artificial intelligence.
A Comprehensive Guide to Explainable AI: From Classical Models to LLMs
Dec 01, 2024



Explainable Artificial Intelligence (XAI) addresses the growing need for transparency and interpretability in AI systems, enabling trust and accountability in decision-making processes. This book offers a comprehensive guide to XAI, bridging foundational concepts with advanced methodologies. It explores interpretability in traditional models such as Decision Trees, Linear Regression, and Support Vector Machines, alongside the challenges of explaining deep learning architectures like CNNs, RNNs, and Large Language Models (LLMs), including BERT, GPT, and T5. The book presents practical techniques such as SHAP, LIME, Grad-CAM, counterfactual explanations, and causal inference, supported by Python code examples for real-world applications. Case studies illustrate XAI's role in healthcare, finance, and policymaking, demonstrating its impact on fairness and decision support. The book also covers evaluation metrics for explanation quality, an overview of cutting-edge XAI tools and frameworks, and emerging research directions, such as interpretability in federated learning and ethical AI considerations. Designed for a broad audience, this resource equips readers with the theoretical insights and practical skills needed to master XAI. Hands-on examples and additional resources are available at the companion GitHub repository: https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.
Certified Robustness for Deep Equilibrium Models via Serialized Random Smoothing
Nov 01, 2024



Implicit models such as Deep Equilibrium Models (DEQs) have emerged as promising alternative approaches for building deep neural networks. Their certified robustness has gained increasing research attention due to security concerns. Existing certified defenses for DEQs employing deterministic certification methods such as interval bound propagation and Lipschitz-bounds can not certify on large-scale datasets. Besides, they are also restricted to specific forms of DEQs. In this paper, we provide the first randomized smoothing certified defense for DEQs to solve these limitations. Our study reveals that simply applying randomized smoothing to certify DEQs provides certified robustness generalized to large-scale datasets but incurs extremely expensive computation costs. To reduce computational redundancy, we propose a novel Serialized Randomized Smoothing (SRS) approach that leverages historical information. Additionally, we derive a new certified radius estimation for SRS to theoretically ensure the correctness of our algorithm. Extensive experiments and ablation studies on image recognition demonstrate that our algorithm can significantly accelerate the certification of DEQs by up to 7x almost without sacrificing the certified accuracy. Our code is available at https://github.com/WeizhiGao/Serialized-Randomized-Smoothing.