 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy GRPO Needs Normalization: A Local-Curvature Perspective on Adaptive Gradients
Jan 30, 2026Reinforcement learning (RL) has become a key driver of language model reasoning. Among RL algorithms, Group Relative Policy Optimization (GRPO) is the de facto standard, avoiding the need for a critic by using per-prompt baselines and variance normalization. Yet why and when this normalization helps remains unclear. In this work, we provide an explanation through the lens of local curvature of the sequence-level policy gradient: standard deviation normalization implements an adaptive gradient. Theoretically, under mild conditions, GRPO enjoys a strictly improved convergence rate over unnormalized REINFORCE, with gains characterized by the average within-prompt reward standard deviation across prompts and iterations. Empirically, our analysis on GSM8K and MATH benchmarks reveals three distinct training phases governed by the interplay between feature orthogonality and reward variance: (I) an early acceleration phase where high variance and orthogonality favor adaptive scaling; (II) a relatively stable transition phase; and (III) a late-stage regime where the loss of orthogonality limits further gains. Together, these results provide a principled account of when std normalization helps in GRPO, and offer broader insights into the design of critic-free RL algorithms.
From Aleatoric to Epistemic: Exploring Uncertainty Quantification Techniques in Artificial Intelligence
Jan 05, 2025



Uncertainty quantification (UQ) is a critical aspect of artificial intelligence (AI) systems, particularly in high-risk domains such as healthcare, autonomous systems, and financial technology, where decision-making processes must account for uncertainty. This review explores the evolution of uncertainty quantification techniques in AI, distinguishing between aleatoric and epistemic uncertainties, and discusses the mathematical foundations and methods used to quantify these uncertainties. We provide an overview of advanced techniques, including probabilistic methods, ensemble learning, sampling-based approaches, and generative models, while also highlighting hybrid approaches that integrate domain-specific knowledge. Furthermore, we examine the diverse applications of UQ across various fields, emphasizing its impact on decision-making, predictive accuracy, and system robustness. The review also addresses key challenges such as scalability, efficiency, and integration with explainable AI, and outlines future directions for research in this rapidly developing area. Through this comprehensive survey, we aim to provide a deeper understanding of UQ's role in enhancing the reliability, safety, and trustworthiness of AI systems.
Deep Learning, Machine Learning, Advancing Big Data Analytics and Management
Dec 03, 2024



Advancements in artificial intelligence, machine learning, and deep learning have catalyzed the transformation of big data analytics and management into pivotal domains for research and application. This work explores the theoretical foundations, methodological advancements, and practical implementations of these technologies, emphasizing their role in uncovering actionable insights from massive, high-dimensional datasets. The study presents a systematic overview of data preprocessing techniques, including data cleaning, normalization, integration, and dimensionality reduction, to prepare raw data for analysis. Core analytics methodologies such as classification, clustering, regression, and anomaly detection are examined, with a focus on algorithmic innovation and scalability. Furthermore, the text delves into state-of-the-art frameworks for data mining and predictive modeling, highlighting the role of neural networks, support vector machines, and ensemble methods in tackling complex analytical challenges. Special emphasis is placed on the convergence of big data with distributed computing paradigms, including cloud and edge computing, to address challenges in storage, computation, and real-time analytics. The integration of ethical considerations, including data privacy and compliance with global standards, ensures a holistic perspective on data management. Practical applications across healthcare, finance, marketing, and policy-making illustrate the real-world impact of these technologies. Through comprehensive case studies and Python-based implementations, this work equips researchers, practitioners, and data enthusiasts with the tools to navigate the complexities of modern data analytics. It bridges the gap between theory and practice, fostering the development of innovative solutions for managing and leveraging data in the era of artificial intelligence.
A Comprehensive Guide to Explainable AI: From Classical Models to LLMs
Dec 01, 2024



Explainable Artificial Intelligence (XAI) addresses the growing need for transparency and interpretability in AI systems, enabling trust and accountability in decision-making processes. This book offers a comprehensive guide to XAI, bridging foundational concepts with advanced methodologies. It explores interpretability in traditional models such as Decision Trees, Linear Regression, and Support Vector Machines, alongside the challenges of explaining deep learning architectures like CNNs, RNNs, and Large Language Models (LLMs), including BERT, GPT, and T5. The book presents practical techniques such as SHAP, LIME, Grad-CAM, counterfactual explanations, and causal inference, supported by Python code examples for real-world applications. Case studies illustrate XAI's role in healthcare, finance, and policymaking, demonstrating its impact on fairness and decision support. The book also covers evaluation metrics for explanation quality, an overview of cutting-edge XAI tools and frameworks, and emerging research directions, such as interpretability in federated learning and ethical AI considerations. Designed for a broad audience, this resource equips readers with the theoretical insights and practical skills needed to master XAI. Hands-on examples and additional resources are available at the companion GitHub repository: https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.
A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks
Nov 09, 2024



This survey and application guide to multimodal large language models(MLLMs) explores the rapidly developing field of MLLMs, examining their architectures, applications, and impact on AI and Generative Models. Starting with foundational concepts, we delve into how MLLMs integrate various data types, including text, images, video and audio, to enable complex AI systems for cross-modal understanding and generation. It covers essential topics such as training methods, architectural components, and practical applications in various fields, from visual storytelling to enhanced accessibility. Through detailed case studies and technical analysis, the text examines prominent MLLM implementations while addressing key challenges in scalability, robustness, and cross-modal learning. Concluding with a discussion of ethical considerations, responsible AI development, and future directions, this authoritative resource provides both theoretical frameworks and practical insights. It offers a balanced perspective on the opportunities and challenges in the development and deployment of MLLMs, and is highly valuable for researchers, practitioners, and students interested in the intersection of natural language processing and computer vision.
From Word Vectors to Multimodal Embeddings: Techniques, Applications, and Future Directions For Large Language Models
Nov 06, 2024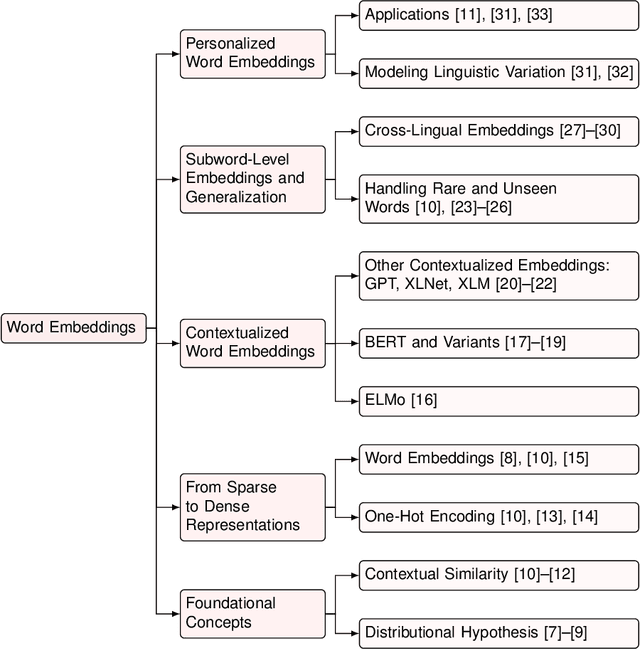


Word embeddings and language models have transformed natural language processing (NLP) by facilitating the representation of linguistic elements in continuous vector spaces. This review visits foundational concepts such as the distributional hypothesis and contextual similarity, tracing the evolution from sparse representations like one-hot encoding to dense embeddings including Word2Vec, GloVe, and fastText. We examine both static and contextualized embeddings, underscoring advancements in models such as ELMo, BERT, and GPT and their adaptations for cross-lingual and personalized applications. The discussion extends to sentence and document embeddings, covering aggregation methods and generative topic models, along with the application of embeddings in multimodal domains, including vision, robotics, and cognitive science. Advanced topics such as model compression, interpretability, numerical encoding, and bias mitigation are analyzed, addressing both technical challenges and ethical implications. Additionally, we identify future research directions, emphasizing the need for scalable training techniques, enhanced interpretability, and robust grounding in non-textual modalities. By synthesizing current methodologies and emerging trends, this survey offers researchers and practitioners an in-depth resource to push the boundaries of embedding-based language models.
Deep Learning and Machine Learning -- Natural Language Processing: From Theory to Application
Oct 30, 2024
With a focus on natural language processing (NLP) and the role of large language models (LLMs), we explore the intersection of machine learning, deep learning, and artificial intelligence. As artificial intelligence continues to revolutionize fields from healthcare to finance, NLP techniques such as tokenization, text classification, and entity recognition are essential for processing and understanding human language. This paper discusses advanced data preprocessing techniques and the use of frameworks like Hugging Face for implementing transformer-based models. Additionally, it highlights challenges such as handling multilingual data, reducing bias, and ensuring model robustness. By addressing key aspects of data processing and model fine-tuning, this work aims to provide insights into deploying effective and ethically sound AI solutions.
Large Language Model Benchmarks in Medical Tasks
Oct 28, 2024With the increasing application of large language models (LLMs) in the medical domain, evaluating these models' performance using benchmark datasets has become crucial. This paper presents a comprehensive survey of various benchmark datasets employed in medical LLM tasks. These datasets span multiple modalities including text, image, and multimodal benchmarks, focusing on different aspects of medical knowledge such as electronic health records (EHRs), doctor-patient dialogues, medical question-answering, and medical image captioning. The survey categorizes the datasets by modality, discussing their significance, data structure, and impact on the development of LLMs for clinical tasks such as diagnosis, report generation, and predictive decision support. Key benchmarks include MIMIC-III, MIMIC-IV, BioASQ, PubMedQA, and CheXpert, which have facilitated advancements in tasks like medical report generation, clinical summarization, and synthetic data generation. The paper summarizes the challenges and opportunities in leveraging these benchmarks for advancing multimodal medical intelligence, emphasizing the need for datasets with a greater degree of language diversity, structured omics data, and innovative approaches to synthesis. This work also provides a foundation for future research in the application of LLMs in medicine, contributing to the evolving field of medical artificial intelligence.
Deep Learning, Machine Learning -- Digital Signal and Image Processing: From Theory to Application
Oct 27, 2024Digital Signal Processing (DSP) and Digital Image Processing (DIP) with Machine Learning (ML) and Deep Learning (DL) are popular research areas in Computer Vision and related fields. We highlight transformative applications in image enhancement, filtering techniques, and pattern recognition. By integrating frameworks like the Discrete Fourier Transform (DFT), Z-Transform, and Fourier Transform methods, we enable robust data manipulation and feature extraction essential for AI-driven tasks. Using Python, we implement algorithms that optimize real-time data processing, forming a foundation for scalable, high-performance solutions in computer vision. This work illustrates the potential of ML and DL to advance DSP and DIP methodologies, contributing to artificial intelligence, automated feature extraction, and applications across diverse domains.
Deep Learning and Machine Learning -- Object Detection and Semantic Segmentation: From Theory to Applications
Oct 21, 2024This book offers an in-depth exploration of object detection and semantic segmentation, combining theoretical foundations with practical applications. It covers state-of-the-art advancements in machine learning and deep learning, with a focus on convolutional neural networks (CNNs), YOLO architectures, and transformer-based approaches like DETR. The book also delves into the integration of artificial intelligence (AI) techniques and large language models for enhanced object detection in complex environments. A thorough discussion of big data analysis is presented, highlighting the importance of data processing, model optimization, and performance evaluation metrics. By bridging the gap between traditional methods and modern deep learning frameworks, this book serves as a comprehensive guide for researchers, data scientists, and engineers aiming to leverage AI-driven methodologies in large-scale object detection tasks.