 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJMedEthicBench: A Multi-Turn Conversational Benchmark for Evaluating Medical Safety in Japanese Large Language Models
Jan 04, 2026As Large Language Models (LLMs) are increasingly deployed in healthcare field, it becomes essential to carefully evaluate their medical safety before clinical use. However, existing safety benchmarks remain predominantly English-centric, and test with only single-turn prompts despite multi-turn clinical consultations. To address these gaps, we introduce JMedEthicBench, the first multi-turn conversational benchmark for evaluating medical safety of LLMs for Japanese healthcare. Our benchmark is based on 67 guidelines from the Japan Medical Association and contains over 50,000 adversarial conversations generated using seven automatically discovered jailbreak strategies. Using a dual-LLM scoring protocol, we evaluate 27 models and find that commercial models maintain robust safety while medical-specialized models exhibit increased vulnerability. Furthermore, safety scores decline significantly across conversation turns (median: 9.5 to 5.0, $p < 0.001$). Cross-lingual evaluation on both Japanese and English versions of our benchmark reveals that medical model vulnerabilities persist across languages, indicating inherent alignment limitations rather than language-specific factors. These findings suggest that domain-specific fine-tuning may accidentally weaken safety mechanisms and that multi-turn interactions represent a distinct threat surface requiring dedicated alignment strategies.
Feature Alignment and Representation Transfer in Knowledge Distillation for Large Language Models
Apr 18, 2025Knowledge distillation (KD) is a technique for transferring knowledge from complex teacher models to simpler student models, significantly enhancing model efficiency and accuracy. It has demonstrated substantial advancements in various applications including image classification, object detection, language modeling, text classification, and sentiment analysis. Recent innovations in KD methods, such as attention-based approaches, block-wise logit distillation, and decoupling distillation, have notably improved student model performance. These techniques focus on stimulus complexity, attention mechanisms, and global information capture to optimize knowledge transfer. In addition, KD has proven effective in compressing large language models while preserving accuracy, reducing computational overhead, and improving inference speed. This survey synthesizes the latest literature, highlighting key findings, contributions, and future directions in knowledge distillation to provide insights for researchers and practitioners on its evolving role in artificial intelligence and machine learning.
Generative Adversarial Networks Bridging Art and Machine Intelligence
Feb 09, 2025



Generative Adversarial Networks (GAN) have greatly influenced the development of computer vision and artificial intelligence in the past decade and also connected art and machine intelligence together. This book begins with a detailed introduction to the fundamental principles and historical development of GANs, contrasting them with traditional generative models and elucidating the core adversarial mechanisms through illustrative Python examples. The text systematically addresses the mathematical and theoretical underpinnings including probability theory, statistics, and game theory providing a solid framework for understanding the objectives, loss functions, and optimisation challenges inherent to GAN training. Subsequent chapters review classic variants such as Conditional GANs, DCGANs, InfoGAN, and LAPGAN before progressing to advanced training methodologies like Wasserstein GANs, GANs with gradient penalty, least squares GANs, and spectral normalisation techniques. The book further examines architectural enhancements and task-specific adaptations in generators and discriminators, showcasing practical implementations in high resolution image generation, artistic style transfer, video synthesis, text to image generation and other multimedia applications. The concluding sections offer insights into emerging research trends, including self-attention mechanisms, transformer-based generative models, and a comparative analysis with diffusion models, thus charting promising directions for future developments in both academic and applied settings.
From Aleatoric to Epistemic: Exploring Uncertainty Quantification Techniques in Artificial Intelligence
Jan 05, 2025



Uncertainty quantification (UQ) is a critical aspect of artificial intelligence (AI) systems, particularly in high-risk domains such as healthcare, autonomous systems, and financial technology, where decision-making processes must account for uncertainty. This review explores the evolution of uncertainty quantification techniques in AI, distinguishing between aleatoric and epistemic uncertainties, and discusses the mathematical foundations and methods used to quantify these uncertainties. We provide an overview of advanced techniques, including probabilistic methods, ensemble learning, sampling-based approaches, and generative models, while also highlighting hybrid approaches that integrate domain-specific knowledge. Furthermore, we examine the diverse applications of UQ across various fields, emphasizing its impact on decision-making, predictive accuracy, and system robustness. The review also addresses key challenges such as scalability, efficiency, and integration with explainable AI, and outlines future directions for research in this rapidly developing area. Through this comprehensive survey, we aim to provide a deeper understanding of UQ's role in enhancing the reliability, safety, and trustworthiness of AI systems.
From Bench to Bedside: A Review of Clinical Trialsin Drug Discovery and Development
Dec 12, 2024Clinical trials are an indispensable part of the drug development process, bridging the gap between basic research and clinical application. During the development of new drugs, clinical trials are used not only to evaluate the safety and efficacy of the drug but also to explore its dosage, treatment regimens, and potential side effects. This review discusses the various stages of clinical trials, including Phase I (safety assessment), Phase II (preliminary efficacy evaluation), Phase III (large-scale validation), and Phase IV (post-marketing surveillance), highlighting the characteristics of each phase and their interrelationships. Additionally, the paper addresses the major challenges encountered in clinical trials, such as ethical issues, subject recruitment difficulties, diversity and representativeness concerns, and proposes strategies for overcoming these challenges. With the advancement of technology, innovative technologies such as artificial intelligence, big data, and digitalization are gradually transforming clinical trial design and implementation, improving trial efficiency and data quality. The article also looks forward to the future of clinical trials, particularly the impact of emerging therapies such as gene therapy and immunotherapy on trial design, as well as the importance of regulatory reforms and global collaboration. In conclusion, the core role of clinical trials in drug development will continue to drive the progress of innovative drug development and clinical treatment.
Deep Learning Model Security: Threats and Defenses
Dec 12, 2024
Deep learning has transformed AI applications but faces critical security challenges, including adversarial attacks, data poisoning, model theft, and privacy leakage. This survey examines these vulnerabilities, detailing their mechanisms and impact on model integrity and confidentiality. Practical implementations, including adversarial examples, label flipping, and backdoor attacks, are explored alongside defenses such as adversarial training, differential privacy, and federated learning, highlighting their strengths and limitations. Advanced methods like contrastive and self-supervised learning are presented for enhancing robustness. The survey concludes with future directions, emphasizing automated defenses, zero-trust architectures, and the security challenges of large AI models. A balanced approach to performance and security is essential for developing reliable deep learning systems.
Deep Learning, Machine Learning, Advancing Big Data Analytics and Management
Dec 03, 2024



Advancements in artificial intelligence, machine learning, and deep learning have catalyzed the transformation of big data analytics and management into pivotal domains for research and application. This work explores the theoretical foundations, methodological advancements, and practical implementations of these technologies, emphasizing their role in uncovering actionable insights from massive, high-dimensional datasets. The study presents a systematic overview of data preprocessing techniques, including data cleaning, normalization, integration, and dimensionality reduction, to prepare raw data for analysis. Core analytics methodologies such as classification, clustering, regression, and anomaly detection are examined, with a focus on algorithmic innovation and scalability. Furthermore, the text delves into state-of-the-art frameworks for data mining and predictive modeling, highlighting the role of neural networks, support vector machines, and ensemble methods in tackling complex analytical challenges. Special emphasis is placed on the convergence of big data with distributed computing paradigms, including cloud and edge computing, to address challenges in storage, computation, and real-time analytics. The integration of ethical considerations, including data privacy and compliance with global standards, ensures a holistic perspective on data management. Practical applications across healthcare, finance, marketing, and policy-making illustrate the real-world impact of these technologies. Through comprehensive case studies and Python-based implementations, this work equips researchers, practitioners, and data enthusiasts with the tools to navigate the complexities of modern data analytics. It bridges the gap between theory and practice, fostering the development of innovative solutions for managing and leveraging data in the era of artificial intelligence.
A Comprehensive Guide to Explainable AI: From Classical Models to LLMs
Dec 01, 2024



Explainable Artificial Intelligence (XAI) addresses the growing need for transparency and interpretability in AI systems, enabling trust and accountability in decision-making processes. This book offers a comprehensive guide to XAI, bridging foundational concepts with advanced methodologies. It explores interpretability in traditional models such as Decision Trees, Linear Regression, and Support Vector Machines, alongside the challenges of explaining deep learning architectures like CNNs, RNNs, and Large Language Models (LLMs), including BERT, GPT, and T5. The book presents practical techniques such as SHAP, LIME, Grad-CAM, counterfactual explanations, and causal inference, supported by Python code examples for real-world applications. Case studies illustrate XAI's role in healthcare, finance, and policymaking, demonstrating its impact on fairness and decision support. The book also covers evaluation metrics for explanation quality, an overview of cutting-edge XAI tools and frameworks, and emerging research directions, such as interpretability in federated learning and ethical AI considerations. Designed for a broad audience, this resource equips readers with the theoretical insights and practical skills needed to master XAI. Hands-on examples and additional resources are available at the companion GitHub repository: https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.
From Word Vectors to Multimodal Embeddings: Techniques, Applications, and Future Directions For Large Language Models
Nov 06, 2024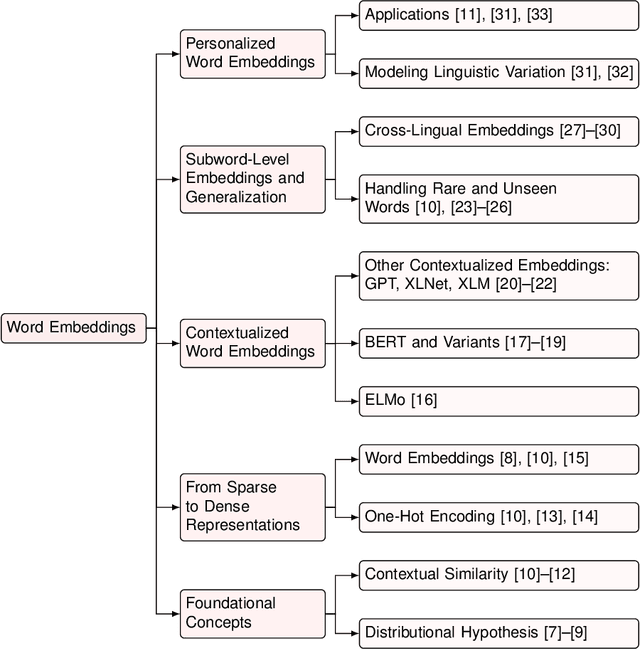


Word embeddings and language models have transformed natural language processing (NLP) by facilitating the representation of linguistic elements in continuous vector spaces. This review visits foundational concepts such as the distributional hypothesis and contextual similarity, tracing the evolution from sparse representations like one-hot encoding to dense embeddings including Word2Vec, GloVe, and fastText. We examine both static and contextualized embeddings, underscoring advancements in models such as ELMo, BERT, and GPT and their adaptations for cross-lingual and personalized applications. The discussion extends to sentence and document embeddings, covering aggregation methods and generative topic models, along with the application of embeddings in multimodal domains, including vision, robotics, and cognitive science. Advanced topics such as model compression, interpretability, numerical encoding, and bias mitigation are analyzed, addressing both technical challenges and ethical implications. Additionally, we identify future research directions, emphasizing the need for scalable training techniques, enhanced interpretability, and robust grounding in non-textual modalities. By synthesizing current methodologies and emerging trends, this survey offers researchers and practitioners an in-depth resource to push the boundaries of embedding-based language models.
Deep Learning and Machine Learning -- Natural Language Processing: From Theory to Application
Oct 30, 2024
With a focus on natural language processing (NLP) and the role of large language models (LLMs), we explore the intersection of machine learning, deep learning, and artificial intelligence. As artificial intelligence continues to revolutionize fields from healthcare to finance, NLP techniques such as tokenization, text classification, and entity recognition are essential for processing and understanding human language. This paper discusses advanced data preprocessing techniques and the use of frameworks like Hugging Face for implementing transformer-based models. Additionally, it highlights challenges such as handling multilingual data, reducing bias, and ensuring model robustness. By addressing key aspects of data processing and model fine-tuning, this work aims to provide insights into deploying effective and ethically sound AI solutions.