 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO-2: A Large-Scale Distributed Rollout Framework for Cost-Efficient Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.
Adaptive Detector-Verifier Framework for Zero-Shot Polyp Detection in Open-World Settings
Dec 16, 2025Polyp detectors trained on clean datasets often underperform in real-world endoscopy, where illumination changes, motion blur, and occlusions degrade image quality. Existing approaches struggle with the domain gap between controlled laboratory conditions and clinical practice, where adverse imaging conditions are prevalent. In this work, we propose AdaptiveDetector, a novel two-stage detector-verifier framework comprising a YOLOv11 detector with a vision-language model (VLM) verifier. The detector adaptively adjusts per-frame confidence thresholds under VLM guidance, while the verifier is fine-tuned with Group Relative Policy Optimization (GRPO) using an asymmetric, cost-sensitive reward function specifically designed to discourage missed detections -- a critical clinical requirement. To enable realistic assessment under challenging conditions, we construct a comprehensive synthetic testbed by systematically degrading clean datasets with adverse conditions commonly encountered in clinical practice, providing a rigorous benchmark for zero-shot evaluation. Extensive zero-shot evaluation on synthetically degraded CVC-ClinicDB and Kvasir-SEG images demonstrates that our approach improves recall by 14 to 22 percentage points over YOLO alone, while precision remains within 0.7 points below to 1.7 points above the baseline. This combination of adaptive thresholding and cost-sensitive reinforcement learning achieves clinically aligned, open-world polyp detection with substantially fewer false negatives, thereby reducing the risk of missed precancerous polyps and improving patient outcomes.
Is GPT-OSS All You Need? Benchmarking Large Language Models for Financial Intelligence and the Surprising Efficiency Paradox
Dec 09, 2025The rapid adoption of large language models in financial services necessitates rigorous evaluation frameworks to assess their performance, efficiency, and practical applicability. This paper conducts a comprehensive evaluation of the GPT-OSS model family alongside contemporary LLMs across ten diverse financial NLP tasks. Through extensive experimentation on 120B and 20B parameter variants of GPT-OSS, we reveal a counterintuitive finding: the smaller GPT-OSS-20B model achieves comparable accuracy (65.1% vs 66.5%) while demonstrating superior computational efficiency with 198.4 Token Efficiency Score and 159.80 tokens per second processing speed [1]. Our evaluation encompasses sentiment analysis, question answering, and entity recognition tasks using real-world financial datasets including Financial PhraseBank, FiQA-SA, and FLARE FINERORD. We introduce novel efficiency metrics that capture the trade-off between model performance and resource utilization, providing critical insights for deployment decisions in production environments. The benchmark reveals that GPT-OSS models consistently outperform larger competitors including Qwen3-235B, challenging the prevailing assumption that model scale directly correlates with task performance [2]. Our findings demonstrate that architectural innovations and training strategies in GPT-OSS enable smaller models to achieve competitive performance with significantly reduced computational overhead, offering a pathway toward sustainable and cost-effective deployment of LLMs in financial applications.
CoT-X: An Adaptive Framework for Cross-Model Chain-of-Thought Transfer and Optimization
Nov 07, 2025



Chain-of-Thought (CoT) reasoning enhances the problem-solving ability of large language models (LLMs) but leads to substantial inference overhead, limiting deployment in resource-constrained settings. This paper investigates efficient CoT transfer across models of different scales and architectures through an adaptive reasoning summarization framework. The proposed method compresses reasoning traces via semantic segmentation with importance scoring, budget-aware dynamic compression, and coherence reconstruction, preserving critical reasoning steps while significantly reducing token usage. Experiments on 7{,}501 medical examination questions across 10 specialties show up to 40% higher accuracy than truncation under the same token budgets. Evaluations on 64 model pairs from eight LLMs (1.5B-32B parameters, including DeepSeek-R1 and Qwen3) confirm strong cross-model transferability. Furthermore, a Gaussian Process-based Bayesian optimization module reduces evaluation cost by 84% and reveals a power-law relationship between model size and cross-domain robustness. These results demonstrate that reasoning summarization provides a practical path toward efficient CoT transfer, enabling advanced reasoning under tight computational constraints. Code will be released upon publication.
AutoSurvey2: Empowering Researchers with Next Level Automated Literature Surveys
Oct 29, 2025The rapid growth of research literature, particularly in large language models (LLMs), has made producing comprehensive and current survey papers increasingly difficult. This paper introduces autosurvey2, a multi-stage pipeline that automates survey generation through retrieval-augmented synthesis and structured evaluation. The system integrates parallel section generation, iterative refinement, and real-time retrieval of recent publications to ensure both topical completeness and factual accuracy. Quality is assessed using a multi-LLM evaluation framework that measures coverage, structure, and relevance in alignment with expert review standards. Experimental results demonstrate that autosurvey2 consistently outperforms existing retrieval-based and automated baselines, achieving higher scores in structural coherence and topical relevance while maintaining strong citation fidelity. By combining retrieval, reasoning, and automated evaluation into a unified framework, autosurvey2 provides a scalable and reproducible solution for generating long-form academic surveys and contributes a solid foundation for future research on automated scholarly writing. All code and resources are available at https://github.com/annihi1ation/auto_research.
Towards Alignment-Centric Paradigm: A Survey of Instruction Tuning in Large Language Models
Aug 24, 2025



Instruction tuning is a pivotal technique for aligning large language models (LLMs) with human intentions, safety constraints, and domain-specific requirements. This survey provides a comprehensive overview of the full pipeline, encompassing (i) data collection methodologies, (ii) full-parameter and parameter-efficient fine-tuning strategies, and (iii) evaluation protocols. We categorized data construction into three major paradigms: expert annotation, distillation from larger models, and self-improvement mechanisms, each offering distinct trade-offs between quality, scalability, and resource cost. Fine-tuning techniques range from conventional supervised training to lightweight approaches, such as low-rank adaptation (LoRA) and prefix tuning, with a focus on computational efficiency and model reusability. We further examine the challenges of evaluating faithfulness, utility, and safety across multilingual and multimodal scenarios, highlighting the emergence of domain-specific benchmarks in healthcare, legal, and financial applications. Finally, we discuss promising directions for automated data generation, adaptive optimization, and robust evaluation frameworks, arguing that a closer integration of data, algorithms, and human feedback is essential for advancing instruction-tuned LLMs. This survey aims to serve as a practical reference for researchers and practitioners seeking to design LLMs that are both effective and reliably aligned with human intentions.
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models
Aug 17, 2025



In August 2025, OpenAI released GPT-OSS models, its first open weight large language models since GPT-2 in 2019, comprising two mixture of experts architectures with 120B and 20B parameters. We evaluated both variants against six contemporary open source large language models ranging from 14.7B to 235B parameters, representing both dense and sparse designs, across ten benchmarks covering general knowledge, mathematical reasoning, code generation, multilingual understanding, and conversational ability. All models were tested in unquantised form under standardised inference settings, with statistical validation using McNemars test and effect size analysis. Results show that gpt-oss-20B consistently outperforms gpt-oss-120B on several benchmarks, such as HumanEval and MMLU, despite requiring substantially less memory and energy per response. Both models demonstrate mid-tier overall performance within the current open source landscape, with relative strength in code generation and notable weaknesses in multilingual tasks. These findings provide empirical evidence that scaling in sparse architectures may not yield proportional performance gains, underscoring the need for further investigation into optimisation strategies and informing more efficient model selection for future open source deployments.
Predicting ICU In-Hospital Mortality Using Adaptive Transformer Layer Fusion
Jun 06, 2025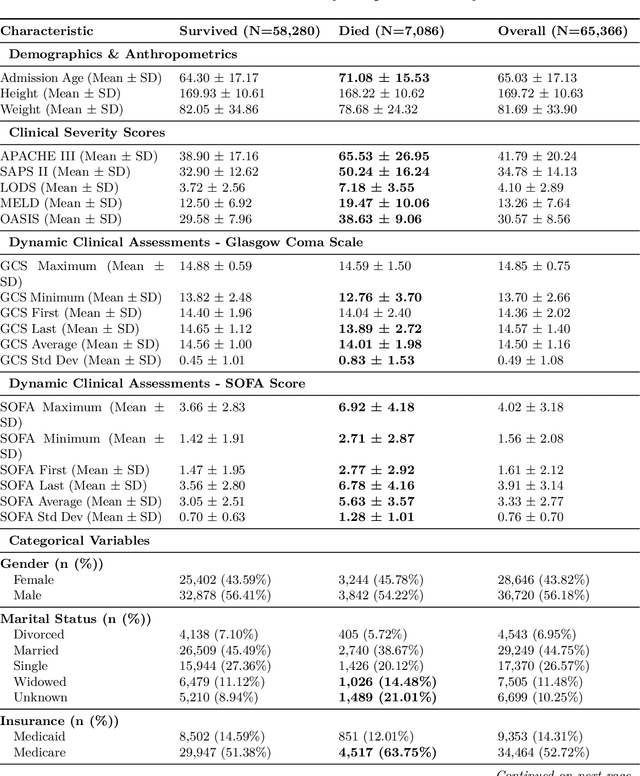
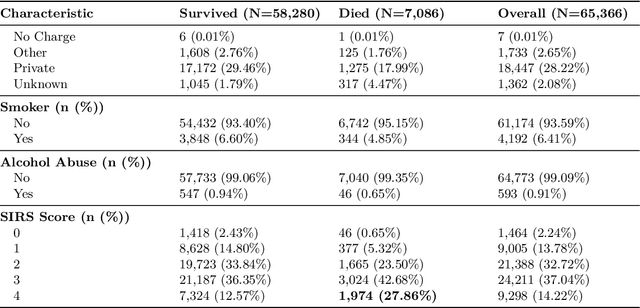
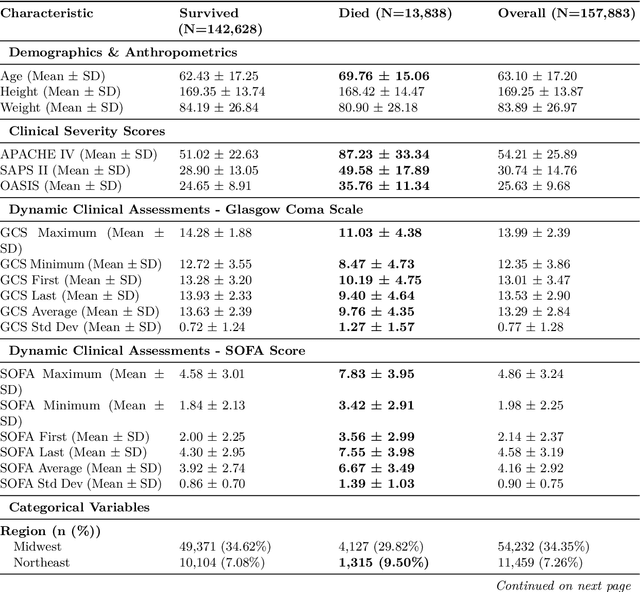
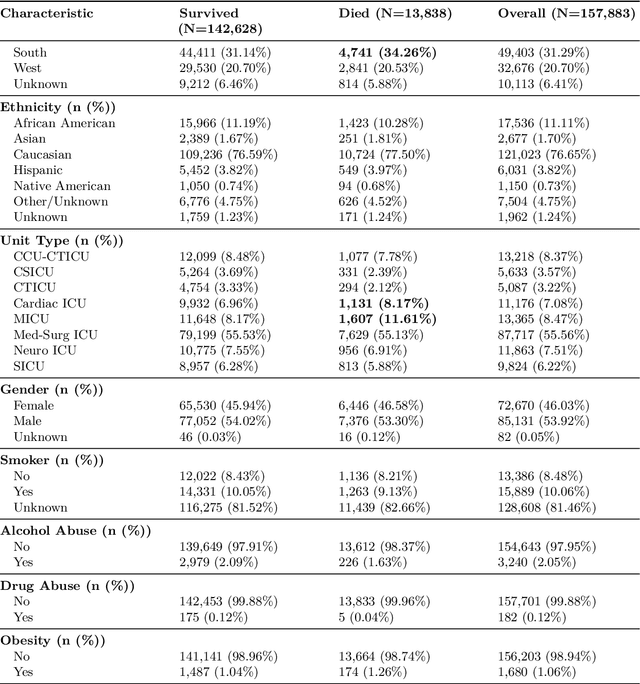
Early identification of high-risk ICU patients is crucial for directing limited medical resources. We introduce ALFIA (Adaptive Layer Fusion with Intelligent Attention), a modular, attention-based architecture that jointly trains LoRA (Low-Rank Adaptation) adapters and an adaptive layer-weighting mechanism to fuse multi-layer semantic features from a BERT backbone. Trained on our rigorous cw-24 (CriticalWindow-24) benchmark, ALFIA surpasses state-of-the-art tabular classifiers in AUPRC while preserving a balanced precision-recall profile. The embeddings produced by ALFIA's fusion module, capturing both fine-grained clinical cues and high-level concepts, enable seamless pairing with GBDTs (CatBoost/LightGBM) as ALFIA-boost, and deep neuro networks as ALFIA-nn, yielding additional performance gains. Our experiments confirm ALFIA's superior early-warning performance, by operating directly on routine clinical text, it furnishes clinicians with a convenient yet robust tool for risk stratification and timely intervention in critical-care settings.
Active Learning Methods for Efficient Data Utilization and Model Performance Enhancement
Apr 21, 2025In the era of data-driven intelligence, the paradox of data abundance and annotation scarcity has emerged as a critical bottleneck in the advancement of machine learning. This paper gives a detailed overview of Active Learning (AL), which is a strategy in machine learning that helps models achieve better performance using fewer labeled examples. It introduces the basic concepts of AL and discusses how it is used in various fields such as computer vision, natural language processing, transfer learning, and real-world applications. The paper focuses on important research topics such as uncertainty estimation, handling of class imbalance, domain adaptation, fairness, and the creation of strong evaluation metrics and benchmarks. It also shows that learning methods inspired by humans and guided by questions can improve data efficiency and help models learn more effectively. In addition, this paper talks about current challenges in the field, including the need to rebuild trust, ensure reproducibility, and deal with inconsistent methodologies. It points out that AL often gives better results than passive learning, especially when good evaluation measures are used. This work aims to be useful for both researchers and practitioners by providing key insights and proposing directions for future progress in active learning.
Feature Alignment and Representation Transfer in Knowledge Distillation for Large Language Models
Apr 18, 2025Knowledge distillation (KD) is a technique for transferring knowledge from complex teacher models to simpler student models, significantly enhancing model efficiency and accuracy. It has demonstrated substantial advancements in various applications including image classification, object detection, language modeling, text classification, and sentiment analysis. Recent innovations in KD methods, such as attention-based approaches, block-wise logit distillation, and decoupling distillation, have notably improved student model performance. These techniques focus on stimulus complexity, attention mechanisms, and global information capture to optimize knowledge transfer. In addition, KD has proven effective in compressing large language models while preserving accuracy, reducing computational overhead, and improving inference speed. This survey synthesizes the latest literature, highlighting key findings, contributions, and future directions in knowledge distillation to provide insights for researchers and practitioners on its evolving role in artificial intelligence and machine learning.