 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForSim: Stepwise Forward Simulation for Traffic Policy Fine-Tuning
Feb 02, 2026As the foundation of closed-loop training and evaluation in autonomous driving, traffic simulation still faces two fundamental challenges: covariate shift introduced by open-loop imitation learning and limited capacity to reflect the multimodal behaviors observed in real-world traffic. Although recent frameworks such as RIFT have partially addressed these issues through group-relative optimization, their forward simulation procedures remain largely non-reactive, leading to unrealistic agent interactions within the virtual domain and ultimately limiting simulation fidelity. To address these issues, we propose ForSim, a stepwise closed-loop forward simulation paradigm. At each virtual timestep, the traffic agent propagates the virtual candidate trajectory that best spatiotemporally matches the reference trajectory through physically grounded motion dynamics, thereby preserving multimodal behavioral diversity while ensuring intra-modality consistency. Other agents are updated with stepwise predictions, yielding coherent and interaction-aware evolution. When incorporated into the RIFT traffic simulation framework, ForSim operates in conjunction with group-relative optimization to fine-tune traffic policy. Extensive experiments confirm that this integration consistently improves safety while maintaining efficiency, realism, and comfort. These results underscore the importance of modeling closed-loop multimodal interactions within forward simulation and enhance the fidelity and reliability of traffic simulation for autonomous driving. Project Page: https://currychen77.github.io/ForSim/
When should I search more: Adaptive Complex Query Optimization with Reinforcement Learning
Jan 29, 2026Query optimization is a crucial component for the efficacy of Retrieval-Augmented Generation (RAG) systems. While reinforcement learning (RL)-based agentic and reasoning methods have recently emerged as a promising direction on query optimization, most existing approaches focus on the expansion and abstraction of a single query. However, complex user queries are prevalent in real-world scenarios, often requiring multiple parallel and sequential search strategies to handle disambiguation and decomposition. Directly applying RL to these complex cases introduces significant hurdles. Determining the optimal number of sub-queries and effectively re-ranking and merging retrieved documents vastly expands the search space and complicates reward design, frequently leading to training instability. To address these challenges, we propose a novel RL framework called Adaptive Complex Query Optimization (ACQO). Our framework is designed to adaptively determine when and how to expand the search process. It features two core components: an Adaptive Query Reformulation (AQR) module that dynamically decides when to decompose a query into multiple sub-queries, and a Rank-Score Fusion (RSF) module that ensures robust result aggregation and provides stable reward signals for the learning agent. To mitigate training instabilities, we adopt a Curriculum Reinforcement Learning (CRL) approach, which stabilizes the training process by progressively introducing more challenging queries through a two-stage strategy. Our comprehensive experiments demonstrate that ACQO achieves state-of-the-art performance on three complex query benchmarks, significantly outperforming established baselines. The framework also showcases improved computational efficiency and broad compatibility with different retrieval architectures, establishing it as a powerful and generalizable solution for next-generation RAG systems.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
ExpertAD: Enhancing Autonomous Driving Systems with Mixture of Experts
Nov 13, 2025Recent advancements in end-to-end autonomous driving systems (ADSs) underscore their potential for perception and planning capabilities. However, challenges remain. Complex driving scenarios contain rich semantic information, yet ambiguous or noisy semantics can compromise decision reliability, while interference between multiple driving tasks may hinder optimal planning. Furthermore, prolonged inference latency slows decision-making, increasing the risk of unsafe driving behaviors. To address these challenges, we propose ExpertAD, a novel framework that enhances the performance of ADS with Mixture of Experts (MoE) architecture. We introduce a Perception Adapter (PA) to amplify task-critical features, ensuring contextually relevant scene understanding, and a Mixture of Sparse Experts (MoSE) to minimize task interference during prediction, allowing for effective and efficient planning. Our experiments show that ExpertAD reduces average collision rates by up to 20% and inference latency by 25% compared to prior methods. We further evaluate its multi-skill planning capabilities in rare scenarios (e.g., accidents, yielding to emergency vehicles) and demonstrate strong generalization to unseen urban environments. Additionally, we present a case study that illustrates its decision-making process in complex driving scenarios.
Modified-Emergency Index (MEI): A Criticality Metric for Autonomous Driving in Lateral Conflict
Oct 31, 2025Effective, reliable, and efficient evaluation of autonomous driving safety is essential to demonstrate its trustworthiness. Criticality metrics provide an objective means of assessing safety. However, as existing metrics primarily target longitudinal conflicts, accurately quantifying the risks of lateral conflicts - prevalent in urban settings - remains challenging. This paper proposes the Modified-Emergency Index (MEI), a metric designed to quantify evasive effort in lateral conflicts. Compared to the original Emergency Index (EI), MEI refines the estimation of the time available for evasive maneuvers, enabling more precise risk quantification. We validate MEI on a public lateral conflict dataset based on Argoverse-2, from which we extract over 1,500 high-quality AV conflict cases, including more than 500 critical events. MEI is then compared with the well-established ACT and the widely used PET metrics. Results show that MEI consistently outperforms them in accurately quantifying criticality and capturing risk evolution. Overall, these findings highlight MEI as a promising metric for evaluating urban conflicts and enhancing the safety assessment framework for autonomous driving. The open-source implementation is available at https://github.com/AutoChengh/MEI.
AutoSurvey2: Empowering Researchers with Next Level Automated Literature Surveys
Oct 29, 2025The rapid growth of research literature, particularly in large language models (LLMs), has made producing comprehensive and current survey papers increasingly difficult. This paper introduces autosurvey2, a multi-stage pipeline that automates survey generation through retrieval-augmented synthesis and structured evaluation. The system integrates parallel section generation, iterative refinement, and real-time retrieval of recent publications to ensure both topical completeness and factual accuracy. Quality is assessed using a multi-LLM evaluation framework that measures coverage, structure, and relevance in alignment with expert review standards. Experimental results demonstrate that autosurvey2 consistently outperforms existing retrieval-based and automated baselines, achieving higher scores in structural coherence and topical relevance while maintaining strong citation fidelity. By combining retrieval, reasoning, and automated evaluation into a unified framework, autosurvey2 provides a scalable and reproducible solution for generating long-form academic surveys and contributes a solid foundation for future research on automated scholarly writing. All code and resources are available at https://github.com/annihi1ation/auto_research.
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models
Aug 17, 2025



In August 2025, OpenAI released GPT-OSS models, its first open weight large language models since GPT-2 in 2019, comprising two mixture of experts architectures with 120B and 20B parameters. We evaluated both variants against six contemporary open source large language models ranging from 14.7B to 235B parameters, representing both dense and sparse designs, across ten benchmarks covering general knowledge, mathematical reasoning, code generation, multilingual understanding, and conversational ability. All models were tested in unquantised form under standardised inference settings, with statistical validation using McNemars test and effect size analysis. Results show that gpt-oss-20B consistently outperforms gpt-oss-120B on several benchmarks, such as HumanEval and MMLU, despite requiring substantially less memory and energy per response. Both models demonstrate mid-tier overall performance within the current open source landscape, with relative strength in code generation and notable weaknesses in multilingual tasks. These findings provide empirical evidence that scaling in sparse architectures may not yield proportional performance gains, underscoring the need for further investigation into optimisation strategies and informing more efficient model selection for future open source deployments.
ASPD: Unlocking Adaptive Serial-Parallel Decoding by Exploring Intrinsic Parallelism in LLMs
Aug 12, 2025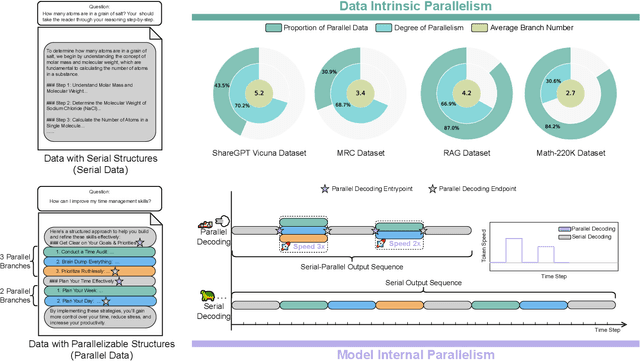
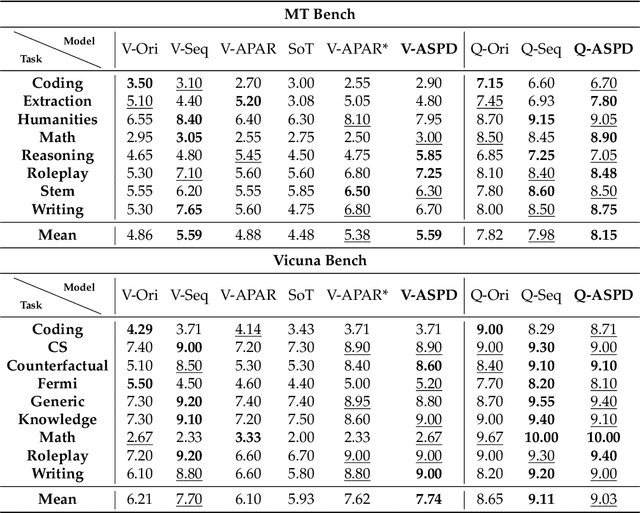
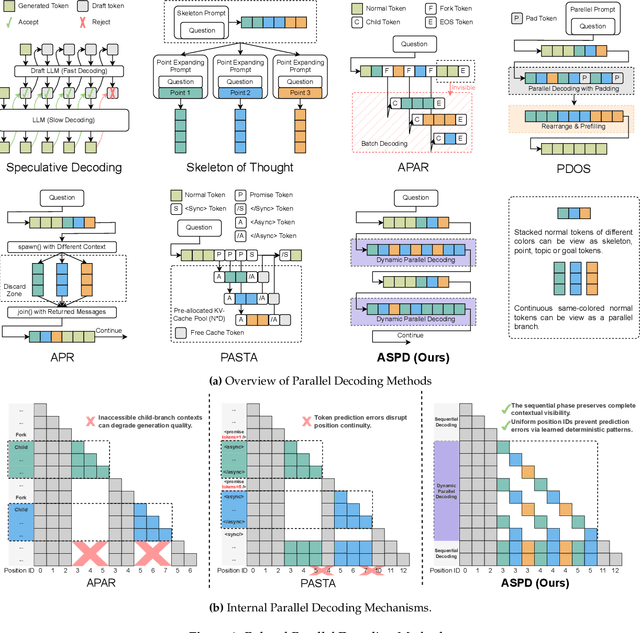
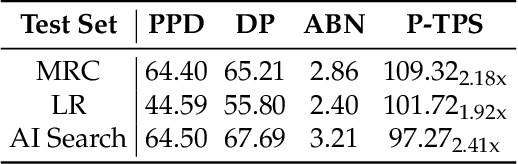
The increasing scale and complexity of large language models (LLMs) pose significant inference latency challenges, primarily due to their autoregressive decoding paradigm characterized by the sequential nature of next-token prediction. By re-examining the outputs of autoregressive models, we observed that some segments exhibit parallelizable structures, which we term intrinsic parallelism. Decoding each parallelizable branch simultaneously (i.e. parallel decoding) can significantly improve the overall inference speed of LLMs. In this paper, we propose an Adaptive Serial-Parallel Decoding (ASPD), which addresses two core challenges: automated construction of parallelizable data and efficient parallel decoding mechanism. More specifically, we introduce a non-invasive pipeline that automatically extracts and validates parallelizable structures from the responses of autoregressive models. To empower efficient adaptive serial-parallel decoding, we implement a Hybrid Decoding Engine which enables seamless transitions between serial and parallel decoding modes while maintaining a reusable KV cache, maximizing computational efficiency. Extensive evaluations across General Tasks, Retrieval-Augmented Generation, Mathematical Reasoning, demonstrate that ASPD achieves unprecedented performance in both effectiveness and efficiency. Notably, on Vicuna Bench, our method achieves up to 3.19x speedup (1.85x on average) while maintaining response quality within 1% difference compared to autoregressive models, realizing significant acceleration without compromising generation quality. Our framework sets a groundbreaking benchmark for efficient LLM parallel inference, paving the way for its deployment in latency-sensitive applications such as AI-powered customer service bots and answer retrieval engines.
DriveCamSim: Generalizable Camera Simulation via Explicit Camera Modeling for Autonomous Driving
May 26, 2025Camera sensor simulation serves as a critical role for autonomous driving (AD), e.g. evaluating vision-based AD algorithms. While existing approaches have leveraged generative models for controllable image/video generation, they remain constrained to generating multi-view video sequences with fixed camera viewpoints and video frequency, significantly limiting their downstream applications. To address this, we present a generalizable camera simulation framework DriveCamSim, whose core innovation lies in the proposed Explicit Camera Modeling (ECM) mechanism. Instead of implicit interaction through vanilla attention, ECM establishes explicit pixel-wise correspondences across multi-view and multi-frame dimensions, decoupling the model from overfitting to the specific camera configurations (intrinsic/extrinsic parameters, number of views) and temporal sampling rates presented in the training data. For controllable generation, we identify the issue of information loss inherent in existing conditional encoding and injection pipelines, proposing an information-preserving control mechanism. This control mechanism not only improves conditional controllability, but also can be extended to be identity-aware to enhance temporal consistency in foreground object rendering. With above designs, our model demonstrates superior performance in both visual quality and controllability, as well as generalization capability across spatial-level (camera parameters variations) and temporal-level (video frame rate variations), enabling flexible user-customizable camera simulation tailored to diverse application scenarios. Code will be avaliable at https://github.com/swc-17/DriveCamSim for facilitating future research.
Improved Algorithms for Differentially Private Language Model Alignment
May 13, 2025Language model alignment is crucial for ensuring that large language models (LLMs) align with human preferences, yet it often involves sensitive user data, raising significant privacy concerns. While prior work has integrated differential privacy (DP) with alignment techniques, their performance remains limited. In this paper, we propose novel algorithms for privacy-preserving alignment and rigorously analyze their effectiveness across varying privacy budgets and models. Our framework can be deployed on two celebrated alignment techniques, namely direct preference optimization (DPO) and reinforcement learning from human feedback (RLHF). Through systematic experiments on large-scale language models, we demonstrate that our approach achieves state-of-the-art performance. Notably, one of our algorithms, DP-AdamW, combined with DPO, surpasses existing methods, improving alignment quality by up to 15% under moderate privacy budgets ({\epsilon}=2-5). We further investigate the interplay between privacy guarantees, alignment efficacy, and computational demands, providing practical guidelines for optimizing these trade-offs.