 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking to Your Data: Exploring Embodied Conversation as an Interface for Personal Health Reflection
Jun 16, 2026Personal health data from wearables are typically presented through dashboards of charts and summary statistics, requiring users to actively interpret patterns and implications. We explore an alternative interaction paradigm: engaging with personal health data through an embodied conversational agent that facilitates objective data reflection in dialogue with the user. We present a system that combines lightweight preprocessing of wearable data with a Unity-based embodied character. Internally, the system follows a dual-agent design in which an Observer agent extracts descriptive statistics and temporal trends, and a Presenter agent communicates these findings through "spoken statistics," intentionally refraining from clinical advice to isolate the impact of the interaction modality. We evaluate this approach through a simulated-self user study (N=5) using a within-subject design. Participants adopted health personas and goals derived from the LifeSnaps dataset to compare traditional dashboard exploration with embodied conversational reflection. Our evaluation focuses on perceived understanding, the specificity of generated actions, and the cognitive shift from passive viewing to active sensemaking. The paper contributes a functional prototype, a design pattern for objective health data narrative generation, and early empirical insights into how embodiment affects the interpretation of personal health metrics.
Exploiting Meta-Learning-based Poisoning Attacks for Graph Link Prediction
Apr 08, 2025



Link prediction in graph data utilizes various algorithms and machine learning/deep learning models to predict potential relationships between graph nodes. This technique has found widespread use in numerous real-world applications, including recommendation systems, community networks, and biological structures. However, recent research has highlighted the vulnerability of link prediction models to adversarial attacks, such as poisoning and evasion attacks. Addressing the vulnerability of these models is crucial to ensure stable and robust performance in link prediction applications. While many works have focused on enhancing the robustness of the Graph Convolution Network (GCN) model, the Variational Graph Auto-Encoder (VGAE), a sophisticated model for link prediction, has not been thoroughly investigated in the context of graph adversarial attacks. To bridge this gap, this article proposes an unweighted graph poisoning attack approach using meta-learning techniques to undermine VGAE's link prediction performance. We conducted comprehensive experiments on diverse datasets to evaluate the proposed method and its parameters, comparing it with existing approaches in similar settings. Our results demonstrate that our approach significantly diminishes link prediction performance and outperforms other state-of-the-art methods.
Epi-Curriculum: Episodic Curriculum Learning for Low-Resource Domain Adaptation in Neural Machine Translation
Sep 06, 2023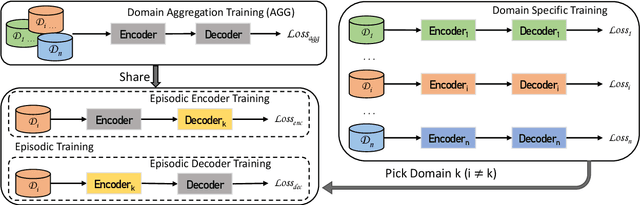
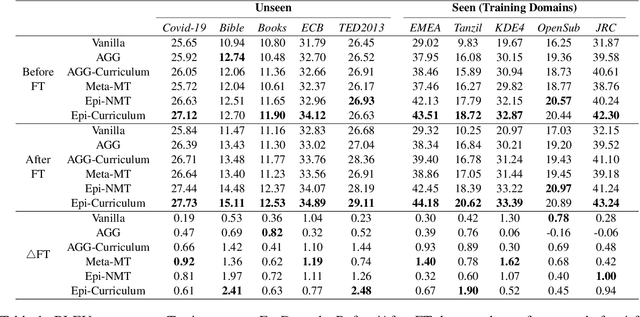

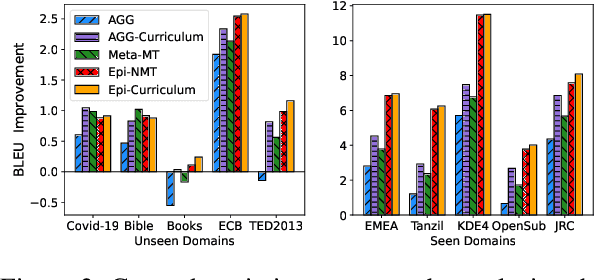
Neural Machine Translation (NMT) models have become successful, but their performance remains poor when translating on new domains with a limited number of data. In this paper, we present a novel approach Epi-Curriculum to address low-resource domain adaptation (DA), which contains a new episodic training framework along with denoised curriculum learning. Our episodic training framework enhances the model's robustness to domain shift by episodically exposing the encoder/decoder to an inexperienced decoder/encoder. The denoised curriculum learning filters the noised data and further improves the model's adaptability by gradually guiding the learning process from easy to more difficult tasks. Experiments on English-German and English-Romanian translation show that: (i) Epi-Curriculum improves both model's robustness and adaptability in seen and unseen domains; (ii) Our episodic training framework enhances the encoder and decoder's robustness to domain shift.
MC-GEN:Multi-level Clustering for Private Synthetic Data Generation
May 28, 2022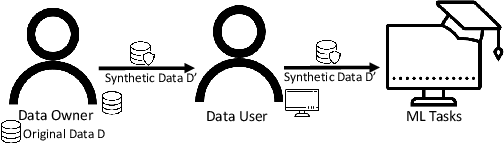


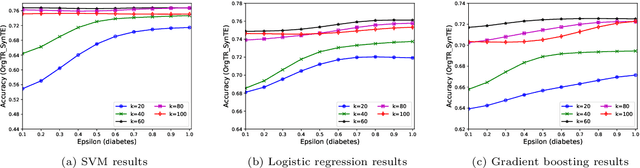
Nowadays, machine learning is one of the most common technology to turn raw data into useful information in scientific and industrial processes. The performance of the machine learning model often depends on the size of dataset. Companies and research institutes usually share or exchange their data to avoid data scarcity. However, sharing original datasets that contain private information can cause privacy leakage. Utilizing synthetic datasets which have similar characteristics as a substitute is one of the solutions to avoid the privacy issue. Differential privacy provides a strong privacy guarantee to protect the individual data records which contain sensitive information. We propose MC-GEN, a privacy-preserving synthetic data generation method under differential privacy guarantee for multiple classification tasks. MC-GEN builds differentially private generative models on the multi-level clustered data to generate synthetic datasets. Our method also reduced the noise introduced from differential privacy to improve the utility. In experimental evaluation, we evaluated the parameter effect of MC-GEN and compared MC-GEN with three existing methods. Our results showed that MC-GEN can achieve significant effectiveness under certain privacy guarantees on multiple classification tasks.
SuperCon: Supervised Contrastive Learning for Imbalanced Skin Lesion Classification
Feb 11, 2022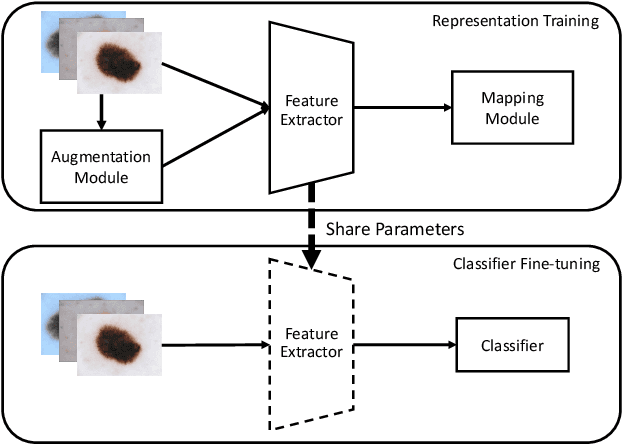
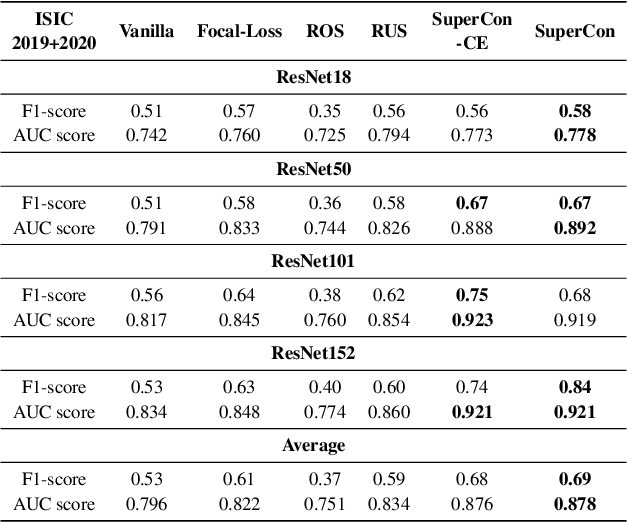

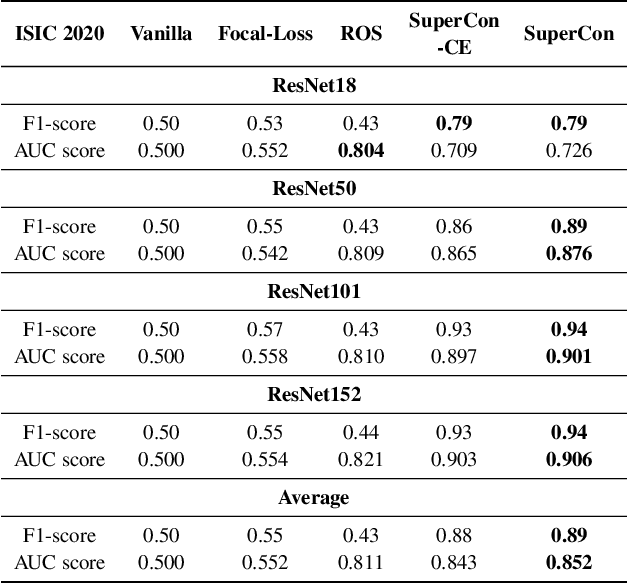
Convolutional neural networks (CNNs) have achieved great success in skin lesion classification. A balanced dataset is required to train a good model. However, due to the appearance of different skin lesions in practice, severe or even deadliest skin lesion types (e.g., melanoma) naturally have quite small amount represented in a dataset. In that, classification performance degradation occurs widely, it is significantly important to have CNNs that work well on class imbalanced skin lesion image dataset. In this paper, we propose SuperCon, a two-stage training strategy to overcome the class imbalance problem on skin lesion classification. It contains two stages: (i) representation training that tries to learn a feature representation that closely aligned among intra-classes and distantly apart from inter-classes, and (ii) classifier fine-tuning that aims to learn a classifier that correctly predict the label based on the learnt representations. In the experimental evaluation, extensive comparisons have been made among our approach and other existing approaches on skin lesion benchmark datasets. The results show that our two-stage training strategy effectively addresses the class imbalance classification problem, and significantly improves existing works in terms of F1-score and AUC score, resulting in state-of-the-art performance.
Locally Differentially Private Distributed Deep Learning via Knowledge Distillation
Feb 07, 2022



Deep learning often requires a large amount of data. In real-world applications, e.g., healthcare applications, the data collected by a single organization (e.g., hospital) is often limited, and the majority of massive and diverse data is often segregated across multiple organizations. As such, it motivates the researchers to conduct distributed deep learning, where the data user would like to build DL models using the data segregated across multiple different data owners. However, this could lead to severe privacy concerns due to the sensitive nature of the data, thus the data owners would be hesitant and reluctant to participate. We propose LDP-DL, a privacy-preserving distributed deep learning framework via local differential privacy and knowledge distillation, where each data owner learns a teacher model using its own (local) private dataset, and the data user learns a student model to mimic the output of the ensemble of the teacher models. In the experimental evaluation, a comprehensive comparison has been made among our proposed approach (i.e., LDP-DL), DP-SGD, PATE and DP-FL, using three popular deep learning benchmark datasets (i.e., CIFAR10, MNIST and FashionMNIST). The experimental results show that LDP-DL consistently outperforms the other competitors in terms of privacy budget and model accuracy.
ESAI: Efficient Split Artificial Intelligence via Early Exiting Using Neural Architecture Search
Jun 21, 2021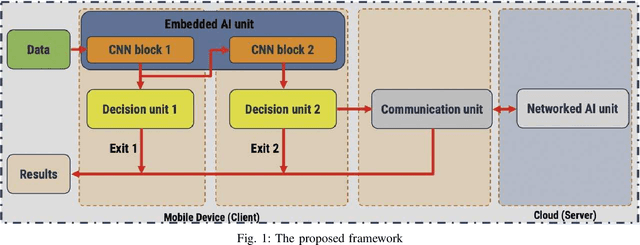
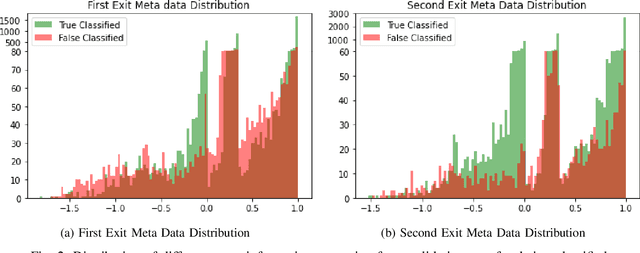
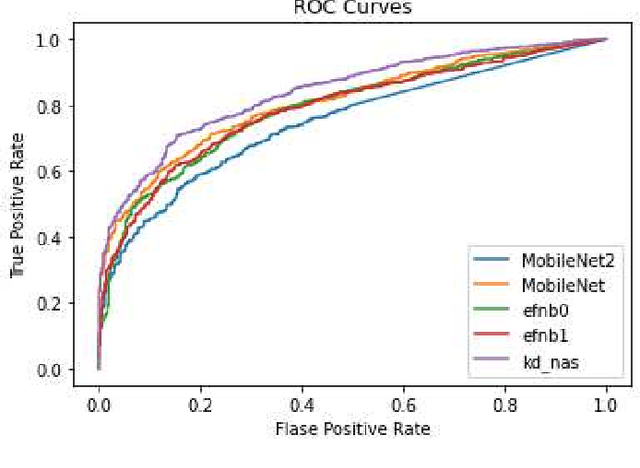
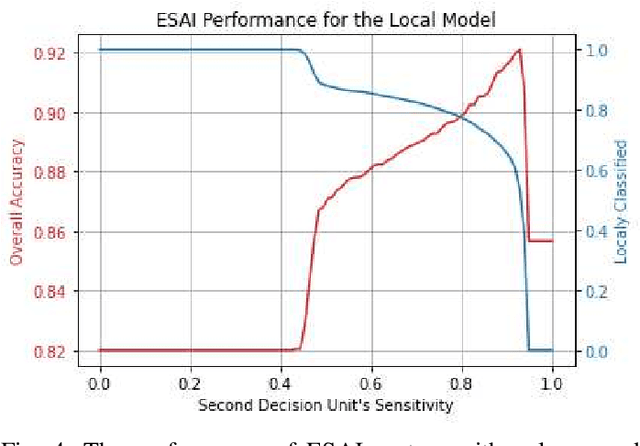
Recently, deep neural networks have been outperforming conventional machine learning algorithms in many computer vision-related tasks. However, it is not computationally acceptable to implement these models on mobile and IoT devices and the majority of devices are harnessing the cloud computing methodology in which outstanding deep learning models are responsible for analyzing the data on the server. This can bring the communication cost for the devices and make the whole system useless in those times where the communication is not available. In this paper, a new framework for deploying on IoT devices has been proposed which can take advantage of both the cloud and the on-device models by extracting the meta-information from each sample's classification result and evaluating the classification's performance for the necessity of sending the sample to the server. Experimental results show that only 40 percent of the test data should be sent to the server using this technique and the overall accuracy of the framework is 92 percent which improves the accuracy of both client and server models.
Discriminative Adversarial Domain Generalization with Meta-learning based Cross-domain Validation
Nov 01, 2020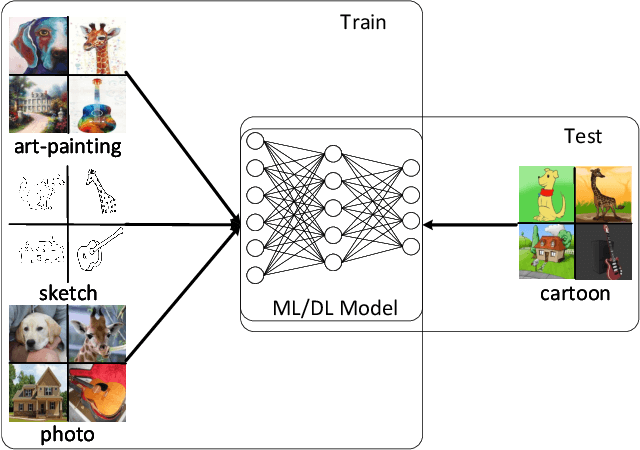
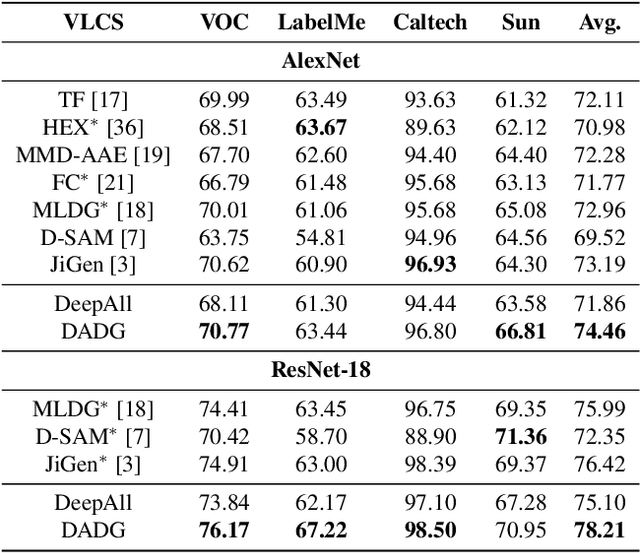
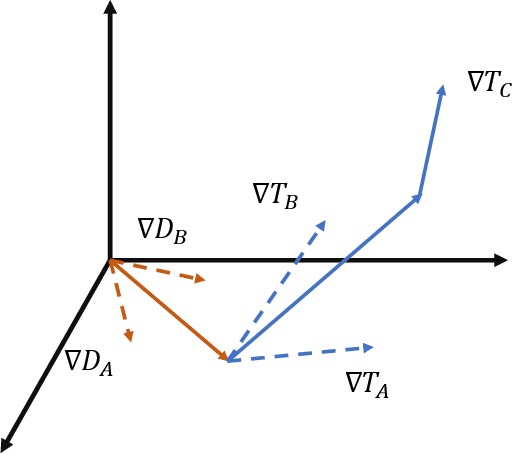
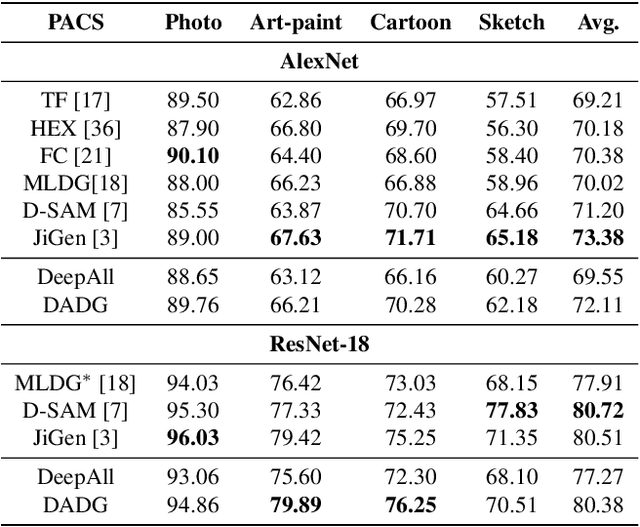
The generalization capability of machine learning models, which refers to generalizing the knowledge for an "unseen" domain via learning from one or multiple seen domain(s), is of great importance to develop and deploy machine learning applications in the real-world conditions. Domain Generalization (DG) techniques aim to enhance such generalization capability of machine learning models, where the learnt feature representation and the classifier are two crucial factors to improve generalization and make decisions. In this paper, we propose Discriminative Adversarial Domain Generalization (DADG) with meta-learning-based cross-domain validation. Our proposed framework contains two main components that work synergistically to build a domain-generalized DNN model: (i) discriminative adversarial learning, which proactively learns a generalized feature representation on multiple "seen" domains, and (ii) meta-learning based cross-domain validation, which simulates train/test domain shift via applying meta-learning techniques in the training process. In the experimental evaluation, a comprehensive comparison has been made among our proposed approach and other existing approaches on three benchmark datasets. The results shown that DADG consistently outperforms a strong baseline DeepAll, and outperforms the other existing DG algorithms in most of the evaluation cases.
Utility-aware Privacy-preserving Data Releasing
May 09, 2020
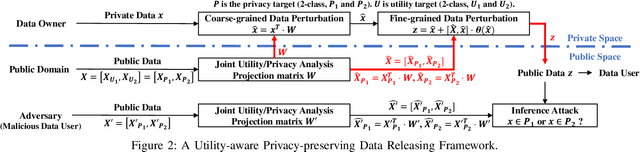
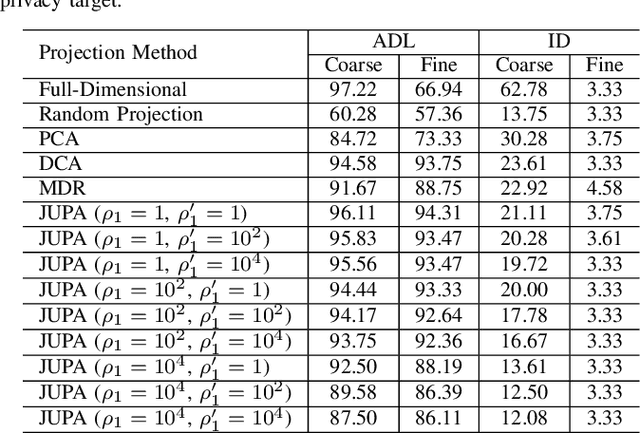

In the big data era, more and more cloud-based data-driven applications are developed that leverage individual data to provide certain valuable services (the utilities). On the other hand, since the same set of individual data could be utilized to infer the individual's certain sensitive information, it creates new channels to snoop the individual's privacy. Hence it is of great importance to develop techniques that enable the data owners to release privatized data, that can still be utilized for certain premised intended purpose. Existing data releasing approaches, however, are either privacy-emphasized (no consideration on utility) or utility-driven (no guarantees on privacy). In this work, we propose a two-step perturbation-based utility-aware privacy-preserving data releasing framework. First, certain predefined privacy and utility problems are learned from the public domain data (background knowledge). Later, our approach leverages the learned knowledge to precisely perturb the data owners' data into privatized data that can be successfully utilized for certain intended purpose (learning to succeed), without jeopardizing certain predefined privacy (training to fail). Extensive experiments have been conducted on Human Activity Recognition, Census Income and Bank Marketing datasets to demonstrate the effectiveness and practicality of our framework.
SAIA: Split Artificial Intelligence Architecture for Mobile Healthcare System
May 09, 2020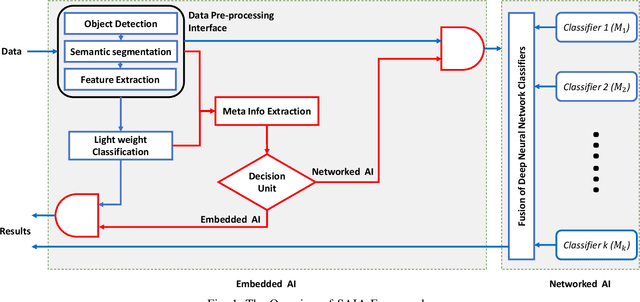
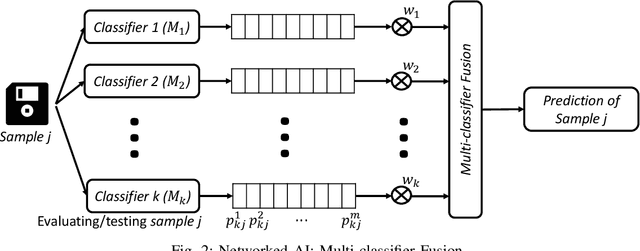
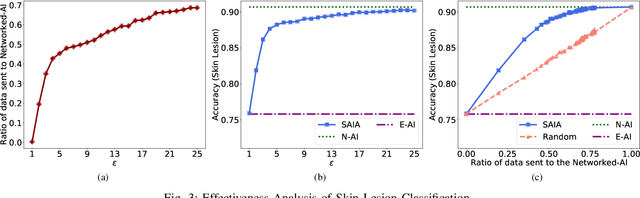
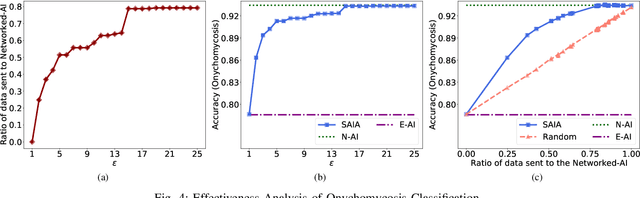
As the advancement of deep learning (DL), the Internet of Things and cloud computing techniques for biomedical and healthcare problems, mobile healthcare systems have received unprecedented attention. Since DL techniques usually require enormous amount of computation, most of them cannot be directly deployed on the resource-constrained mobile and IoT devices. Hence, most of the mobile healthcare systems leverage the cloud computing infrastructure, where the data collected by the mobile and IoT devices would be transmitted to the cloud computing platforms for analysis. However, in the contested environments, relying on the cloud might not be practical at all times. For instance, the satellite communication might be denied or disrupted. We propose SAIA, a Split Artificial Intelligence Architecture for mobile healthcare systems. Unlike traditional approaches for artificial intelligence (AI) which solely exploits the computational power of the cloud server, SAIA could not only relies on the cloud computing infrastructure while the wireless communication is available, but also utilizes the lightweight AI solutions that work locally on the client side, hence, it can work even when the communication is impeded. In SAIA, we propose a meta-information based decision unit, that could tune whether a sample captured by the client should be operated by the embedded AI (i.e., keeping on the client) or the networked AI (i.e., sending to the server), under different conditions. In our experimental evaluation, extensive experiments have been conducted on two popular healthcare datasets. Our results show that SAIA consistently outperforms its baselines in terms of both effectiveness and efficiency.