 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Meta-Learning-based Poisoning Attacks for Graph Link Prediction
Apr 08, 2025



Link prediction in graph data utilizes various algorithms and machine learning/deep learning models to predict potential relationships between graph nodes. This technique has found widespread use in numerous real-world applications, including recommendation systems, community networks, and biological structures. However, recent research has highlighted the vulnerability of link prediction models to adversarial attacks, such as poisoning and evasion attacks. Addressing the vulnerability of these models is crucial to ensure stable and robust performance in link prediction applications. While many works have focused on enhancing the robustness of the Graph Convolution Network (GCN) model, the Variational Graph Auto-Encoder (VGAE), a sophisticated model for link prediction, has not been thoroughly investigated in the context of graph adversarial attacks. To bridge this gap, this article proposes an unweighted graph poisoning attack approach using meta-learning techniques to undermine VGAE's link prediction performance. We conducted comprehensive experiments on diverse datasets to evaluate the proposed method and its parameters, comparing it with existing approaches in similar settings. Our results demonstrate that our approach significantly diminishes link prediction performance and outperforms other state-of-the-art methods.
Synthetic Information towards Maximum Posterior Ratio for deep learning on Imbalanced Data
Jan 05, 2024This study examines the impact of class-imbalanced data on deep learning models and proposes a technique for data balancing by generating synthetic data for the minority class. Unlike random-based oversampling, our method prioritizes balancing the informative regions by identifying high entropy samples. Generating well-placed synthetic data can enhance machine learning algorithms accuracy and efficiency, whereas poorly-placed ones may lead to higher misclassification rates. We introduce an algorithm that maximizes the probability of generating a synthetic sample in the correct region of its class by optimizing the class posterior ratio. Additionally, to maintain data topology, synthetic data are generated within each minority sample's neighborhood. Our experimental results on forty-one datasets demonstrate the superior performance of our technique in enhancing deep-learning models.
* Accepted to IEEE Transaction on Artificial Intelligence
Federated Learning for distribution skewed data using sample weights
Jan 05, 2024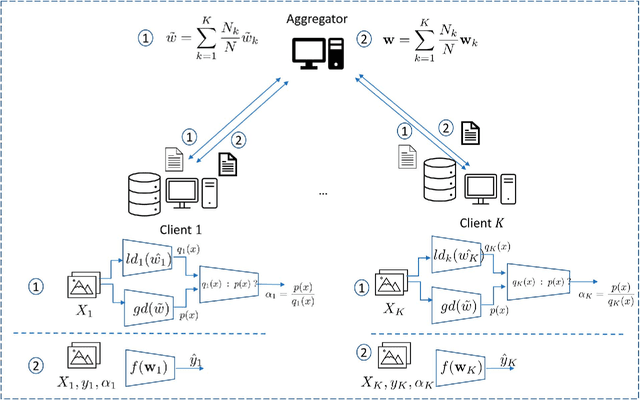
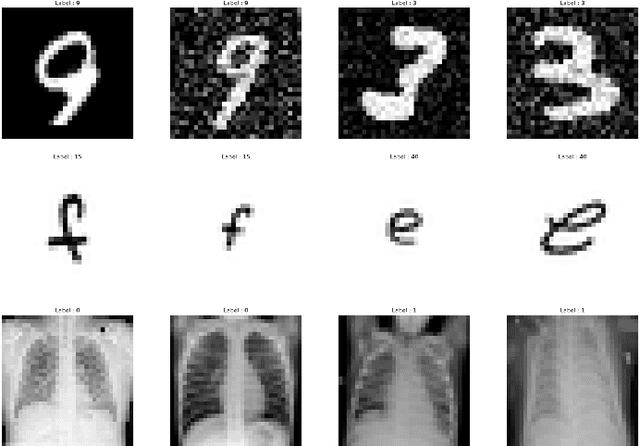
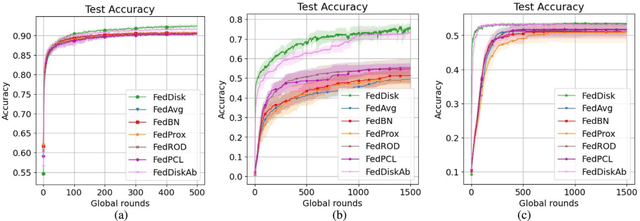
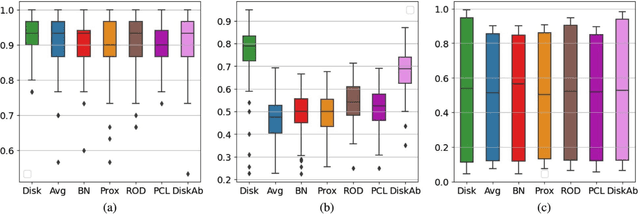
One of the most challenging issues in federated learning is that the data is often not independent and identically distributed (nonIID). Clients are expected to contribute the same type of data and drawn from one global distribution. However, data are often collected in different ways from different resources. Thus, the data distributions among clients might be different from the underlying global distribution. This creates a weight divergence issue and reduces federated learning performance. This work focuses on improving federated learning performance for skewed data distribution across clients. The main idea is to adjust the client distribution closer to the global distribution using sample weights. Thus, the machine learning model converges faster with higher accuracy. We start from the fundamental concept of empirical risk minimization and theoretically derive a solution for adjusting the distribution skewness using sample weights. To determine sample weights, we implicitly exchange density information by leveraging a neural network-based density estimation model, MADE. The clients data distribution can then be adjusted without exposing their raw data. Our experiment results on three real-world datasets show that the proposed method not only improves federated learning accuracy but also significantly reduces communication costs compared to the other experimental methods.
* Accepted to IEEE Transaction on Artificial Intelligence
Complementary Ensemble Learning
Nov 09, 2021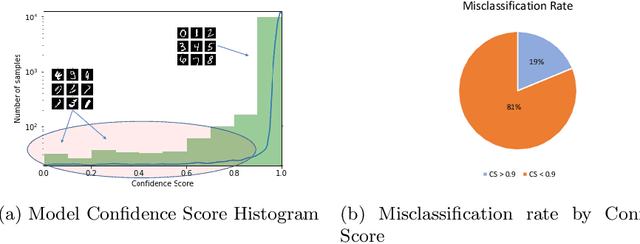
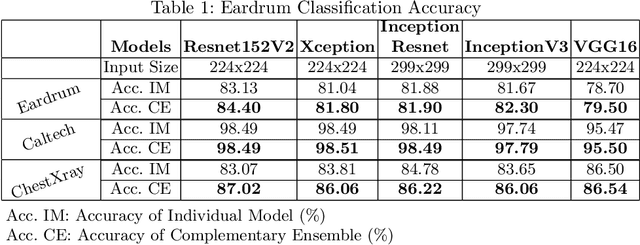

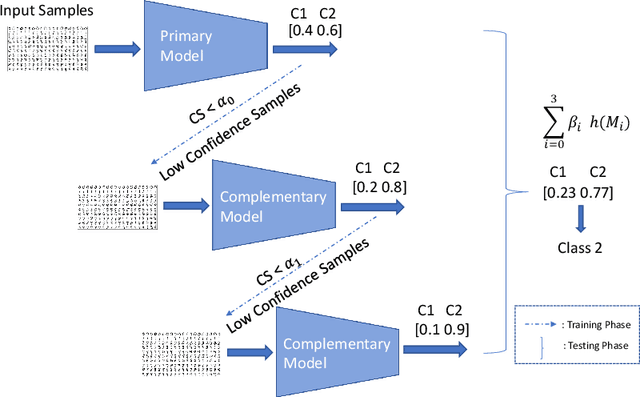
To achieve high performance of a machine learning (ML) task, a deep learning-based model must implicitly capture the entire distribution from data. Thus, it requires a huge amount of training samples, and data are expected to fully present the real distribution, especially for high dimensional data, e.g., images, videos. In practice, however, data are usually collected with a diversity of styles, and several of them have insufficient number of representatives. This might lead to uncertainty in models' prediction, and significantly reduce ML task performance. In this paper, we provide a comprehensive study on this problem by looking at model uncertainty. From this, we derive a simple but efficient technique to improve performance of state-of-the-art deep learning models. Specifically, we train auxiliary models which are able to complement state-of-the-art model uncertainty. As a result, by assembling these models, we can significantly improve the ML task performance for types of data mentioned earlier. While slightly improving ML classification accuracy on benchmark datasets (e.g., 0.2% on MNIST), our proposed method significantly improves on limited data (i.e., 1.3% on Eardrum and 3.5% on ChestXray).