 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Classroom Quality Assessment Leveraging IoT-Based Real-Time Student Monitoring
Mar 17, 2026This study presents high-throughput, real-time multi-agent affective computing framework designed to enhance classroom learning through emotional state monitoring. As large classroom sizes and limited teacher student interaction increasingly challenge educators, there is a growing need for scalable, data-driven tools capable of capturing students' emotional and engagement patterns in real time. The system was evaluated using the Classroom Emotion Dataset, consisting of 1,500 labeled images and 300 classroom detection videos. Tailored for IoT devices, the system addresses load balancing and latency challenges through efficient real-time processing. Field testing was conducted across three educational institutions in a large metropolitan area: a primary school (hereafter school A), a secondary school (school B), and a high school (school C). The system demonstrated robust performance, detecting up to 50 faces at 25 FPS and achieving 88% overall accuracy in classifying classroom engagement states. Implementation results showed positive outcomes, with favorable feedback from students, teachers, and parents regarding improved classroom interaction and teaching adaptation. Key contributions of this research include establishing a practical, IoT-based framework for emotion-aware learning environments and introducing the 'Classroom Emotion Dataset' to facilitate further validation and research.
Boltzmann-based Exploration for Robust Decentralized Multi-Agent Planning
Mar 02, 2026Decentralized Monte Carlo Tree Search (Dec-MCTS) is widely used for cooperative multi-agent planning but struggles in sparse or skewed reward environments. We introduce Coordinated Boltzmann MCTS (CB-MCTS), which replaces deterministic UCT with a stochastic Boltzmann policy and a decaying entropy bonus for sustained yet focused exploration. While Boltzmann exploration has been studied in single-agent MCTS, applying it in multi-agent systems poses unique challenges. CB-MCTS is the first to address this. We analyze CB-MCTS in the simple-regret setting and show in simulations that it outperforms Dec-MCTS in deceptive scenarios and remains competitive on standard benchmarks, providing a robust solution for multi-agent planning.
Acceleration-Based Control of Fixed-Wing UAVs for Guidance Applications
Feb 27, 2026Acceleration-commanded guidance laws (e.g., proportional navigation) are attractive for high-level decision making, but their direct deployment on fixed-wing UAVs is challenging because accelerations are not directly actuated and must be realized through attitude and thrust under flight-envelope constraints. This paper presents an acceleration-level outer-loop control framework that converts commanded tangential and normal accelerations into executable body-rate and normalized thrust commands compatible with mainstream autopilots (e.g., PX4/APM). For the normal channel, we derive an engineering mapping from the desired normal acceleration to roll- and pitch-rate commands that regulate the direction and magnitude of the lift vector under small-angle assumptions. For the tangential channel, we introduce an energy-based formulation inspired by total energy control and identify an empirical thrust-energy acceleration relationship directly from flight data, avoiding explicit propulsion modeling or thrust bench calibration. We further discuss priority handling between normal and tangential accelerations under saturation and non-level maneuvers. Extensive real-flight experiments on a VTOL fixed-wing platform demonstrate accurate acceleration tracking and enable practical implementation of proportional navigation using only body-rate and normalized thrust interfaces.
Learnable Multi-level Discrete Wavelet Transforms for 3D Gaussian Splatting Frequency Modulation
Feb 15, 20263D Gaussian Splatting (3DGS) has emerged as a powerful approach for novel view synthesis. However, the number of Gaussian primitives often grows substantially during training as finer scene details are reconstructed, leading to increased memory and storage costs. Recent coarse-to-fine strategies regulate Gaussian growth by modulating the frequency content of the ground-truth images. In particular, AutoOpti3DGS employs the learnable Discrete Wavelet Transform (DWT) to enable data-adaptive frequency modulation. Nevertheless, its modulation depth is limited by the 1-level DWT, and jointly optimizing wavelet regularization with 3D reconstruction introduces gradient competition that promotes excessive Gaussian densification. In this paper, we propose a multi-level DWT-based frequency modulation framework for 3DGS. By recursively decomposing the low-frequency subband, we construct a deeper curriculum that provides progressively coarser supervision during early training, consistently reducing Gaussian counts. Furthermore, we show that the modulation can be performed using only a single scaling parameter, rather than learning the full 2-tap high-pass filter. Experimental results on standard benchmarks demonstrate that our method further reduces Gaussian counts while maintaining competitive rendering quality.
Heart2Mind: Human-Centered Contestable Psychiatric Disorder Diagnosis System using Wearable ECG Monitors
May 16, 2025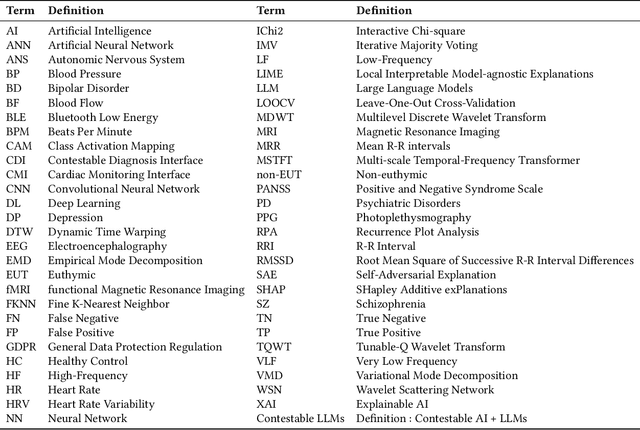
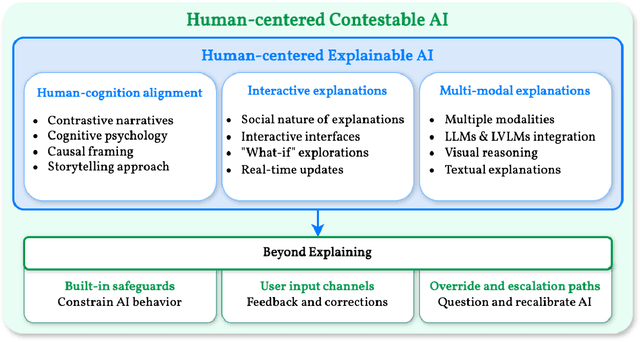
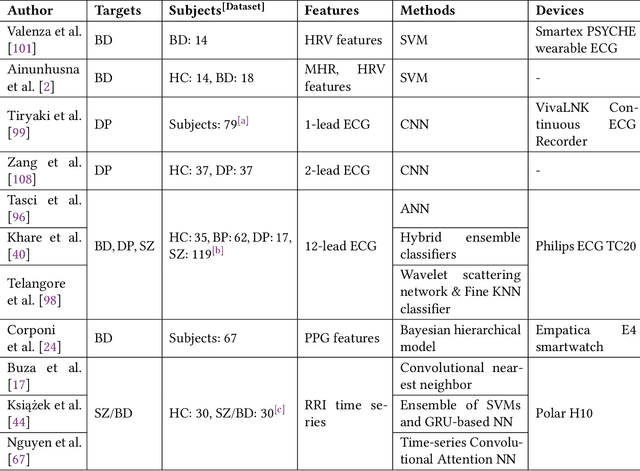
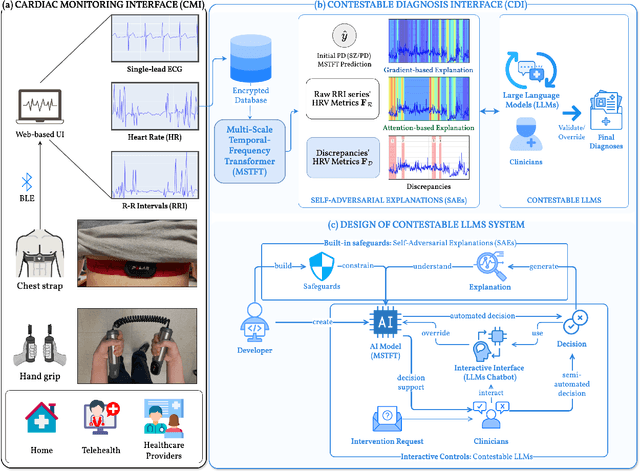
Psychiatric disorders affect millions globally, yet their diagnosis faces significant challenges in clinical practice due to subjective assessments and accessibility concerns, leading to potential delays in treatment. To help address this issue, we present Heart2Mind, a human-centered contestable psychiatric disorder diagnosis system using wearable electrocardiogram (ECG) monitors. Our approach leverages cardiac biomarkers, particularly heart rate variability (HRV) and R-R intervals (RRI) time series, as objective indicators of autonomic dysfunction in psychiatric conditions. The system comprises three key components: (1) a Cardiac Monitoring Interface (CMI) for real-time data acquisition from Polar H9/H10 devices; (2) a Multi-Scale Temporal-Frequency Transformer (MSTFT) that processes RRI time series through integrated time-frequency domain analysis; (3) a Contestable Diagnosis Interface (CDI) combining Self-Adversarial Explanations (SAEs) with contestable Large Language Models (LLMs). Our MSTFT achieves 91.7% accuracy on the HRV-ACC dataset using leave-one-out cross-validation, outperforming state-of-the-art methods. SAEs successfully detect inconsistencies in model predictions by comparing attention-based and gradient-based explanations, while LLMs enable clinicians to validate correct predictions and contest erroneous ones. This work demonstrates the feasibility of combining wearable technology with Explainable Artificial Intelligence (XAI) and contestable LLMs to create a transparent, contestable system for psychiatric diagnosis that maintains clinical oversight while leveraging advanced AI capabilities. Our implementation is publicly available at: https://github.com/Analytics-Everywhere-Lab/heart2mind.
Adaptive Wizard for Removing Cross-Tier Misconfigurations in Active Directory
May 02, 2025Security vulnerabilities in Windows Active Directory (AD) systems are typically modeled using an attack graph and hardening AD systems involves an iterative workflow: security teams propose an edge to remove, and IT operations teams manually review these fixes before implementing the removal. As verification requires significant manual effort, we formulate an Adaptive Path Removal Problem to minimize the number of steps in this iterative removal process. In our model, a wizard proposes an attack path in each step and presents it as a set of multiple-choice options to the IT admin. The IT admin then selects one edge from the proposed set to remove. This process continues until the target $t$ is disconnected from source $s$ or the number of proposed paths reaches $B$. The model aims to optimize the human effort by minimizing the expected number of interactions between the IT admin and the security wizard. We first prove that the problem is $\mathcal{\#P}$-hard. We then propose a set of solutions including an exact algorithm, an approximate algorithm, and several scalable heuristics. Our best heuristic, called DPR, can operate effectively on larger-scale graphs compared to the exact algorithm and consistently outperforms the approximate algorithm across all graphs. We verify the effectiveness of our algorithms on several synthetic AD graphs and an AD attack graph collected from a real organization.
Characterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
SwiftTry: Fast and Consistent Video Virtual Try-On with Diffusion Models
Dec 13, 2024



Given an input video of a person and a new garment, the objective of this paper is to synthesize a new video where the person is wearing the specified garment while maintaining spatiotemporal consistency. While significant advances have been made in image-based virtual try-ons, extending these successes to video often results in frame-to-frame inconsistencies. Some approaches have attempted to address this by increasing the overlap of frames across multiple video chunks, but this comes at a steep computational cost due to the repeated processing of the same frames, especially for long video sequence. To address these challenges, we reconceptualize video virtual try-on as a conditional video inpainting task, with garments serving as input conditions. Specifically, our approach enhances image diffusion models by incorporating temporal attention layers to improve temporal coherence. To reduce computational overhead, we introduce ShiftCaching, a novel technique that maintains temporal consistency while minimizing redundant computations. Furthermore, we introduce the \dataname~dataset, a new video try-on dataset featuring more complex backgrounds, challenging movements, and higher resolution compared to existing public datasets. Extensive experiments show that our approach outperforms current baselines, particularly in terms of video consistency and inference speed. Data and code are available at https://github.com/VinAIResearch/swift-try
Long-Term 3D Point Tracking By Cost Volume Fusion
Jul 18, 2024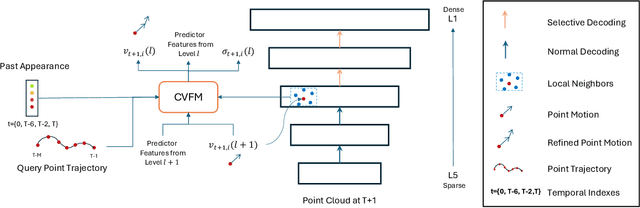
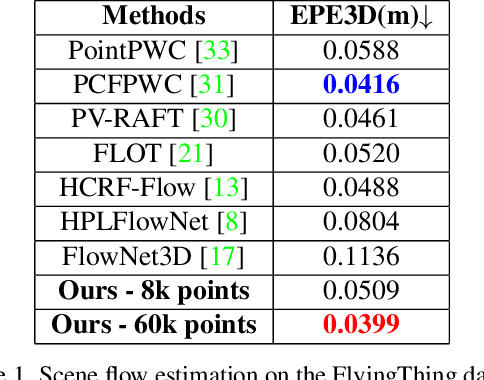
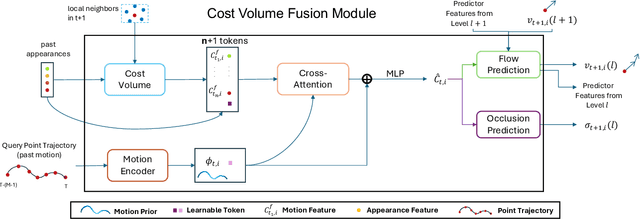
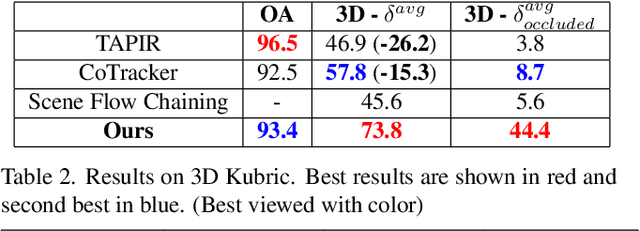
Long-term point tracking is essential to understand non-rigid motion in the physical world better. Deep learning approaches have recently been incorporated into long-term point tracking, but most prior work predominantly functions in 2D. Although these methods benefit from the well-established backbones and matching frameworks, the motions they produce do not always make sense in the 3D physical world. In this paper, we propose the first deep learning framework for long-term point tracking in 3D that generalizes to new points and videos without requiring test-time fine-tuning. Our model contains a cost volume fusion module that effectively integrates multiple past appearances and motion information via a transformer architecture, significantly enhancing overall tracking performance. In terms of 3D tracking performance, our model significantly outperforms simple scene flow chaining and previous 2D point tracking methods, even if one uses ground truth depth and camera pose to backproject 2D point tracks in a synthetic scenario.
United We Stand: Decentralized Multi-Agent Planning With Attrition
Jul 11, 2024



Decentralized planning is a key element of cooperative multi-agent systems for information gathering tasks. However, despite the high frequency of agent failures in realistic large deployment scenarios, current approaches perform poorly in the presence of failures, by not converging at all, and/or by making very inefficient use of resources (e.g. energy). In this work, we propose Attritable MCTS (A-MCTS), a decentralized MCTS algorithm capable of timely and efficient adaptation to changes in the set of active agents. It is based on the use of a global reward function for the estimation of each agent's local contribution, and regret matching for coordination. We evaluate its effectiveness in realistic data-harvesting problems under different scenarios. We show both theoretically and experimentally that A-MCTS enables efficient adaptation even under high failure rates. Results suggest that, in the presence of frequent failures, our solution improves substantially over the best existing approaches in terms of global utility and scalability.