 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Multi-Agent Algorithmic Care Systems Demand Contestability for Trustworthy AI
Mar 21, 2026Multi-agent systems (MAS) are increasingly used in healthcare to support complex decision-making through collaboration among specialized agents. Because these systems act as collective decision-makers, they raise challenges for trust, accountability, and human oversight. Existing approaches to trustworthy AI largely rely on explainability, but explainability alone is insufficient in multi-agent settings, as it does not enable care partners to challenge or correct system outputs. To address this limitation, Contestable AI (CAI) characterizes systems that support effective human challenge throughout the decision-making lifecycle by providing transparency, structured opportunities for intervention, and mechanisms for review, correction, or override. This position paper argues that contestability is a necessary design requirement for trustworthy multi-agent algorithmic care systems. We identify key limitations in current MAS and Explainable AI (XAI) research and present a human-in-the-loop framework that integrates structured argumentation and role-based contestation to preserve human agency, clinical responsibility, and trust in high-stakes care contexts.
Adaptive Collaboration of Arena-Based Argumentative LLMs for Explainable and Contestable Legal Reasoning
Feb 21, 2026Legal reasoning requires not only high accuracy but also the ability to justify decisions through verifiable and contestable arguments. However, existing Large Language Model (LLM) approaches, such as Chain-of-Thought (CoT) and Retrieval-Augmented Generation (RAG), often produce unstructured explanations that lack a formal mechanism for verification or user intervention. To address this limitation, we propose Adaptive Collaboration of Argumentative LLMs (ACAL), a neuro-symbolic framework that integrates adaptive multi-agent collaboration with an Arena-based Quantitative Bipolar Argumentation Framework (A-QBAF). ACAL dynamically deploys expert agent teams to construct arguments, employs a clash resolution mechanism to adjudicate conflicting claims, and utilizes uncertainty-aware escalation for borderline cases. Crucially, our framework supports a Human-in-the-Loop (HITL) contestability workflow, enabling users to directly audit and modify the underlying reasoning graph to influence the final judgment. Empirical evaluations on the LegalBench benchmark demonstrate that ACAL outperforms strong baselines across Gemini-2.5-Flash-Lite and Gemini-2.5-Flash architectures, effectively balancing efficient predictive performance with structured transparency and contestability. Our implementation is available at: https://github.com/loc110504/ACAL.
Enhancing Alzheimer's Detection through Late Fusion of Multi-Modal EEG Features
Dec 17, 2025
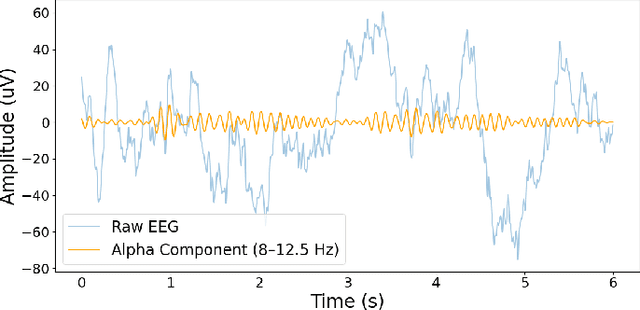
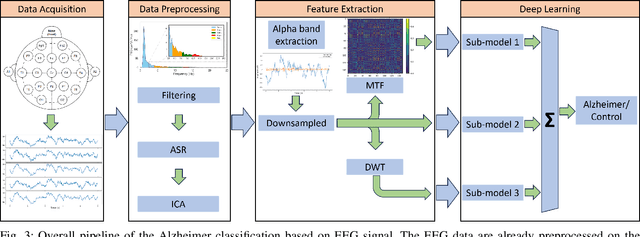
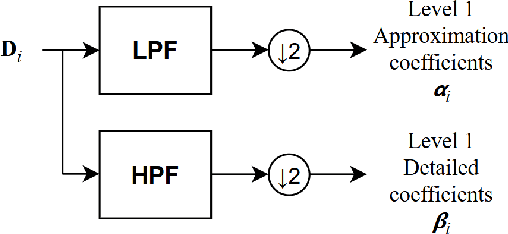
Alzheimer s disease (AD) is a progressive neurodegenerative disorder characterized by cognitive decline, where early detection is essential for timely intervention and improved patient outcomes. Traditional diagnostic methods are time-consuming and require expert interpretation, thus, automated approaches are highly desirable. This study presents a novel deep learning framework for AD diagnosis using Electroencephalograph (EEG) signals, integrating multiple feature extraction techniques including alpha-wave analysis, Discrete Wavelet Transform (DWT), and Markov Transition Fields (MTF). A late-fusion strategy is employed to combine predictions from separate neural networks trained on these diverse representations, capturing both temporal and frequency-domain patterns in the EEG data. The proposed model attains a classification accuracy of 87.23%, with a precision of 87.95%, a recall of 86.91%, and an F1 score of 87.42% when evaluated on a publicly available dataset, demonstrating its potential for reliable, scalable, and early AD screening. Rigorous preprocessing and targeted frequency band selection, particularly in the alpha range due to its cognitive relevance, further enhance performance. This work highlights the promise of deep learning in supporting physicians with efficient and accessible tools for early AD diagnosis.
Investigation of Using Non-Contact Electrodes for Fetal ECG Monitoring
Oct 01, 2025



Regular physiological monitoring of maternal and fetal parameters is indispensable for ensuring safe outcomes during pregnancy and parturition. Fetal electrocardiogram (fECG) assessment is crucial to detect fetal distress and developmental anomalies. Given challenges of prenatal care due to the lack of medical professionals and the limit of accessibility, especially in remote and resource-poor areas, we develop a fECG monitoring system using novel non-contact electrodes (NCE) to record the fetal/maternal ECG (f/mECG) signals through clothes, thereby improving the comfort during measurement. The system is designed to be incorporated inside a maternity belt with data acquisition, data transmission module as well as novel NCEs. Thorough characterizations were carried out to evaluate the novel NCE against traditional wet electrodes (i.e., Ag/AgCl electrodes), showing comparable performance. A successful {preliminary pilot feasibility study} conducted with pregnant women (n = 10) between 25 and 32 weeks of gestation demonstrates the system's performance, usability and safety.
Heart2Mind: Human-Centered Contestable Psychiatric Disorder Diagnosis System using Wearable ECG Monitors
May 16, 2025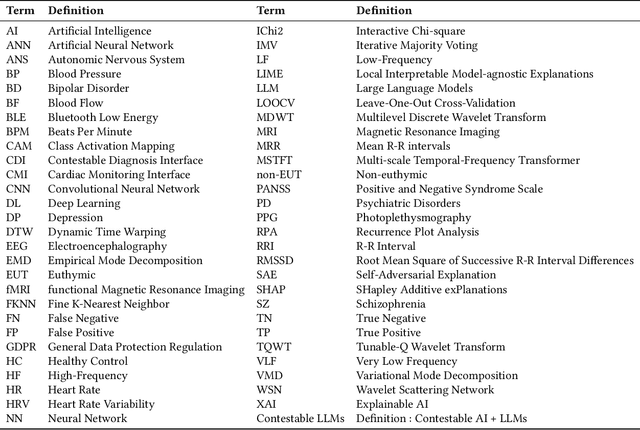
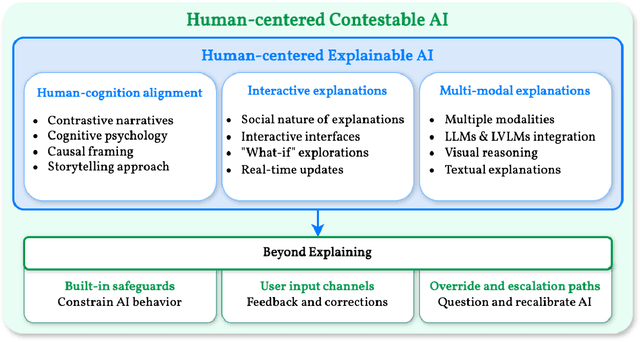
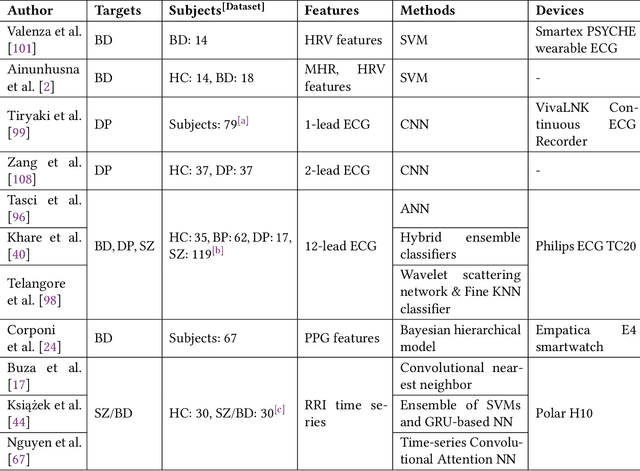
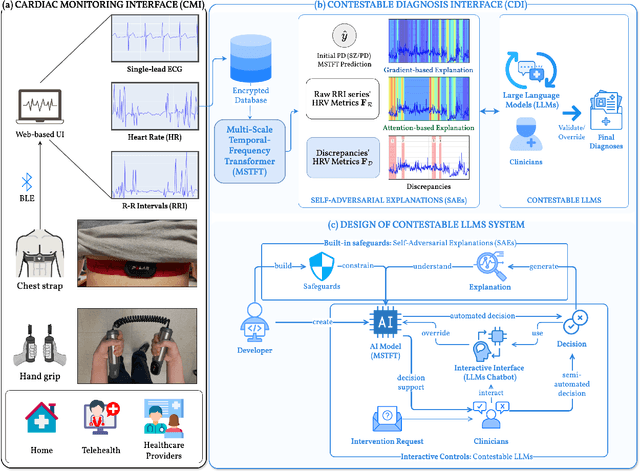
Psychiatric disorders affect millions globally, yet their diagnosis faces significant challenges in clinical practice due to subjective assessments and accessibility concerns, leading to potential delays in treatment. To help address this issue, we present Heart2Mind, a human-centered contestable psychiatric disorder diagnosis system using wearable electrocardiogram (ECG) monitors. Our approach leverages cardiac biomarkers, particularly heart rate variability (HRV) and R-R intervals (RRI) time series, as objective indicators of autonomic dysfunction in psychiatric conditions. The system comprises three key components: (1) a Cardiac Monitoring Interface (CMI) for real-time data acquisition from Polar H9/H10 devices; (2) a Multi-Scale Temporal-Frequency Transformer (MSTFT) that processes RRI time series through integrated time-frequency domain analysis; (3) a Contestable Diagnosis Interface (CDI) combining Self-Adversarial Explanations (SAEs) with contestable Large Language Models (LLMs). Our MSTFT achieves 91.7% accuracy on the HRV-ACC dataset using leave-one-out cross-validation, outperforming state-of-the-art methods. SAEs successfully detect inconsistencies in model predictions by comparing attention-based and gradient-based explanations, while LLMs enable clinicians to validate correct predictions and contest erroneous ones. This work demonstrates the feasibility of combining wearable technology with Explainable Artificial Intelligence (XAI) and contestable LLMs to create a transparent, contestable system for psychiatric diagnosis that maintains clinical oversight while leveraging advanced AI capabilities. Our implementation is publicly available at: https://github.com/Analytics-Everywhere-Lab/heart2mind.
ODExAI: A Comprehensive Object Detection Explainable AI Evaluation
Apr 27, 2025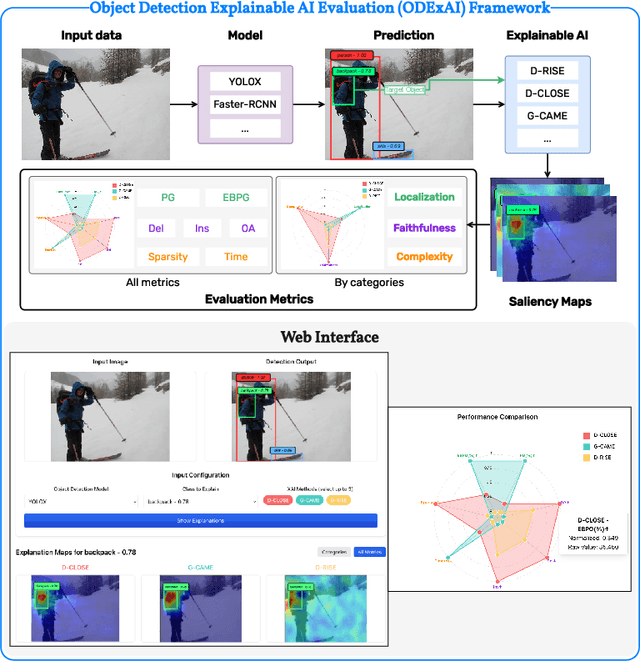
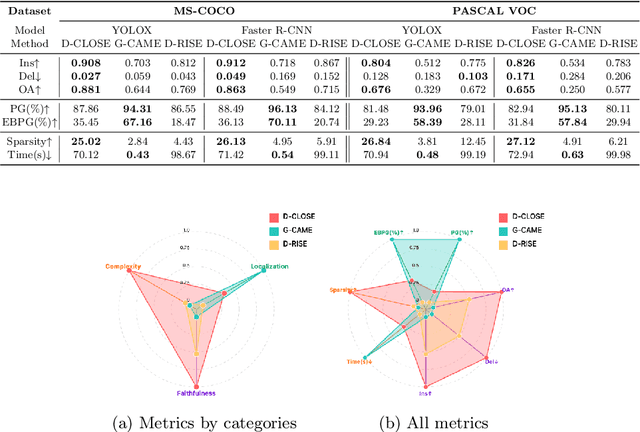
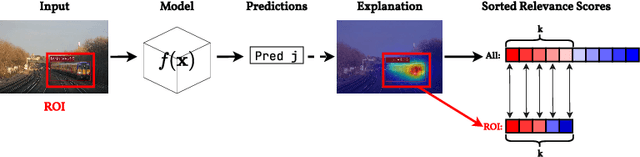
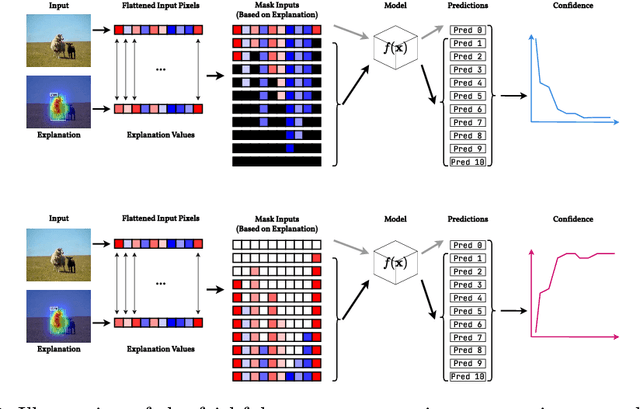
Explainable Artificial Intelligence (XAI) techniques for interpreting object detection models remain in an early stage, with no established standards for systematic evaluation. This absence of consensus hinders both the comparative analysis of methods and the informed selection of suitable approaches. To address this gap, we introduce the Object Detection Explainable AI Evaluation (ODExAI), a comprehensive framework designed to assess XAI methods in object detection based on three core dimensions: localization accuracy, faithfulness to model behavior, and computational complexity. We benchmark a set of XAI methods across two widely used object detectors (YOLOX and Faster R-CNN) and standard datasets (MS-COCO and PASCAL VOC). Empirical results demonstrate that region-based methods (e.g., D-CLOSE) achieve strong localization (PG = 88.49%) and high model faithfulness (OA = 0.863), though with substantial computational overhead (Time = 71.42s). On the other hand, CAM-based methods (e.g., G-CAME) achieve superior localization (PG = 96.13%) and significantly lower runtime (Time = 0.54s), but at the expense of reduced faithfulness (OA = 0.549). These findings demonstrate critical trade-offs among existing XAI approaches and reinforce the need for task-specific evaluation when deploying them in object detection pipelines. Our implementation and evaluation benchmarks are publicly available at: https://github.com/Analytics-Everywhere-Lab/odexai.
Encoded Spatial Attribute in Multi-Tier Federated Learning
Jan 10, 2025This research presents an Encoded Spatial Multi-Tier Federated Learning approach for a comprehensive evaluation of aggregated models for geospatial data. In the client tier, encoding spatial information is introduced to better predict the target outcome. The research aims to assess the performance of these models across diverse datasets and spatial attributes, highlighting variations in predictive accuracy. Using evaluation metrics such as accuracy, our research reveals insights into the complexities of spatial granularity and the challenges of capturing underlying patterns in the data. We extended the scope of federated learning (FL) by having multi-tier along with the functionality of encoding spatial attributes. Our N-tier FL approach used encoded spatial data to aggregate in different tiers. We obtained multiple models that predicted the different granularities of spatial data. Our findings underscore the need for further research to improve predictive accuracy and model generalization, with potential avenues including incorporating additional features, refining model architectures, and exploring alternative modeling approaches. Our experiments have several tiers representing different levels of spatial aspects. We obtained accuracy of 75.62% and 89.52% for the global model without having to train the model using the data constituted with the designated tier. The research also highlights the importance of the proposed approach in real-time applications.
High-Precision UWB-Based Real-Time Locating System for Rodent Behavioral Studies in Naturalistic Habitats
Sep 03, 2024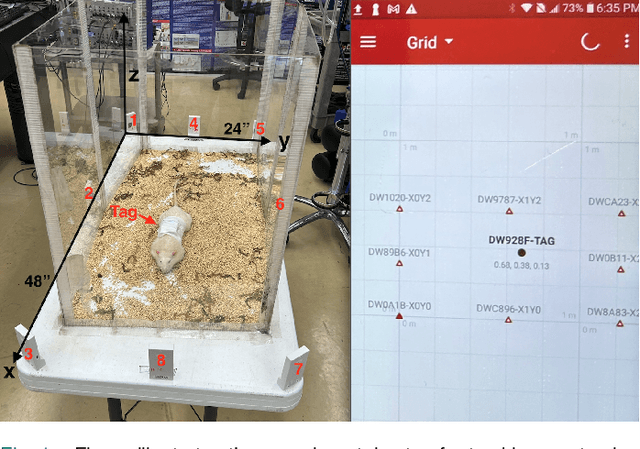
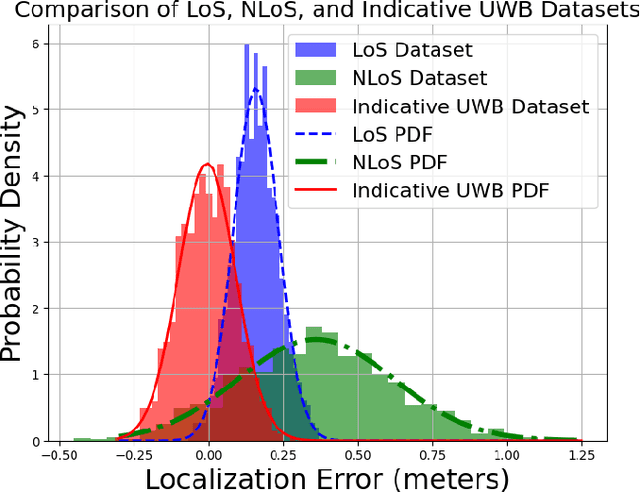
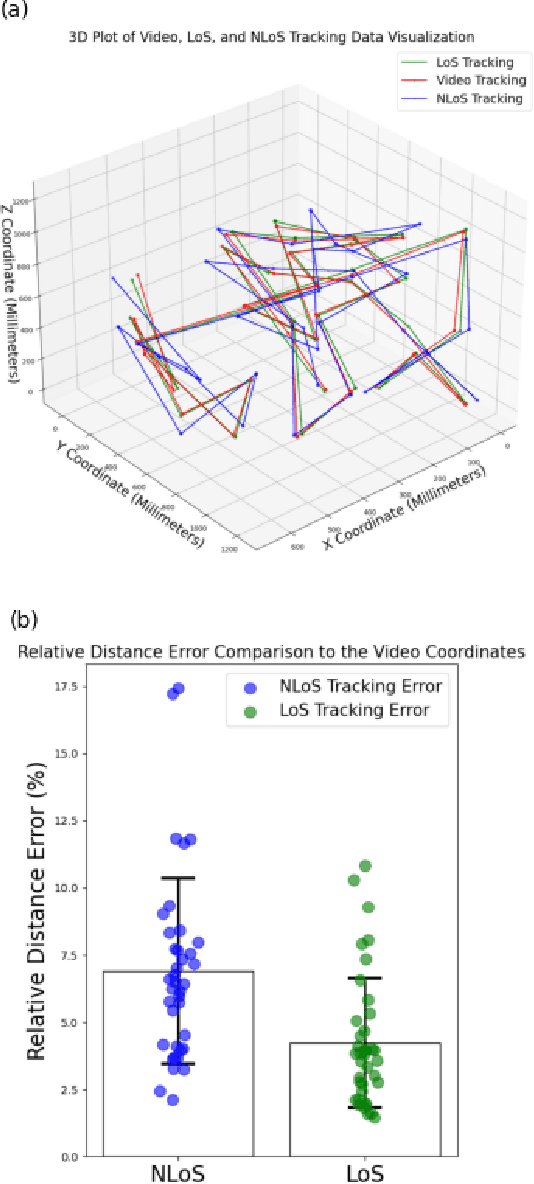
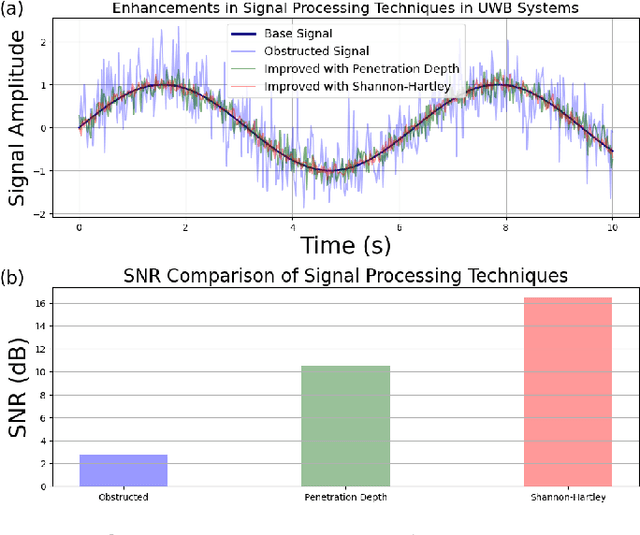
Rodent has proven to be the premier model for behavioral studies. Rats and mice have been raised and maintained in conventional cage environment for investigations. In contrast, the enhanced naturalistic habitat has been demonstrated to be a better setting, especially when behaviors and social interactions are desired. The habitat enables rodents to perform all natural activities with intrinsic phenotypes and importantly, interactions among individuals. The important elements of behavioral studies related to animals is to have precise tracking and collect accurate signals of multiple animals during interactions. Most of the existing approaches use video tracking and thus often face difficulties as rodents are nocturnal and often stay in tunnels underground. Here, we employed the ultra wideband technology to establish a novel tracking method for both overground and underground circumstances. UWB model DWM1001C was used with a custom-made device worn by the animal. A simplified habitat with a size of four-by-two feet was designed to demonstrate the performance of the system. The study evaluated the positioning system accuracy errors below one centimeter for LoS and less than ten centimeters for the NLoS. Generally, this work provides a more accurate and proven experiment to localize the moving object in the indoor building with concrete structures and signal processing data and introduces novel advancement techniques to the use of UWB.
XEdgeAI: A Human-centered Industrial Inspection Framework with Data-centric Explainable Edge AI Approach
Jul 16, 2024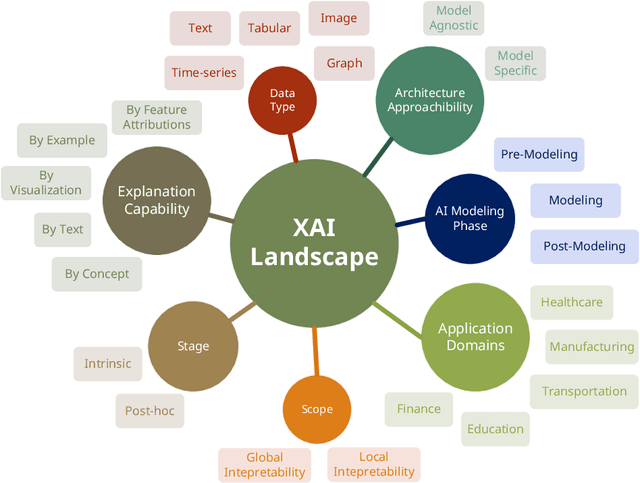



Recent advancements in deep learning have significantly improved visual quality inspection and predictive maintenance within industrial settings. However, deploying these technologies on low-resource edge devices poses substantial challenges due to their high computational demands and the inherent complexity of Explainable AI (XAI) methods. This paper addresses these challenges by introducing a novel XAI-integrated Visual Quality Inspection framework that optimizes the deployment of semantic segmentation models on low-resource edge devices. Our framework incorporates XAI and the Large Vision Language Model to deliver human-centered interpretability through visual and textual explanations to end-users. This is crucial for end-user trust and model interpretability. We outline a comprehensive methodology consisting of six fundamental modules: base model fine-tuning, XAI-based explanation generation, evaluation of XAI approaches, XAI-guided data augmentation, development of an edge-compatible model, and the generation of understandable visual and textual explanations. Through XAI-guided data augmentation, the enhanced model incorporating domain expert knowledge with visual and textual explanations is successfully deployed on mobile devices to support end-users in real-world scenarios. Experimental results showcase the effectiveness of the proposed framework, with the mobile model achieving competitive accuracy while significantly reducing model size. This approach paves the way for the broader adoption of reliable and interpretable AI tools in critical industrial applications, where decisions must be both rapid and justifiable.
An Adaptive Indoor Localization Approach Using WiFi RSSI Fingerprinting with SLAM-Enabled Robotic Platform and Deep Neural Networks
Jul 12, 2024Indoor localization plays a vital role in the era of the IoT and robotics, with WiFi technology being a prominent choice due to its ubiquity. We present a method for creating WiFi fingerprinting datasets to enhance indoor localization systems and address the gap in WiFi fingerprinting dataset creation. We used the Simultaneous Localization And Mapping (SLAM) algorithm and employed a robotic platform to construct precise maps and localize robots in indoor environments. We developed software applications to facilitate data acquisition, fingerprinting dataset collection, and accurate ground truth map building. Subsequently, we aligned the spatial information generated via the SLAM with the WiFi scans to create a comprehensive WiFi fingerprinting dataset. The created dataset was used to train a deep neural network (DNN) for indoor localization, which can prove the usefulness of grid density. We conducted experimental validation within our office environment to demonstrate the proposed method's effectiveness, including a heatmap from the dataset showcasing the spatial distribution of WiFi signal strengths for the testing access points placed within the environment. Notably, our method offers distinct advantages over existing approaches as it eliminates the need for a predefined map of the environment, requires no preparatory steps, lessens human intervention, creates a denser fingerprinting dataset, and reduces the WiFi fingerprinting dataset creation time. Our method achieves 26% more accurate localization than the other methods and can create a six times denser fingerprinting dataset in one-third of the time compared to the traditional method. In summary, using WiFi RSSI Fingerprinting data surveyed by the SLAM-Enabled Robotic Platform, we can adapt our trained DNN model to indoor localization in any dynamic environment and enhance its scalability and applicability in real-world scenarios.