 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoded Spatial Attribute in Multi-Tier Federated Learning
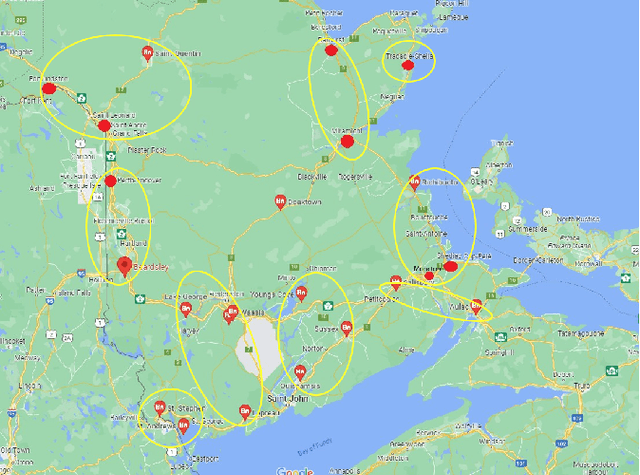
Jan 10, 2025This research presents an Encoded Spatial Multi-Tier Federated Learning approach for a comprehensive evaluation of aggregated models for geospatial data. In the client tier, encoding spatial information is introduced to better predict the target outcome. The research aims to assess the performance of these models across diverse datasets and spatial attributes, highlighting variations in predictive accuracy. Using evaluation metrics such as accuracy, our research reveals insights into the complexities of spatial granularity and the challenges of capturing underlying patterns in the data. We extended the scope of federated learning (FL) by having multi-tier along with the functionality of encoding spatial attributes. Our N-tier FL approach used encoded spatial data to aggregate in different tiers. We obtained multiple models that predicted the different granularities of spatial data. Our findings underscore the need for further research to improve predictive accuracy and model generalization, with potential avenues including incorporating additional features, refining model architectures, and exploring alternative modeling approaches. Our experiments have several tiers representing different levels of spatial aspects. We obtained accuracy of 75.62% and 89.52% for the global model without having to train the model using the data constituted with the designated tier. The research also highlights the importance of the proposed approach in real-time applications.
An Adaptive Indoor Localization Approach Using WiFi RSSI Fingerprinting with SLAM-Enabled Robotic Platform and Deep Neural Networks
Jul 12, 2024Indoor localization plays a vital role in the era of the IoT and robotics, with WiFi technology being a prominent choice due to its ubiquity. We present a method for creating WiFi fingerprinting datasets to enhance indoor localization systems and address the gap in WiFi fingerprinting dataset creation. We used the Simultaneous Localization And Mapping (SLAM) algorithm and employed a robotic platform to construct precise maps and localize robots in indoor environments. We developed software applications to facilitate data acquisition, fingerprinting dataset collection, and accurate ground truth map building. Subsequently, we aligned the spatial information generated via the SLAM with the WiFi scans to create a comprehensive WiFi fingerprinting dataset. The created dataset was used to train a deep neural network (DNN) for indoor localization, which can prove the usefulness of grid density. We conducted experimental validation within our office environment to demonstrate the proposed method's effectiveness, including a heatmap from the dataset showcasing the spatial distribution of WiFi signal strengths for the testing access points placed within the environment. Notably, our method offers distinct advantages over existing approaches as it eliminates the need for a predefined map of the environment, requires no preparatory steps, lessens human intervention, creates a denser fingerprinting dataset, and reduces the WiFi fingerprinting dataset creation time. Our method achieves 26% more accurate localization than the other methods and can create a six times denser fingerprinting dataset in one-third of the time compared to the traditional method. In summary, using WiFi RSSI Fingerprinting data surveyed by the SLAM-Enabled Robotic Platform, we can adapt our trained DNN model to indoor localization in any dynamic environment and enhance its scalability and applicability in real-world scenarios.
Achieving Pareto Optimality using Efficient Parameter Reduction for DNNs in Resource-Constrained Edge Environment
Mar 14, 2024This paper proposes an optimization of an existing Deep Neural Network (DNN) that improves its hardware utilization and facilitates on-device training for resource-constrained edge environments. We implement efficient parameter reduction strategies on Xception that shrink the model size without sacrificing accuracy, thus decreasing memory utilization during training. We evaluate our model in two experiments: Caltech-101 image classification and PCB defect detection and compare its performance against the original Xception and lightweight models, EfficientNetV2B1 and MobileNetV2. The results of the Caltech-101 image classification show that our model has a better test accuracy (76.21%) than Xception (75.89%), uses less memory on average (847.9MB) than Xception (874.6MB), and has faster training and inference times. The lightweight models overfit with EfficientNetV2B1 having a 30.52% test accuracy and MobileNetV2 having a 58.11% test accuracy. Both lightweight models have better memory usage than our model and Xception. On the PCB defect detection, our model has the best test accuracy (90.30%), compared to Xception (88.10%), EfficientNetV2B1 (55.25%), and MobileNetV2 (50.50%). MobileNetV2 has the least average memory usage (849.4MB), followed by our model (865.8MB), then EfficientNetV2B1 (874.8MB), and Xception has the highest (893.6MB). We further experiment with pre-trained weights and observe that memory usage decreases thereby showing the benefits of transfer learning. A Pareto analysis of the models' performance shows that our optimized model architecture satisfies accuracy and low memory utilization objectives.
Evaluating Multi-Global Server Architecture for Federated Learning
Nov 26, 2023
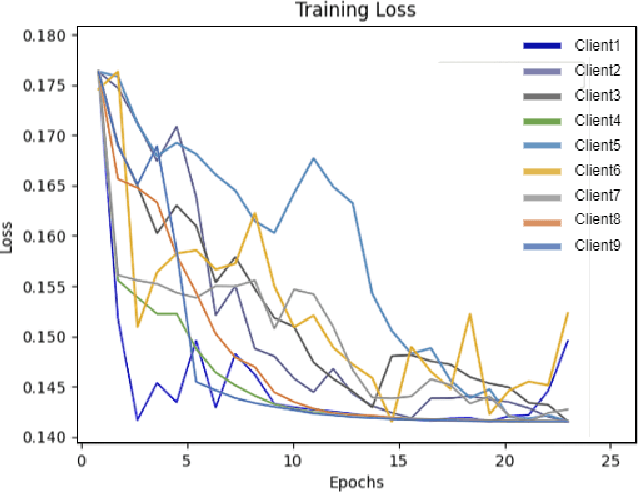
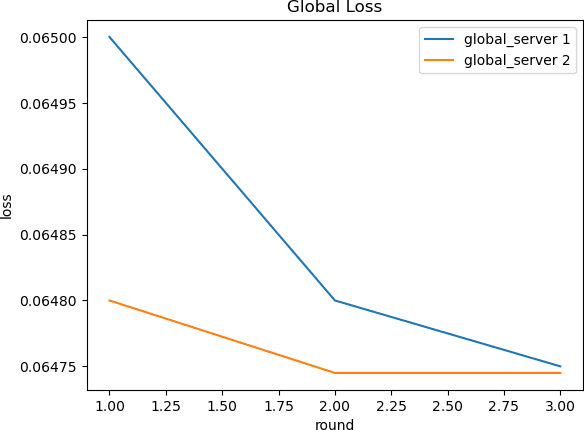
Federated learning (FL) with a single global server framework is currently a popular approach for training machine learning models on decentralized environment, such as mobile devices and edge devices. However, the centralized server architecture poses a risk as any challenge on the central/global server would result in the failure of the entire system. To minimize this risk, we propose a novel federated learning framework that leverages the deployment of multiple global servers. We posit that implementing multiple global servers in federated learning can enhance efficiency by capitalizing on local collaborations and aggregating knowledge, and the error tolerance in regard to communication failure in the single server framework would be handled. We therefore propose a novel framework that leverages the deployment of multiple global servers. We conducted a series of experiments using a dataset containing the event history of electric vehicle (EV) charging at numerous stations. We deployed a federated learning setup with multiple global servers and client servers, where each client-server strategically represented a different region and a global server was responsible for aggregating local updates from those devices. Our preliminary results of the global models demonstrate that the difference in performance attributed to multiple servers is less than 1%. While the hypothesis of enhanced model efficiency was not as expected, the rule for handling communication challenges added to the algorithm could resolve the error tolerance issue. Future research can focus on identifying specific uses for the deployment of multiple global servers.
ECAvg: An Edge-Cloud Collaborative Learning Approach using Averaged Weights
Oct 05, 2023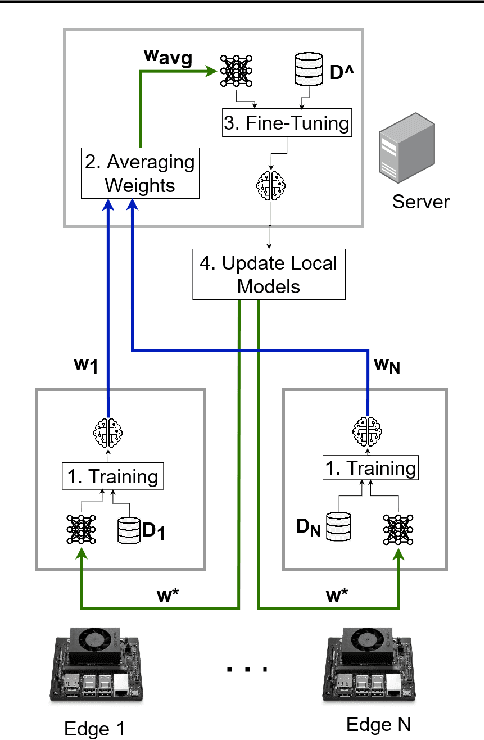

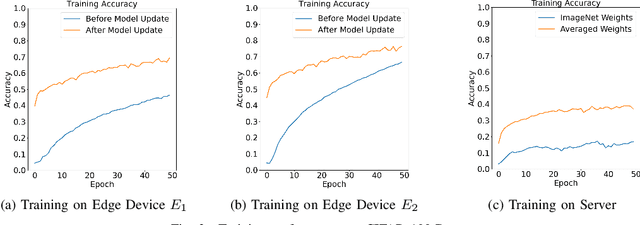

The use of edge devices together with cloud provides a collaborative relationship between both classes of devices where one complements the shortcomings of the other. Resource-constraint edge devices can benefit from the abundant computing power provided by servers by offloading computationally intensive tasks to the server. Meanwhile, edge devices can leverage their close proximity to the data source to perform less computationally intensive tasks on the data. In this paper, we propose a collaborative edge-cloud paradigm called ECAvg in which edge devices pre-train local models on their respective datasets and transfer the models to the server for fine-tuning. The server averages the pre-trained weights into a global model, which is fine-tuned on the combined data from the various edge devices. The local (edge) models are then updated with the weights of the global (server) model. We implement a CIFAR-10 classification task using MobileNetV2, a CIFAR-100 classification task using ResNet50, and an MNIST classification using a neural network with a single hidden layer. We observed performance improvement in the CIFAR-10 and CIFAR-100 classification tasks using our approach, where performance improved on the server model with averaged weights and the edge models had a better performance after model update. On the MNIST classification, averaging weights resulted in a drop in performance on both the server and edge models due to negative transfer learning. From the experiment results, we conclude that our approach is successful when implemented on deep neural networks such as MobileNetV2 and ResNet50 instead of simple neural networks.