 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLLM: Self-Corrective G-Code Generation using Large Language Models with User Feedback
Jan 29, 2025



This paper introduces GLLM, an innovative tool that leverages Large Language Models (LLMs) to automatically generate G-code from natural language instructions for Computer Numerical Control (CNC) machining. GLLM addresses the challenges of manual G-code writing by bridging the gap between human-readable task descriptions and machine-executable code. The system incorporates a fine-tuned StarCoder-3B model, enhanced with domain-specific training data and a Retrieval-Augmented Generation (RAG) mechanism. GLLM employs advanced prompting strategies and a novel self-corrective code generation approach to ensure both syntactic and semantic correctness of the generated G-code. The architecture includes robust validation mechanisms, including syntax checks, G-code-specific verifications, and functional correctness evaluations using Hausdorff distance. By combining these techniques, GLLM aims to democratize CNC programming, making it more accessible to users without extensive programming experience while maintaining high accuracy and reliability in G-code generation.
EdgeMLOps: Operationalizing ML models with Cumulocity IoT and thin-edge.io for Visual quality Inspection
Jan 28, 2025

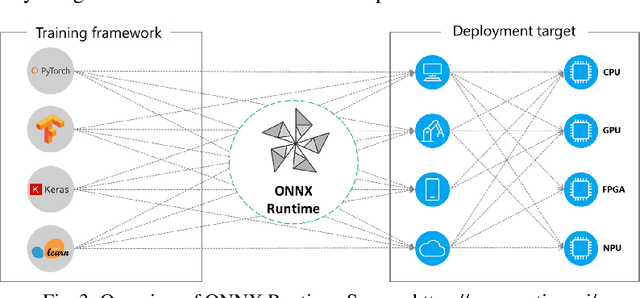

This paper introduces EdgeMLOps, a framework leveraging Cumulocity IoT and thin-edge.io for deploying and managing machine learning models on resource-constrained edge devices. We address the challenges of model optimization, deployment, and lifecycle management in edge environments. The framework's efficacy is demonstrated through a visual quality inspection (VQI) use case where images of assets are processed on edge devices, enabling real-time condition updates within an asset management system. Furthermore, we evaluate the performance benefits of different quantization methods, specifically static and dynamic signed-int8, on a Raspberry Pi 4, demonstrating significant inference time reductions compared to FP32 precision. Our results highlight the potential of EdgeMLOps to enable efficient and scalable AI deployments at the edge for industrial applications.
Open-Source Drift Detection Tools in Action: Insights from Two Use Cases
Apr 29, 2024Data drifts pose a critical challenge in the lifecycle of machine learning (ML) models, affecting their performance and reliability. In response to this challenge, we present a microbenchmark study, called D3Bench, which evaluates the efficacy of open-source drift detection tools. D3Bench examines the capabilities of Evidently AI, NannyML, and Alibi-Detect, leveraging real-world data from two smart building use cases.We prioritize assessing the functional suitability of these tools to identify and analyze data drifts. Furthermore, we consider a comprehensive set of non-functional criteria, such as the integrability with ML pipelines, the adaptability to diverse data types, user-friendliness, computational efficiency, and resource demands. Our findings reveal that Evidently AI stands out for its general data drift detection, whereas NannyML excels at pinpointing the precise timing of shifts and evaluating their consequent effects on predictive accuracy.
LangXAI: Integrating Large Vision Models for Generating Textual Explanations to Enhance Explainability in Visual Perception Tasks
Feb 19, 2024



LangXAI is a framework that integrates Explainable Artificial Intelligence (XAI) with advanced vision models to generate textual explanations for visual recognition tasks. Despite XAI advancements, an understanding gap persists for end-users with limited domain knowledge in artificial intelligence and computer vision. LangXAI addresses this by furnishing text-based explanations for classification, object detection, and semantic segmentation model outputs to end-users. Preliminary results demonstrate LangXAI's enhanced plausibility, with high BERTScore across tasks, fostering a more transparent and reliable AI framework on vision tasks for end-users.
Beyond explaining: XAI-based Adaptive Learning with SHAP Clustering for Energy Consumption Prediction
Feb 07, 2024This paper presents an approach integrating explainable artificial intelligence (XAI) techniques with adaptive learning to enhance energy consumption prediction models, with a focus on handling data distribution shifts. Leveraging SHAP clustering, our method provides interpretable explanations for model predictions and uses these insights to adaptively refine the model, balancing model complexity with predictive performance. We introduce a three-stage process: (1) obtaining SHAP values to explain model predictions, (2) clustering SHAP values to identify distinct patterns and outliers, and (3) refining the model based on the derived SHAP clustering characteristics. Our approach mitigates overfitting and ensures robustness in handling data distribution shifts. We evaluate our method on a comprehensive dataset comprising energy consumption records of buildings, as well as two additional datasets to assess the transferability of our approach to other domains, regression, and classification problems. Our experiments demonstrate the effectiveness of our approach in both task types, resulting in improved predictive performance and interpretable model explanations.
XAI-Enhanced Semantic Segmentation Models for Visual Quality Inspection
Jan 18, 2024



Visual quality inspection systems, crucial in sectors like manufacturing and logistics, employ computer vision and machine learning for precise, rapid defect detection. However, their unexplained nature can hinder trust, error identification, and system improvement. This paper presents a framework to bolster visual quality inspection by using CAM-based explanations to refine semantic segmentation models. Our approach consists of 1) Model Training, 2) XAI-based Model Explanation, 3) XAI Evaluation, and 4) Annotation Augmentation for Model Enhancement, informed by explanations and expert insights. Evaluations show XAI-enhanced models surpass original DeepLabv3-ResNet101 models, especially in intricate object segmentation.
AutoCure: Automated Tabular Data Curation Technique for ML Pipelines
Apr 26, 2023



Machine learning algorithms have become increasingly prevalent in multiple domains, such as autonomous driving, healthcare, and finance. In such domains, data preparation remains a significant challenge in developing accurate models, requiring significant expertise and time investment to search the huge search space of well-suited data curation and transformation tools. To address this challenge, we present AutoCure, a novel and configuration-free data curation pipeline that improves the quality of tabular data. Unlike traditional data curation methods, AutoCure synthetically enhances the density of the clean data fraction through an adaptive ensemble-based error detection method and a data augmentation module. In practice, AutoCure can be integrated with open source tools, e.g., Auto-sklearn, H2O, and TPOT, to promote the democratization of machine learning. As a proof of concept, we provide a comparative evaluation of AutoCure against 28 combinations of traditional data curation tools, demonstrating superior performance and predictive accuracy without user intervention. Our evaluation shows that AutoCure is an effective approach to automating data preparation and improving the accuracy of machine learning models.
REIN: A Comprehensive Benchmark Framework for Data Cleaning Methods in ML Pipelines
Feb 09, 2023



Nowadays, machine learning (ML) plays a vital role in many aspects of our daily life. In essence, building well-performing ML applications requires the provision of high-quality data throughout the entire life-cycle of such applications. Nevertheless, most of the real-world tabular data suffer from different types of discrepancies, such as missing values, outliers, duplicates, pattern violation, and inconsistencies. Such discrepancies typically emerge while collecting, transferring, storing, and/or integrating the data. To deal with these discrepancies, numerous data cleaning methods have been introduced. However, the majority of such methods broadly overlook the requirements imposed by downstream ML models. As a result, the potential of utilizing these data cleaning methods in ML pipelines is predominantly unrevealed. In this work, we introduce a comprehensive benchmark, called REIN1, to thoroughly investigate the impact of data cleaning methods on various ML models. Through the benchmark, we provide answers to important research questions, e.g., where and whether data cleaning is a necessary step in ML pipelines. To this end, the benchmark examines 38 simple and advanced error detection and repair methods. To evaluate these methods, we utilized a wide collection of ML models trained on 14 publicly-available datasets covering different domains and encompassing realistic as well as synthetic error profiles.
DiffML: End-to-end Differentiable ML Pipelines
Jul 05, 2022



In this paper, we present our vision of differentiable ML pipelines called DiffML to automate the construction of ML pipelines in an end-to-end fashion. The idea is that DiffML allows to jointly train not just the ML model itself but also the entire pipeline including data preprocessing steps, e.g., data cleaning, feature selection, etc. Our core idea is to formulate all pipeline steps in a differentiable way such that the entire pipeline can be trained using backpropagation. However, this is a non-trivial problem and opens up many new research questions. To show the feasibility of this direction, we demonstrate initial ideas and a general principle of how typical preprocessing steps such as data cleaning, feature selection and dataset selection can be formulated as differentiable programs and jointly learned with the ML model. Moreover, we discuss a research roadmap and core challenges that have to be systematically tackled to enable fully differentiable ML pipelines.