 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARE: A Single-Pass Neural Model for Relational Databases
Oct 20, 2023While there has been extensive work on deep neural networks for images and text, deep learning for relational databases (RDBs) is still a rather unexplored field. One direction that recently gained traction is to apply Graph Neural Networks (GNNs) to RBDs. However, training GNNs on large relational databases (i.e., data stored in multiple database tables) is rather inefficient due to multiple rounds of training and potentially large and inefficient representations. Hence, in this paper we propose SPARE (Single-Pass Relational models), a new class of neural models that can be trained efficiently on RDBs while providing similar accuracies as GNNs. For enabling efficient training, different from GNNs, SPARE makes use of the fact that data in RDBs has a regular structure, which allows one to train these models in a single pass while exploiting symmetries at the same time. Our extensive empirical evaluation demonstrates that SPARE can significantly speedup both training and inference while offering competitive predictive performance over numerous baselines.
Towards Foundation Models for Relational Databases [Vision Paper]
May 24, 2023Tabular representation learning has recently gained a lot of attention. However, existing approaches only learn a representation from a single table, and thus ignore the potential to learn from the full structure of relational databases, including neighboring tables that can contain important information for a contextualized representation. Moreover, current models are significantly limited in scale, which prevents that they learn from large databases. In this paper, we thus introduce our vision of relational representation learning, that can not only learn from the full relational structure, but also can scale to larger database sizes that are commonly found in real-world. Moreover, we also discuss opportunities and challenges we see along the way to enable this vision and present initial very promising results. Overall, we argue that this direction can lead to foundation models for relational databases that are today only available for text and images.
DiffML: End-to-end Differentiable ML Pipelines
Jul 05, 2022



In this paper, we present our vision of differentiable ML pipelines called DiffML to automate the construction of ML pipelines in an end-to-end fashion. The idea is that DiffML allows to jointly train not just the ML model itself but also the entire pipeline including data preprocessing steps, e.g., data cleaning, feature selection, etc. Our core idea is to formulate all pipeline steps in a differentiable way such that the entire pipeline can be trained using backpropagation. However, this is a non-trivial problem and opens up many new research questions. To show the feasibility of this direction, we demonstrate initial ideas and a general principle of how typical preprocessing steps such as data cleaning, feature selection and dataset selection can be formulated as differentiable programs and jointly learned with the ML model. Moreover, we discuss a research roadmap and core challenges that have to be systematically tackled to enable fully differentiable ML pipelines.
Demonstrating CAT: Synthesizing Data-Aware Conversational Agents for Transactional Databases
Mar 26, 2022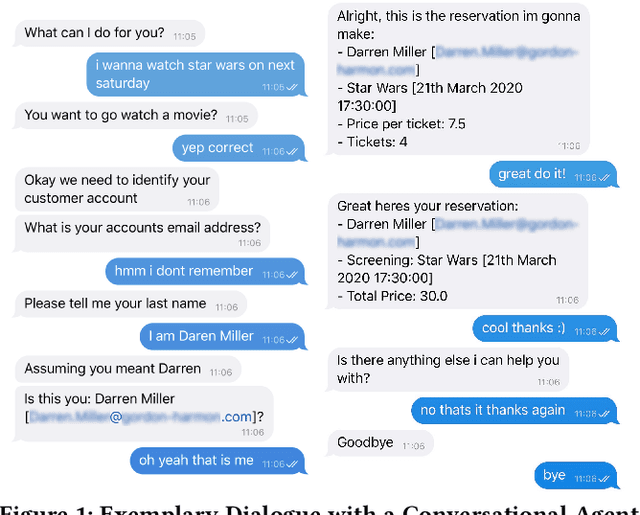

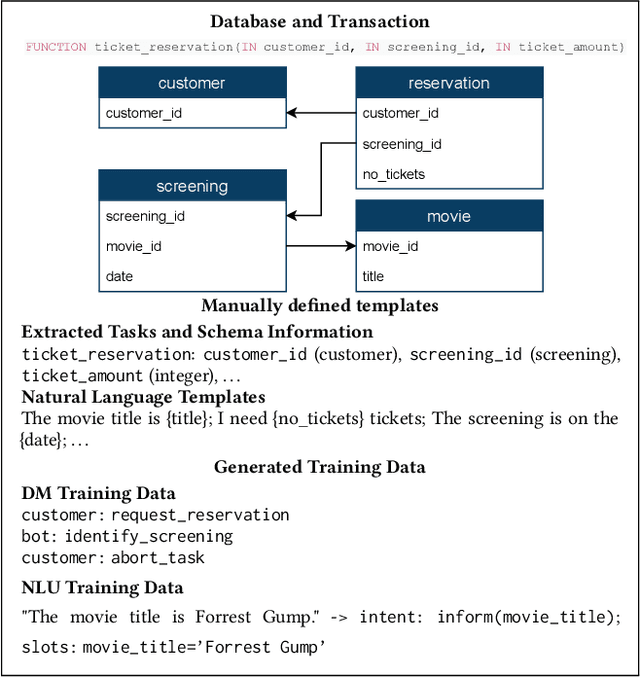

Databases for OLTP are often the backbone for applications such as hotel room or cinema ticket booking applications. However, developing a conversational agent (i.e., a chatbot-like interface) to allow end-users to interact with an application using natural language requires both immense amounts of training data and NLP expertise. This motivates CAT, which can be used to easily create conversational agents for transactional databases. The main idea is that, for a given OLTP database, CAT uses weak supervision to synthesize the required training data to train a state-of-the-art conversational agent, allowing users to interact with the OLTP database. Furthermore, CAT provides an out-of-the-box integration of the resulting agent with the database. As a major difference to existing conversational agents, agents synthesized by CAT are data-aware. This means that the agent decides which information should be requested from the user based on the current data distributions in the database, which typically results in markedly more efficient dialogues compared with non-data-aware agents. We publish the code for CAT as open source.
Zero-Shot Cost Models for Out-of-the-box Learned Cost Prediction
Jan 03, 2022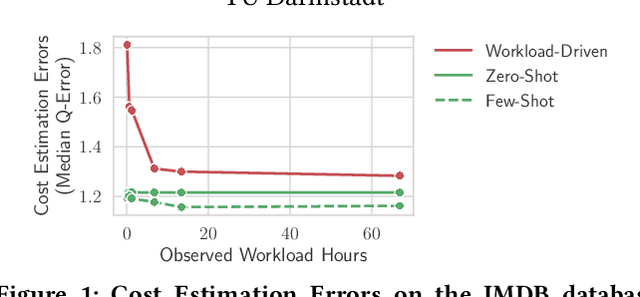

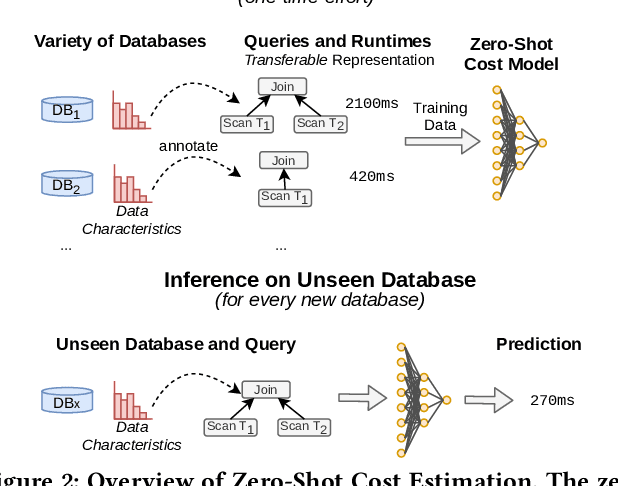

In this paper, we introduce zero-shot cost models which enable learned cost estimation that generalizes to unseen databases. In contrast to state-of-the-art workload-driven approaches which require to execute a large set of training queries on every new database, zero-shot cost models thus allow to instantiate a learned cost model out-of-the-box without expensive training data collection. To enable such zero-shot cost models, we suggest a new learning paradigm based on pre-trained cost models. As core contributions to support the transfer of such a pre-trained cost model to unseen databases, we introduce a new model architecture and representation technique for encoding query workloads as input to those models. As we will show in our evaluation, zero-shot cost estimation can provide more accurate cost estimates than state-of-the-art models for a wide range of (real-world) databases without requiring any query executions on unseen databases. Furthermore, we show that zero-shot cost models can be used in a few-shot mode that further improves their quality by retraining them just with a small number of additional training queries on the unseen database.
One Model to Rule them All: Towards Zero-Shot Learning for Databases
May 03, 2021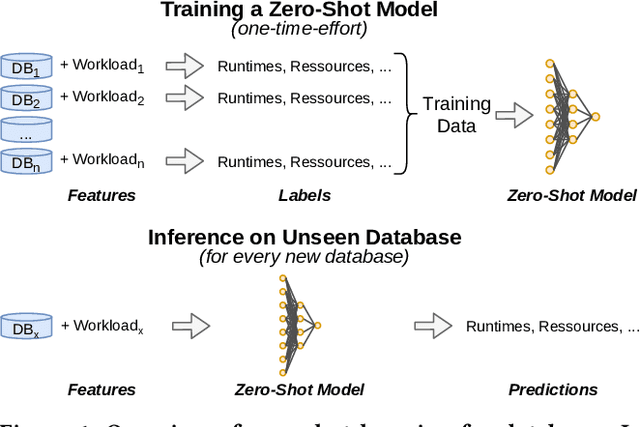
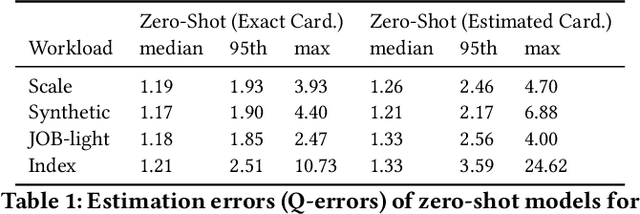
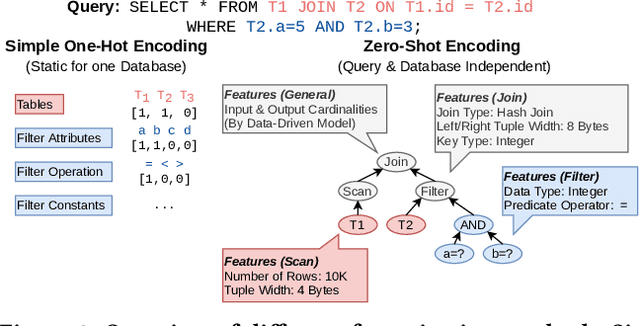
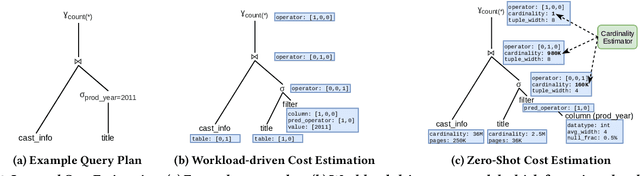
In this paper, we present our vision of so called zero-shot learning for databases which is a new learning approach for database components. Zero-shot learning for databases is inspired by recent advances in transfer learning of models such as GPT-3 and can support a new database out-of-the box without the need to train a new model. As a first concrete contribution in this paper, we show the feasibility of zero-shot learning for the task of physical cost estimation and present very promising initial results. Moreover, as a second contribution we discuss the core challenges related to zero-shot learning for databases and present a roadmap to extend zero-shot learning towards many other tasks beyond cost estimation or even beyond classical database systems and workloads.
Reconstruction and Membership Inference Attacks against Generative Models
Jun 07, 2019
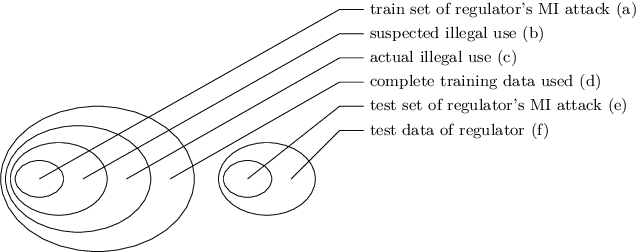
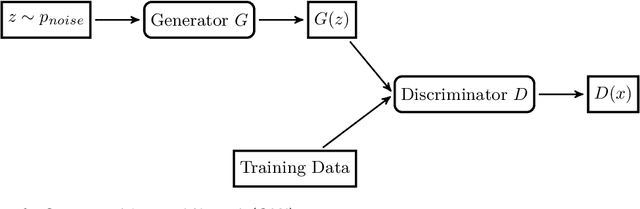

We present two information leakage attacks that outperform previous work on membership inference against generative models. The first attack allows membership inference without assumptions on the type of the generative model. Contrary to previous evaluation metrics for generative models, like Kernel Density Estimation, it only considers samples of the model which are close to training data records. The second attack specifically targets Variational Autoencoders, achieving high membership inference accuracy. Furthermore, previous work mostly considers membership inference adversaries who perform single record membership inference. We argue for considering regulatory actors who perform set membership inference to identify the use of specific datasets for training. The attacks are evaluated on two generative model architectures, Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), trained on standard image datasets. Our results show that the two attacks yield success rates superior to previous work on most data sets while at the same time having only very mild assumptions. We envision the two attacks in combination with the membership inference attack type formalization as especially useful. For example, to enforce data privacy standards and automatically assessing model quality in machine learning as a service setups. In practice, our work motivates the use of GANs since they prove less vulnerable against information leakage attacks while producing detailed samples.
Model-based Approximate Query Processing
Nov 15, 2018



Interactive visualizations are arguably the most important tool to explore, understand and convey facts about data. In the past years, the database community has been working on different techniques for Approximate Query Processing (AQP) that aim to deliver an approximate query result given a fixed time bound to support interactive visualizations better. However, classical AQP approaches suffer from various problems that limit the applicability to support the ad-hoc exploration of a new data set: (1) Classical AQP approaches that perform online sampling can support ad-hoc exploration queries but yield low quality if executed over rare subpopulations. (2) Classical AQP approaches that rely on offline sampling can use some form of biased sampling to mitigate these problems but require a priori knowledge of the workload, which is often not realistic if users want to explore a new database. In this paper, we present a new approach to AQP called Model-based AQP that leverages generative models learned over the complete database to answer SQL queries at interactive speeds. Different from classical AQP approaches, generative models allow us to compute responses to ad-hoc queries and deliver high-quality estimates also over rare subpopulations at the same time. In our experiments with real and synthetic data sets, we show that Model-based AQP can in many scenarios return more accurate results in a shorter runtime. Furthermore, we think that our techniques of using generative models presented in this paper can not only be used for AQP in databases but also has applications for other database problems including Query Optimization as well as Data Cleaning.