 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Differentially Private Variational Autoencoders under Membership Inference
Apr 16, 2022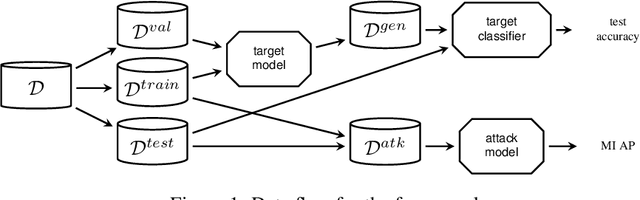

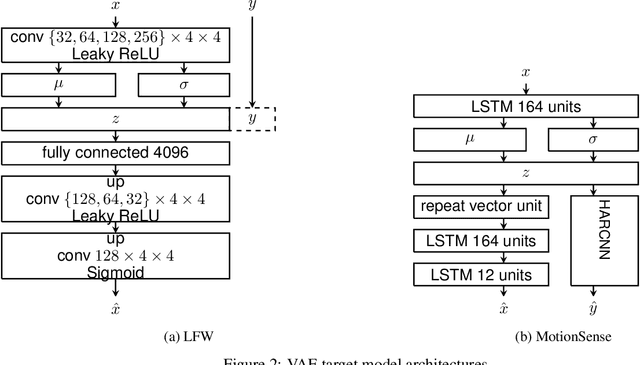
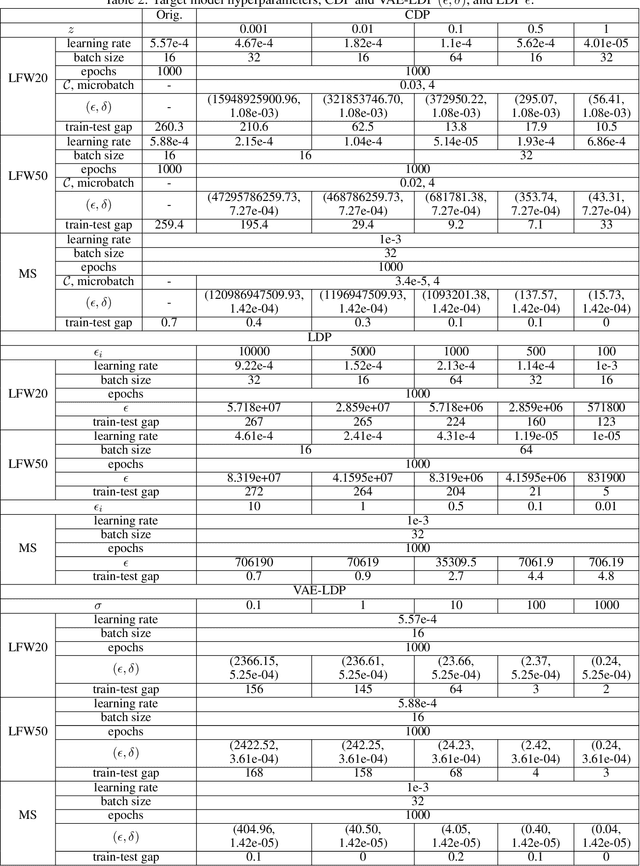
We present an approach to quantify and compare the privacy-accuracy trade-off for differentially private Variational Autoencoders. Our work complements previous work in two aspects. First, we evaluate the the strong reconstruction MI attack against Variational Autoencoders under differential privacy. Second, we address the data scientist's challenge of setting privacy parameter epsilon, which steers the differential privacy strength and thus also the privacy-accuracy trade-off. In our experimental study we consider image and time series data, and three local and central differential privacy mechanisms. We find that the privacy-accuracy trade-offs strongly depend on the dataset and model architecture. We do rarely observe favorable privacy-accuracy trade-off for Variational Autoencoders, and identify a case where LDP outperforms CDP.
Quantifying identifiability to choose and audit $ε$ in differentially private deep learning
Mar 05, 2021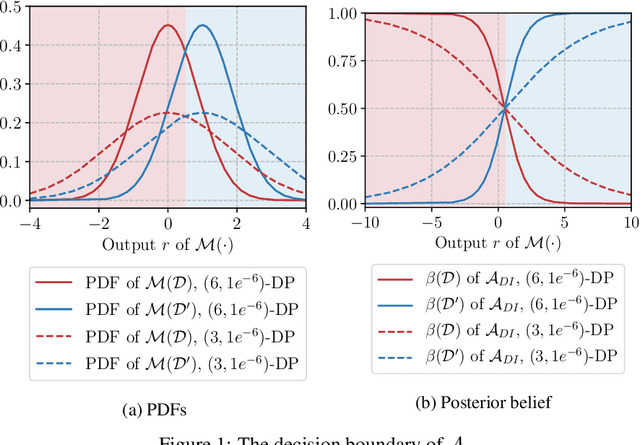
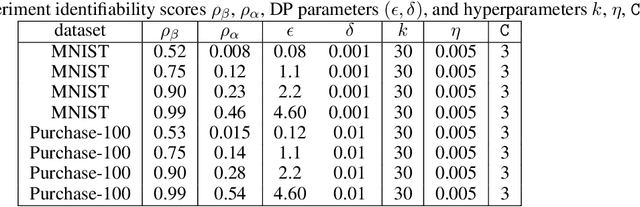
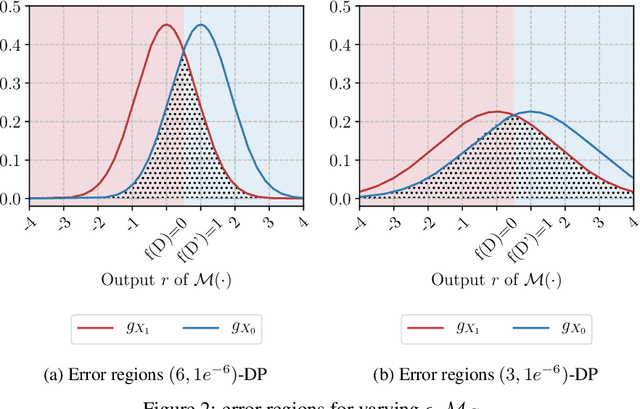
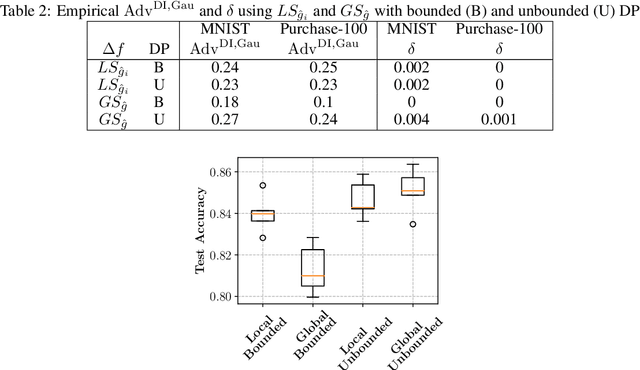
Differential privacy allows bounding the influence that training data records have on a machine learning model. To use differential privacy in machine learning, data scientists must choose privacy parameters $(\epsilon,\delta)$. Choosing meaningful privacy parameters is key since models trained with weak privacy parameters might result in excessive privacy leakage, while strong privacy parameters might overly degrade model utility. However, privacy parameter values are difficult to choose for two main reasons. First, the upper bound on privacy loss $(\epsilon,\delta)$ might be loose, depending on the chosen sensitivity and data distribution of practical datasets. Second, legal requirements and societal norms for anonymization often refer to individual identifiability, to which $(\epsilon,\delta)$ are only indirectly related. We transform $(\epsilon,\delta)$ to a bound on the Bayesian posterior belief of the adversary assumed by differential privacy concerning the presence of any record in the training dataset. The bound holds for multidimensional queries under composition, and we show that it can be tight in practice. Furthermore, we derive an identifiability bound, which relates the adversary assumed in differential privacy to previous work on membership inference adversaries. We formulate an implementation of this differential privacy adversary that allows data scientists to audit model training and compute empirical identifiability scores and empirical $(\epsilon,\delta)$.
On the privacy-utility trade-off in differentially private hierarchical text classification
Mar 04, 2021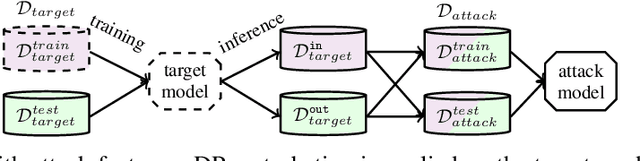



Hierarchical models for text classification can leak sensitive or confidential training data information to adversaries due to training data memorization. Using differential privacy during model training can mitigate leakage attacks against trained models by perturbing the training optimizer. However, for hierarchical text classification a multiplicity of model architectures is available and it is unclear whether some architectures yield a better trade-off between remaining model accuracy and model leakage under differentially private training perturbation than others. We use a white-box membership inference attack to assess the information leakage of three widely used neural network architectures for hierarchical text classification under differential privacy. We show that relatively weak differential privacy guarantees already suffice to completely mitigate the membership inference attack, thus resulting only in a moderate decrease in utility. More specifically, for large datasets with long texts we observed transformer-based models to achieve an overall favorable privacy-utility trade-off, while for smaller datasets with shorter texts CNNs are preferable.
Assessing differentially private deep learning with Membership Inference
Jan 10, 2020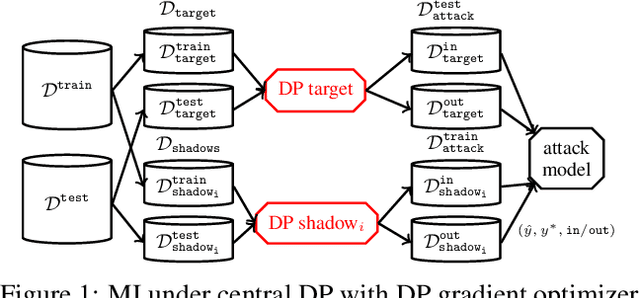
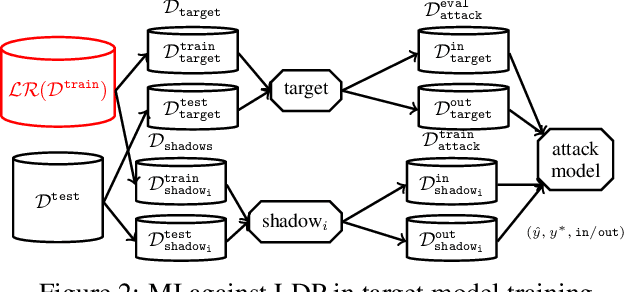
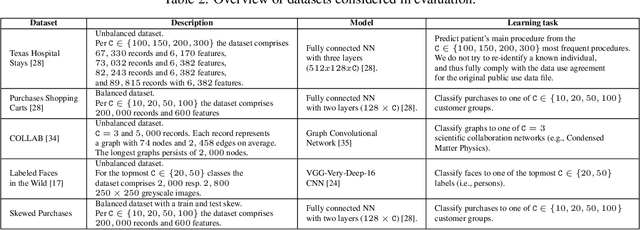
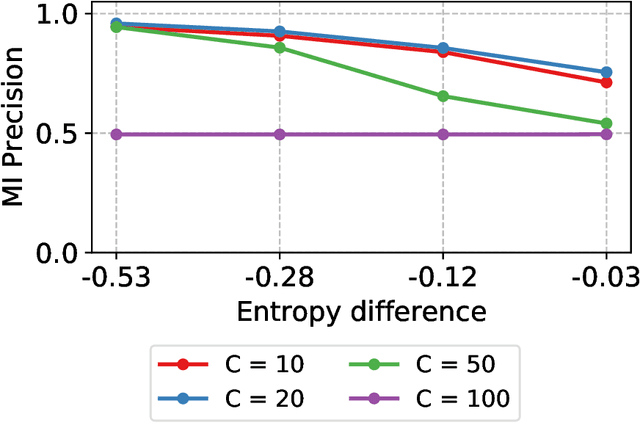
Releasing data in the form of trained neural networks with differential privacy promises meaningful anonymization. However, there is an inherent privacy-accuracy trade-off in differential privacy which is challenging to assess for non-privacy experts. Furthermore, local and central differential privacy mechanisms are available to either anonymize the training data or the learnt neural network, and the privacy parameter $\epsilon$ cannot be used to compare these two mechanisms. We propose to measure privacy through a black-box membership inference attack and compare the privacy-accuracy trade-off for different local and central differential privacy mechanisms. Furthermore, we need to evaluate whether differential privacy is a useful mechanism in practice since differential privacy will especially be used by data scientists if membership inference risk is lowered more than accuracy. We experiment with several datasets and show that neither local differential privacy nor central differential privacy yields a consistently better privacy-accuracy trade-off in all cases. We also show that the relative privacy-accuracy trade-off, instead of strictly declining linearly over $\epsilon$, is only favorable within a small interval. For this purpose we propose $\varphi$, a ratio expressing the relative privacy-accuracy trade-off.
Reconstruction and Membership Inference Attacks against Generative Models
Jun 07, 2019
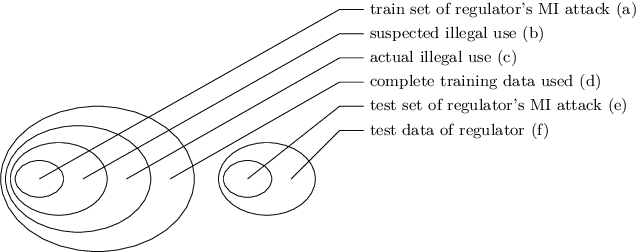
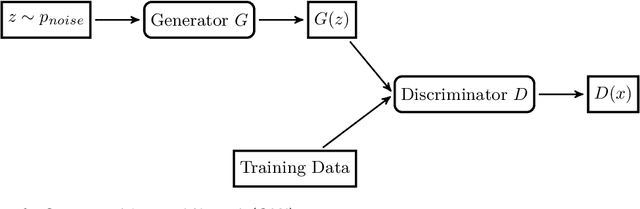

We present two information leakage attacks that outperform previous work on membership inference against generative models. The first attack allows membership inference without assumptions on the type of the generative model. Contrary to previous evaluation metrics for generative models, like Kernel Density Estimation, it only considers samples of the model which are close to training data records. The second attack specifically targets Variational Autoencoders, achieving high membership inference accuracy. Furthermore, previous work mostly considers membership inference adversaries who perform single record membership inference. We argue for considering regulatory actors who perform set membership inference to identify the use of specific datasets for training. The attacks are evaluated on two generative model architectures, Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), trained on standard image datasets. Our results show that the two attacks yield success rates superior to previous work on most data sets while at the same time having only very mild assumptions. We envision the two attacks in combination with the membership inference attack type formalization as especially useful. For example, to enforce data privacy standards and automatically assessing model quality in machine learning as a service setups. In practice, our work motivates the use of GANs since they prove less vulnerable against information leakage attacks while producing detailed samples.