 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
Neural Head Avatars from Monocular RGB Videos
Dec 02, 2021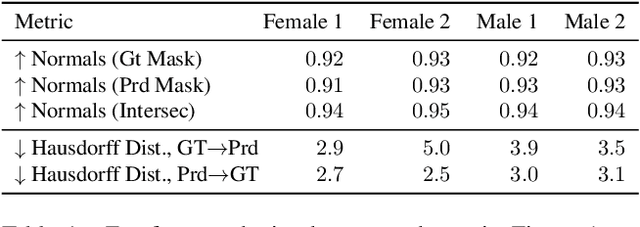
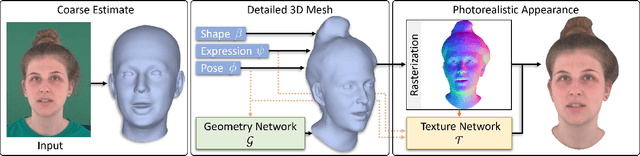
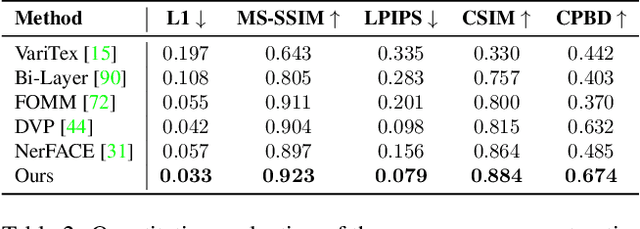
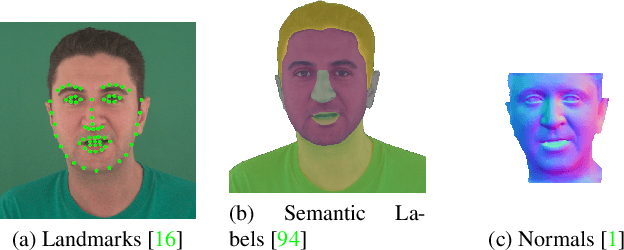
We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. Our representation can be learned from a monocular RGB portrait video that features a range of different expressions and views. Specifically, we propose a hybrid representation consisting of a morphable model for the coarse shape and expressions of the face, and two feed-forward networks, predicting vertex offsets of the underlying mesh as well as a view- and expression-dependent texture. We demonstrate that this representation is able to accurately extrapolate to unseen poses and view points, and generates natural expressions while providing sharp texture details. Compared to previous works on head avatars, our method provides a disentangled shape and appearance model of the complete human head (including hair) that is compatible with the standard graphics pipeline. Moreover, it quantitatively and qualitatively outperforms current state of the art in terms of reconstruction quality and novel-view synthesis.
Assessing differentially private deep learning with Membership Inference
Jan 10, 2020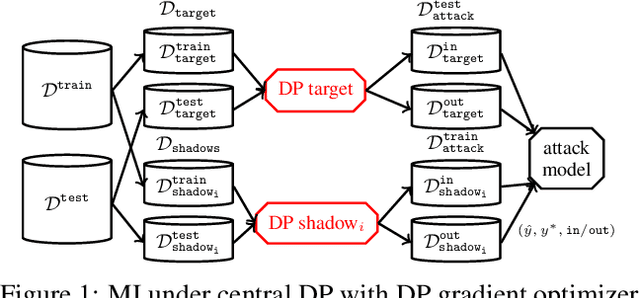
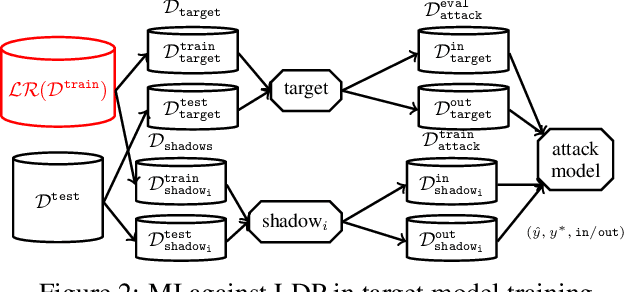
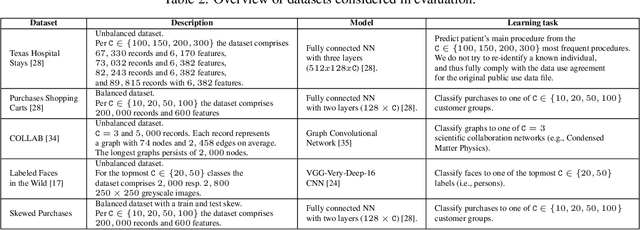
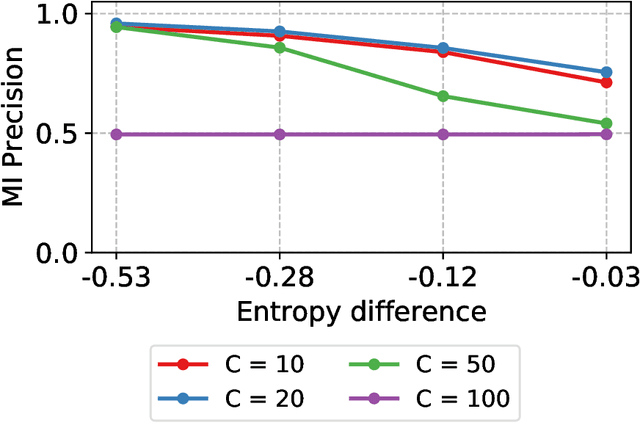
Releasing data in the form of trained neural networks with differential privacy promises meaningful anonymization. However, there is an inherent privacy-accuracy trade-off in differential privacy which is challenging to assess for non-privacy experts. Furthermore, local and central differential privacy mechanisms are available to either anonymize the training data or the learnt neural network, and the privacy parameter $\epsilon$ cannot be used to compare these two mechanisms. We propose to measure privacy through a black-box membership inference attack and compare the privacy-accuracy trade-off for different local and central differential privacy mechanisms. Furthermore, we need to evaluate whether differential privacy is a useful mechanism in practice since differential privacy will especially be used by data scientists if membership inference risk is lowered more than accuracy. We experiment with several datasets and show that neither local differential privacy nor central differential privacy yields a consistently better privacy-accuracy trade-off in all cases. We also show that the relative privacy-accuracy trade-off, instead of strictly declining linearly over $\epsilon$, is only favorable within a small interval. For this purpose we propose $\varphi$, a ratio expressing the relative privacy-accuracy trade-off.