 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Animatable 3D Avatars with Morphable Model Alignment
Apr 22, 2025The generation of high-quality, animatable 3D head avatars from text has enormous potential in content creation applications such as games, movies, and embodied virtual assistants. Current text-to-3D generation methods typically combine parametric head models with 2D diffusion models using score distillation sampling to produce 3D-consistent results. However, they struggle to synthesize realistic details and suffer from misalignments between the appearance and the driving parametric model, resulting in unnatural animation results. We discovered that these limitations stem from ambiguities in the 2D diffusion predictions during 3D avatar distillation, specifically: i) the avatar's appearance and geometry is underconstrained by the text input, and ii) the semantic alignment between the predictions and the parametric head model is insufficient because the diffusion model alone cannot incorporate information from the parametric model. In this work, we propose a novel framework, AnimPortrait3D, for text-based realistic animatable 3DGS avatar generation with morphable model alignment, and introduce two key strategies to address these challenges. First, we tackle appearance and geometry ambiguities by utilizing prior information from a pretrained text-to-3D model to initialize a 3D avatar with robust appearance, geometry, and rigging relationships to the morphable model. Second, we refine the initial 3D avatar for dynamic expressions using a ControlNet that is conditioned on semantic and normal maps of the morphable model to ensure accurate alignment. As a result, our method outperforms existing approaches in terms of synthesis quality, alignment, and animation fidelity. Our experiments show that the proposed method advances the state of the art in text-based, animatable 3D head avatar generation.
Joker: Conditional 3D Head Synthesis with Extreme Facial Expressions
Oct 21, 2024



We introduce Joker, a new method for the conditional synthesis of 3D human heads with extreme expressions. Given a single reference image of a person, we synthesize a volumetric human head with the reference identity and a new expression. We offer control over the expression via a 3D morphable model (3DMM) and textual inputs. This multi-modal conditioning signal is essential since 3DMMs alone fail to define subtle emotional changes and extreme expressions, including those involving the mouth cavity and tongue articulation. Our method is built upon a 2D diffusion-based prior that generalizes well to out-of-domain samples, such as sculptures, heavy makeup, and paintings while achieving high levels of expressiveness. To improve view consistency, we propose a new 3D distillation technique that converts predictions of our 2D prior into a neural radiance field (NeRF). Both the 2D prior and our distillation technique produce state-of-the-art results, which are confirmed by our extensive evaluations. Also, to the best of our knowledge, our method is the first to achieve view-consistent extreme tongue articulation.
DINER: Depth-aware Image-based NEural Radiance fields
Nov 29, 2022We present Depth-aware Image-based NEural Radiance fields (DINER). Given a sparse set of RGB input views, we predict depth and feature maps to guide the reconstruction of a volumetric scene representation that allows us to render 3D objects under novel views. Specifically, we propose novel techniques to incorporate depth information into feature fusion and efficient scene sampling. In comparison to the previous state of the art, DINER achieves higher synthesis quality and can process input views with greater disparity. This allows us to capture scenes more completely without changing capturing hardware requirements and ultimately enables larger viewpoint changes during novel view synthesis. We evaluate our method by synthesizing novel views, both for human heads and for general objects, and observe significantly improved qualitative results and increased perceptual metrics compared to the previous state of the art. The code will be made publicly available for research purposes.
Neural Head Avatars from Monocular RGB Videos
Dec 02, 2021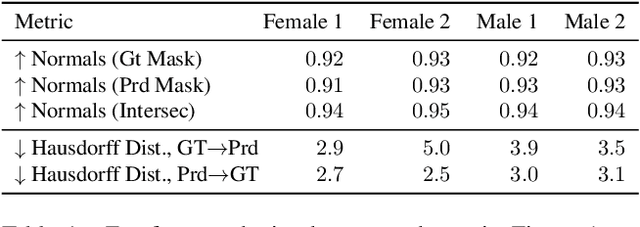
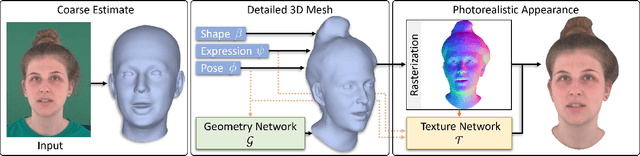
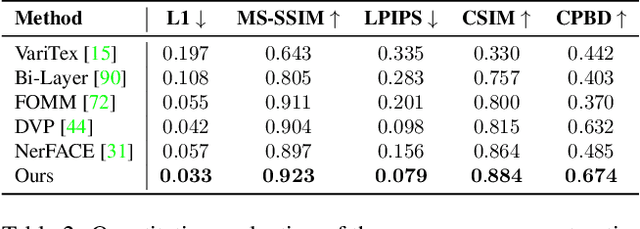
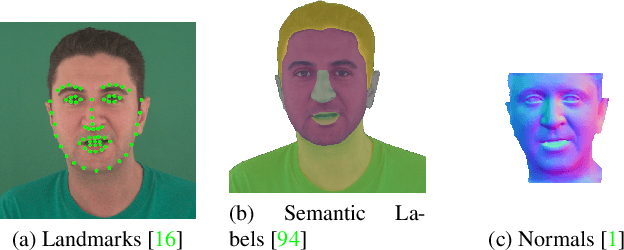
We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. Our representation can be learned from a monocular RGB portrait video that features a range of different expressions and views. Specifically, we propose a hybrid representation consisting of a morphable model for the coarse shape and expressions of the face, and two feed-forward networks, predicting vertex offsets of the underlying mesh as well as a view- and expression-dependent texture. We demonstrate that this representation is able to accurately extrapolate to unseen poses and view points, and generates natural expressions while providing sharp texture details. Compared to previous works on head avatars, our method provides a disentangled shape and appearance model of the complete human head (including hair) that is compatible with the standard graphics pipeline. Moreover, it quantitatively and qualitatively outperforms current state of the art in terms of reconstruction quality and novel-view synthesis.