 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Image Editing Models Understand Lighting?
Jun 25, 2026While recent advancements in generative image editing models have achieved stunning visual fidelity, it remains an open question whether these systems possess an intrinsic knowledge of real-world lighting. Existing benchmarks typically evaluate high-level plausibility of perceptual light transport on curated internet imagery, using VLMs or human judgement, or they rely on synthetically generated datasets. In this work, we introduce the 3D-anchored Light Probe (3DLP) benchmark, for which we have captured a new high-fidelity HDR dataset of real-world lighting changes. The dataset consists of 1K image pairs of diverse indoor scenery in which light probes are physically turned on and off. To allow for a granular performance analysis, we annotated specific image regions such as cast shadows or metallic surfaces. With this data, we evaluate a range of state-of-the-art image editing models by measuring how well their light probe edits align with reality. The evaluation uses two new scores to compensate for AI-generated photographic effects, such as adjusted white balance. Our results show that the overall performance of models differs considerably, with differences slightly less pronounced for specular highlights. The best image editing models are remarkably consistent with real-world physics, however, they still leave room for improvement. We observe that image regions that receive less light from the light probe are more prone to errors for all models. Furthermore, building on their success in evaluating macroscopic lighting plausibility, we test VLMs on our task but find that they are unsuitable for pixel-level light transport analysis. We will make the benchmark, together with the real-world dataset, publicly available to encourage future research on this topic.
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
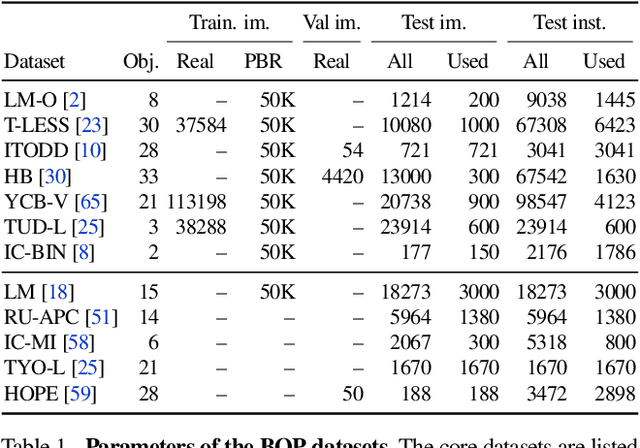
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
PrimeDepth: Efficient Monocular Depth Estimation with a Stable Diffusion Preimage
Sep 13, 2024



This work addresses the task of zero-shot monocular depth estimation. A recent advance in this field has been the idea of utilising Text-to-Image foundation models, such as Stable Diffusion. Foundation models provide a rich and generic image representation, and therefore, little training data is required to reformulate them as a depth estimation model that predicts highly-detailed depth maps and has good generalisation capabilities. However, the realisation of this idea has so far led to approaches which are, unfortunately, highly inefficient at test-time due to the underlying iterative denoising process. In this work, we propose a different realisation of this idea and present PrimeDepth, a method that is highly efficient at test time while keeping, or even enhancing, the positive aspects of diffusion-based approaches. Our key idea is to extract from Stable Diffusion a rich, but frozen, image representation by running a single denoising step. This representation, we term preimage, is then fed into a refiner network with an architectural inductive bias, before entering the downstream task. We validate experimentally that PrimeDepth is two orders of magnitude faster than the leading diffusion-based method, Marigold, while being more robust for challenging scenarios and quantitatively marginally superior. Thereby, we reduce the gap to the currently leading data-driven approach, Depth Anything, which is still quantitatively superior, but predicts less detailed depth maps and requires 20 times more labelled data. Due to the complementary nature of our approach, even a simple averaging between PrimeDepth and Depth Anything predictions can improve upon both methods and sets a new state-of-the-art in zero-shot monocular depth estimation. In future, data-driven approaches may also benefit from integrating our preimage.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024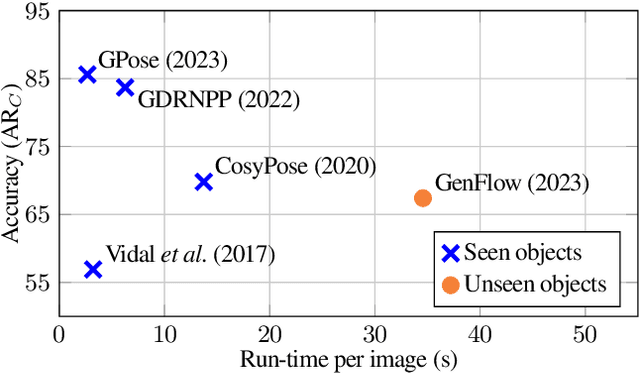


We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
ControlNet-XS: Designing an Efficient and Effective Architecture for Controlling Text-to-Image Diffusion Models
Dec 11, 2023



The field of image synthesis has made tremendous strides forward in the last years. Besides defining the desired output image with text-prompts, an intuitive approach is to additionally use spatial guidance in form of an image, such as a depth map. For this, a recent and highly popular approach is to use a controlling network, such as ControlNet, in combination with a pre-trained image generation model, such as Stable Diffusion. When evaluating the design of existing controlling networks, we observe that they all suffer from the same problem of a delay in information flowing between the generation and controlling process. This, in turn, means that the controlling network must have generative capabilities. In this work we propose a new controlling architecture, called ControlNet-XS, which does not suffer from this problem, and hence can focus on the given task of learning to control. In contrast to ControlNet, our model needs only a fraction of parameters, and hence is about twice as fast during inference and training time. Furthermore, the generated images are of higher quality and the control is of higher fidelity. All code and pre-trained models will be made publicly available.
Unsupervised Deep Graph Matching Based on Cycle Consistency
Aug 01, 2023


We contribute to the sparsely populated area of unsupervised deep graph matching with application to keypoint matching in images. Contrary to the standard \emph{supervised} approach, our method does not require ground truth correspondences between keypoint pairs. Instead, it is self-supervised by enforcing consistency of matchings between images of the same object category. As the matching and the consistency loss are discrete, their derivatives cannot be straightforwardly used for learning. We address this issue in a principled way by building our method upon the recent results on black-box differentiation of combinatorial solvers. This makes our method exceptionally flexible, as it is compatible with arbitrary network architectures and combinatorial solvers. Our experimental evaluation suggests that our technique sets a new state-of-the-art for unsupervised graph matching.
Finding Competence Regions in Domain Generalization
Mar 17, 2023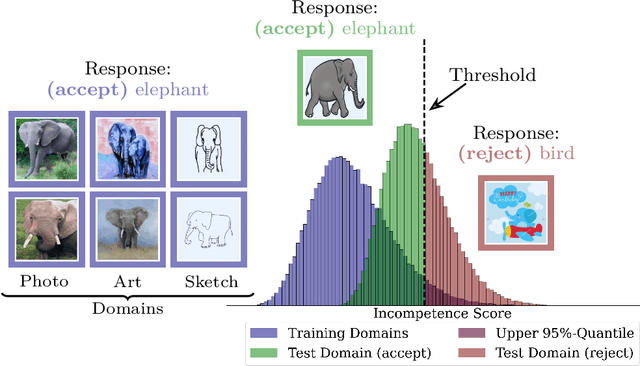
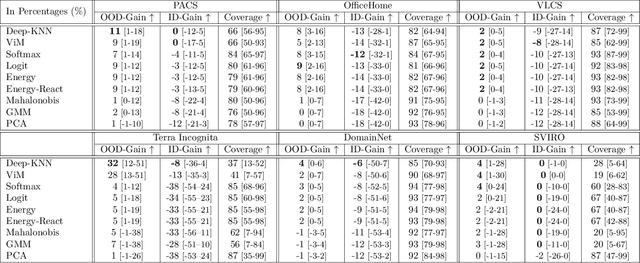
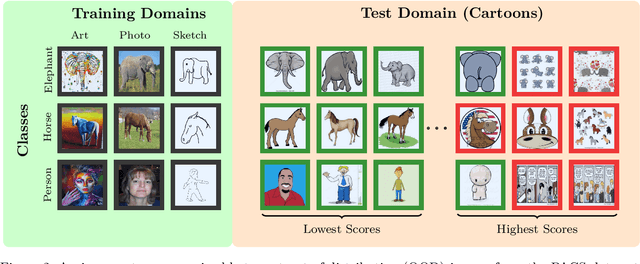
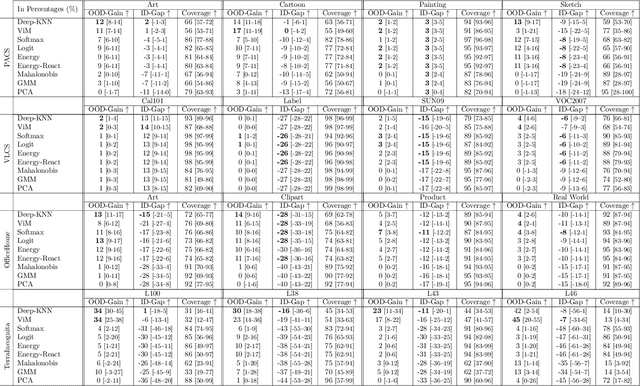
We propose a "learning to reject" framework to address the problem of silent failures in Domain Generalization (DG), where the test distribution differs from the training distribution. Assuming a mild distribution shift, we wish to accept out-of-distribution (OOD) data whenever a model's estimated competence foresees trustworthy responses, instead of rejecting OOD data outright. Trustworthiness is then predicted via a proxy incompetence score that is tightly linked to the performance of a classifier. We present a comprehensive experimental evaluation of incompetence scores for classification and highlight the resulting trade-offs between rejection rate and accuracy gain. For comparability with prior work, we focus on standard DG benchmarks and consider the effect of measuring incompetence via different learned representations in a closed versus an open world setting. Our results suggest that increasing incompetence scores are indeed predictive of reduced accuracy, leading to significant improvements of the average accuracy below a suitable incompetence threshold. However, the scores are not yet good enough to allow for a favorable accuracy/rejection trade-off in all tested domains. Surprisingly, our results also indicate that classifiers optimized for DG robustness do not outperform a naive Empirical Risk Minimization (ERM) baseline in the competence region, that is, where test samples elicit low incompetence scores.
BOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
A Comparative Study of Graph Matching Algorithms in Computer Vision
Jul 01, 2022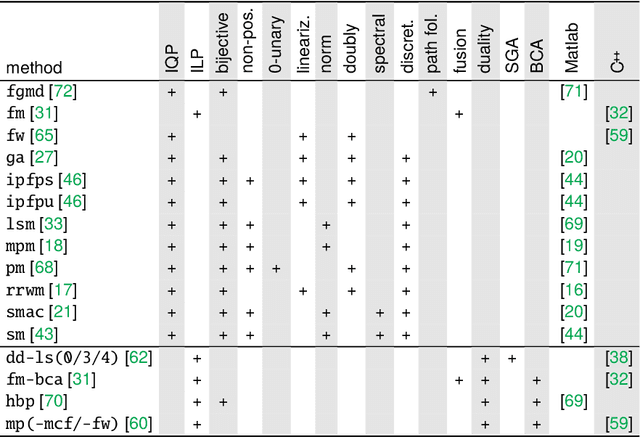
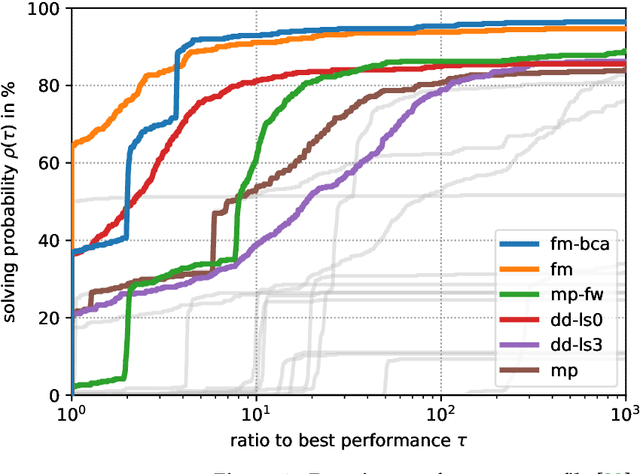
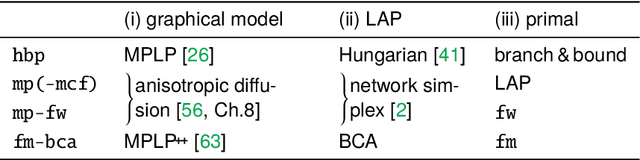
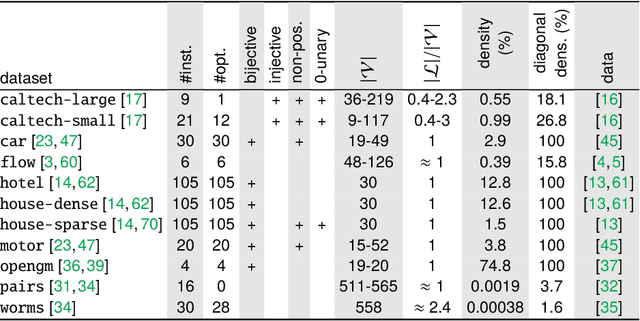
The graph matching optimization problem is an essential component for many tasks in computer vision, such as bringing two deformable objects in correspondence. Naturally, a wide range of applicable algorithms have been proposed in the last decades. Since a common standard benchmark has not been developed, their performance claims are often hard to verify as evaluation on differing problem instances and criteria make the results incomparable. To address these shortcomings, we present a comparative study of graph matching algorithms. We create a uniform benchmark where we collect and categorize a large set of existing and publicly available computer vision graph matching problems in a common format. At the same time we collect and categorize the most popular open-source implementations of graph matching algorithms. Their performance is evaluated in a way that is in line with the best practices for comparing optimization algorithms. The study is designed to be reproducible and extensible to serve as a valuable resource in the future. Our study provides three notable insights: 1.) popular problem instances are exactly solvable in substantially less than 1 second and, therefore, are insufficient for future empirical evaluations; 2.) the most popular baseline methods are highly inferior to the best available methods; 3.) despite the NP-hardness of the problem, instances coming from vision applications are often solvable in a few seconds even for graphs with more than 500 vertices.
Towards Multimodal Depth Estimation from Light Fields
Apr 01, 2022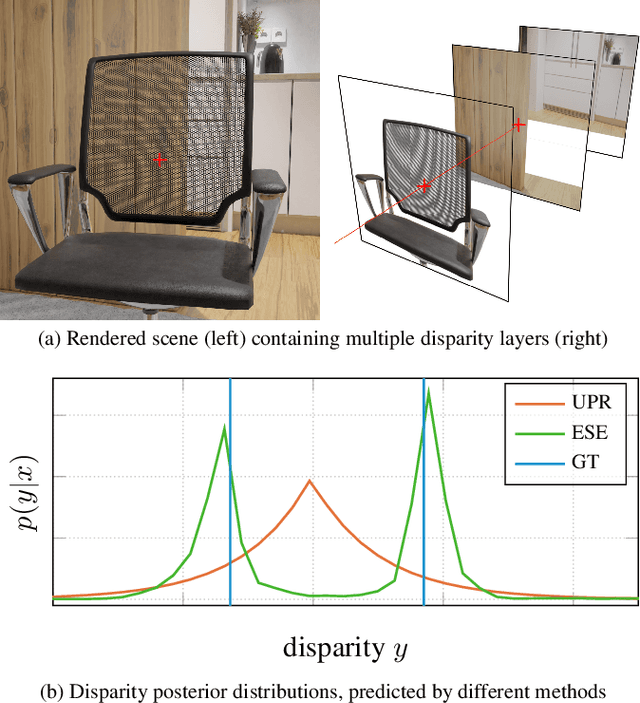
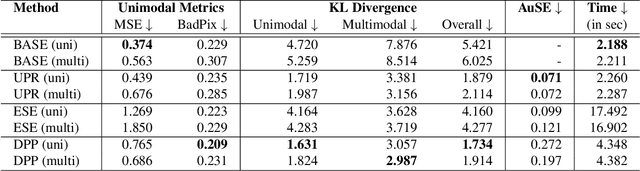

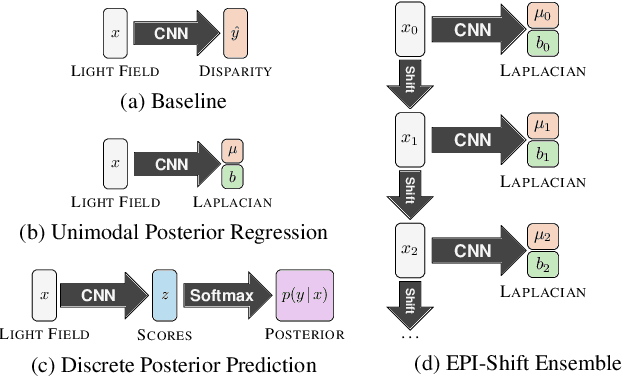
Light field applications, especially light field rendering and depth estimation, developed rapidly in recent years. While state-of-the-art light field rendering methods handle semi-transparent and reflective objects well, depth estimation methods either ignore these cases altogether or only deliver a weak performance. We argue that this is due current methods only considering a single "true" depth, even when multiple objects at different depths contributed to the color of a single pixel. Based on the simple idea of outputting a posterior depth distribution instead of only a single estimate, we develop and explore several different deep-learning-based approaches to the problem. Additionally, we contribute the first "multimodal light field depth dataset" that contains the depths of all objects which contribute to the color of a pixel. This allows us to supervise the multimodal depth prediction and also validate all methods by measuring the KL divergence of the predicted posteriors. With our thorough analysis and novel dataset, we aim to start a new line of depth estimation research that overcomes some of the long-standing limitations of this field.