 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering the Definition of Adversarial Robustness for post-hoc OOD Detectors
Jun 25, 2024



Detecting out-of-distribution (OOD) inputs is critical for safely deploying deep learning models in real-world scenarios. In recent years, many OOD detectors have been developed, and even the benchmarking has been standardized, i.e. OpenOOD. The number of post-hoc detectors is growing fast and showing an option to protect a pre-trained classifier against natural distribution shifts, claiming to be ready for real-world scenarios. However, its efficacy in handling adversarial examples has been neglected in the majority of studies. This paper investigates the adversarial robustness of the 16 post-hoc detectors on several evasion attacks and discuss a roadmap towards adversarial defense in OOD detectors.
Towards Context-Aware Domain Generalization: Representing Environments with Permutation-Invariant Networks
Dec 15, 2023



In this work, we show that information about the context of an input $X$ can improve the predictions of deep learning models when applied in new domains or production environments. We formalize the notion of context as a permutation-invariant representation of a set of data points that originate from the same environment/domain as the input itself. These representations are jointly learned with a standard supervised learning objective, providing incremental information about the unknown outcome. Furthermore, we offer a theoretical analysis of the conditions under which our approach can, in principle, yield benefits, and formulate two necessary criteria that can be easily verified in practice. Additionally, we contribute insights into the kind of distribution shifts for which our approach promises robustness. Our empirical evaluation demonstrates the effectiveness of our approach for both low-dimensional and high-dimensional data sets. Finally, we demonstrate that we can reliably detect scenarios where a model is tasked with unwarranted extrapolation in out-of-distribution (OOD) domains, identifying potential failure cases. Consequently, we showcase a method to select between the most predictive and the most robust model, circumventing the well-known trade-off between predictive performance and robustness.
On the Convergence Rate of Gaussianization with Random Rotations
Jun 23, 2023



Gaussianization is a simple generative model that can be trained without backpropagation. It has shown compelling performance on low dimensional data. As the dimension increases, however, it has been observed that the convergence speed slows down. We show analytically that the number of required layers scales linearly with the dimension for Gaussian input. We argue that this is because the model is unable to capture dependencies between dimensions. Empirically, we find the same linear increase in cost for arbitrary input $p(x)$, but observe favorable scaling for some distributions. We explore potential speed-ups and formulate challenges for further research.
Finding Competence Regions in Domain Generalization
Mar 17, 2023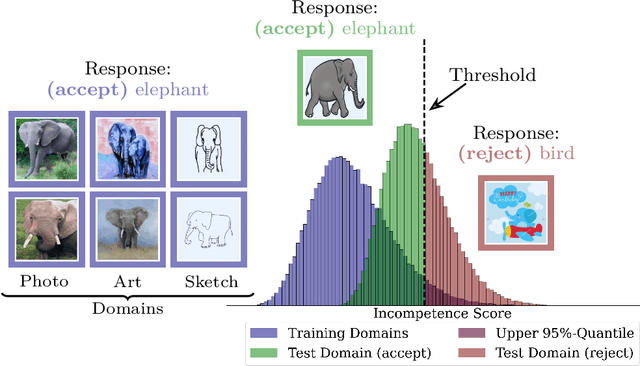
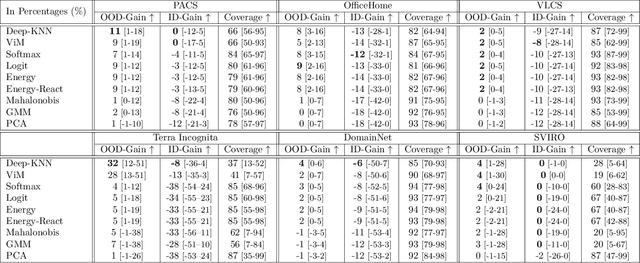
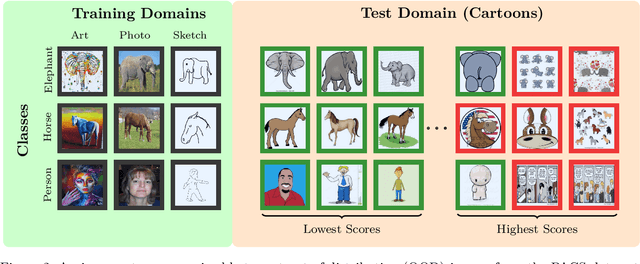
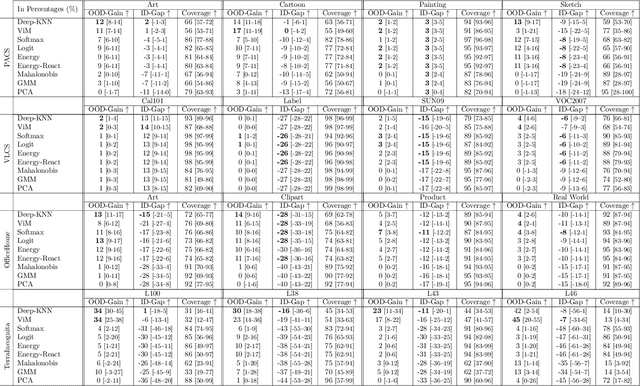
We propose a "learning to reject" framework to address the problem of silent failures in Domain Generalization (DG), where the test distribution differs from the training distribution. Assuming a mild distribution shift, we wish to accept out-of-distribution (OOD) data whenever a model's estimated competence foresees trustworthy responses, instead of rejecting OOD data outright. Trustworthiness is then predicted via a proxy incompetence score that is tightly linked to the performance of a classifier. We present a comprehensive experimental evaluation of incompetence scores for classification and highlight the resulting trade-offs between rejection rate and accuracy gain. For comparability with prior work, we focus on standard DG benchmarks and consider the effect of measuring incompetence via different learned representations in a closed versus an open world setting. Our results suggest that increasing incompetence scores are indeed predictive of reduced accuracy, leading to significant improvements of the average accuracy below a suitable incompetence threshold. However, the scores are not yet good enough to allow for a favorable accuracy/rejection trade-off in all tested domains. Surprisingly, our results also indicate that classifiers optimized for DG robustness do not outperform a naive Empirical Risk Minimization (ERM) baseline in the competence region, that is, where test samples elicit low incompetence scores.
Projected GANs Converge Faster
Nov 01, 2021
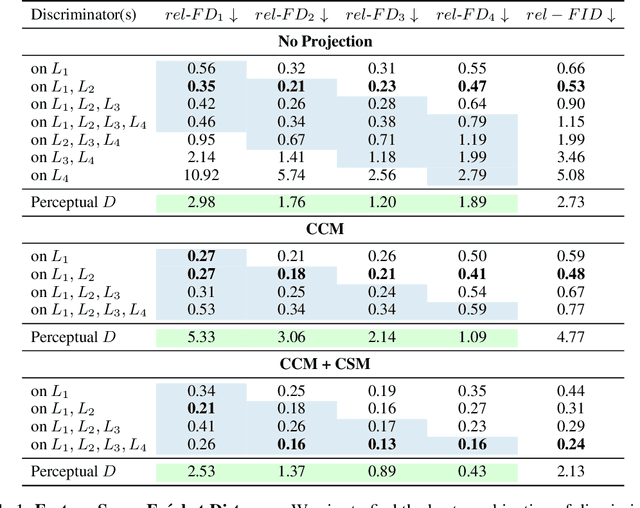
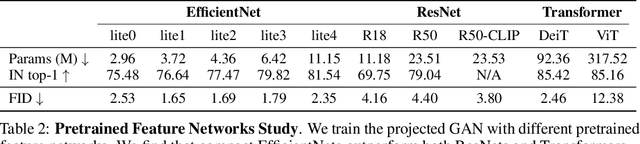
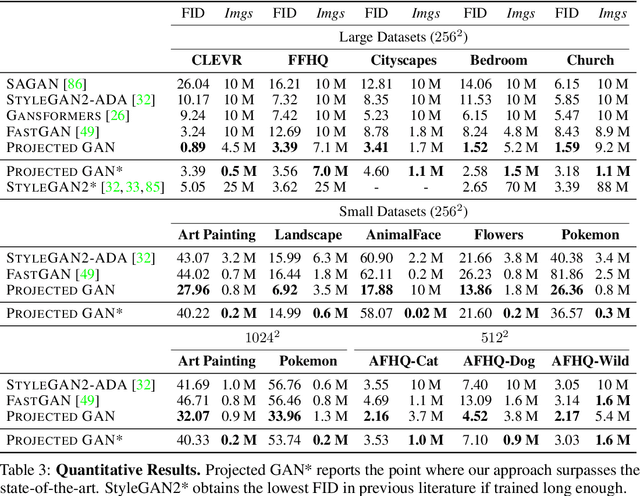
Generative Adversarial Networks (GANs) produce high-quality images but are challenging to train. They need careful regularization, vast amounts of compute, and expensive hyper-parameter sweeps. We make significant headway on these issues by projecting generated and real samples into a fixed, pretrained feature space. Motivated by the finding that the discriminator cannot fully exploit features from deeper layers of the pretrained model, we propose a more effective strategy that mixes features across channels and resolutions. Our Projected GAN improves image quality, sample efficiency, and convergence speed. It is further compatible with resolutions of up to one Megapixel and advances the state-of-the-art Fr\'echet Inception Distance (FID) on twenty-two benchmark datasets. Importantly, Projected GANs match the previously lowest FIDs up to 40 times faster, cutting the wall-clock time from 5 days to less than 3 hours given the same computational resources.
Coherent False Seizure Prediction in Epilepsy, Coincidence or Providence?
Oct 26, 2021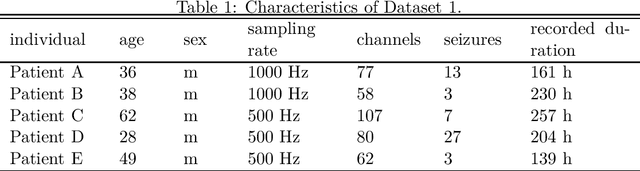
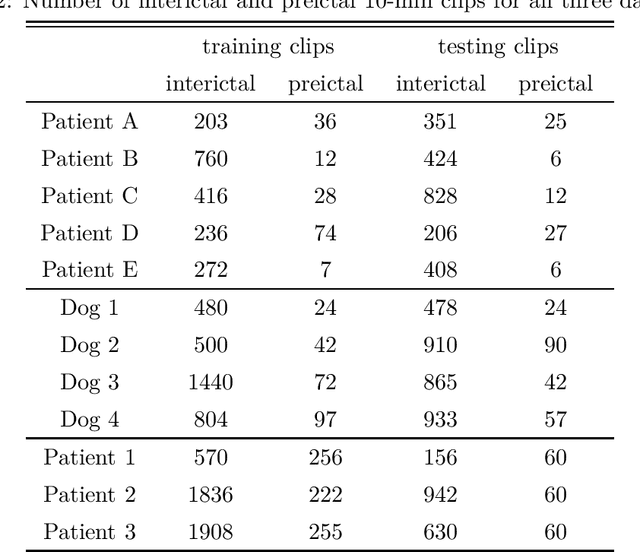
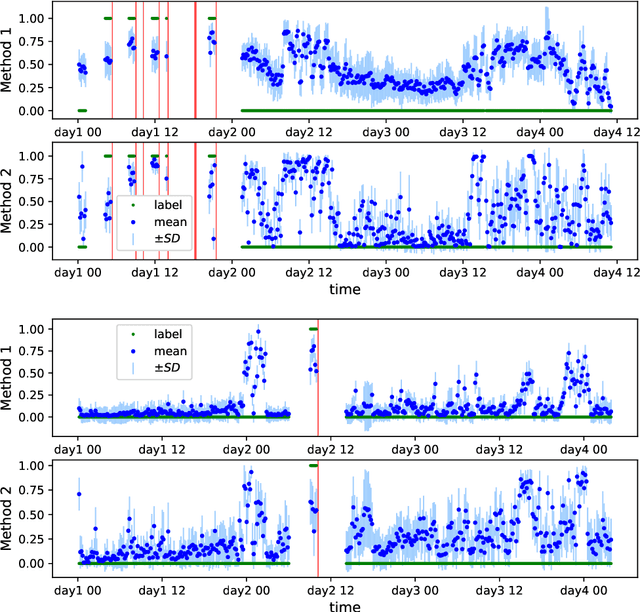
Seizure forecasting using machine learning is possible, but the performance is far from ideal, as indicated by many false predictions and low specificity. Here, we examine false and missing alarms of two algorithms on long-term datasets to show that the limitations are less related to classifiers or features, but rather to intrinsic changes in the data. We evaluated two algorithms on three datasets by computing the correlation of false predictions and estimating the information transfer between both classification methods. For 9 out of 12 individuals both methods showed a performance better than chance. For all individuals we observed a positive correlation in predictions. For individuals with strong correlation in false predictions we were able to boost the performance of one method by excluding test samples based on the results of the second method. Substantially different algorithms exhibit a highly consistent performance and a strong coherency in false and missing alarms. Hence, changing the underlying hypothesis of a preictal state of fixed time length prior to each seizure to a proictal state is more helpful than further optimizing classifiers. The outcome is significant for the evaluation of seizure prediction algorithms on continuous data.
Learning Robust Models Using The Principle of Independent Causal Mechanisms
Oct 14, 2020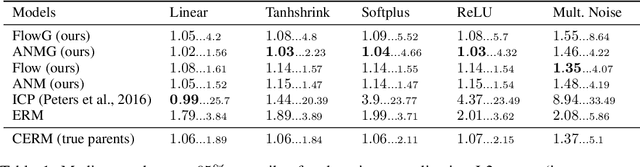

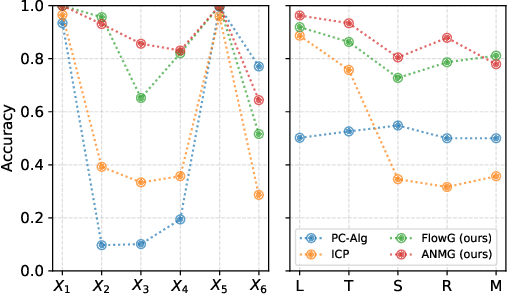
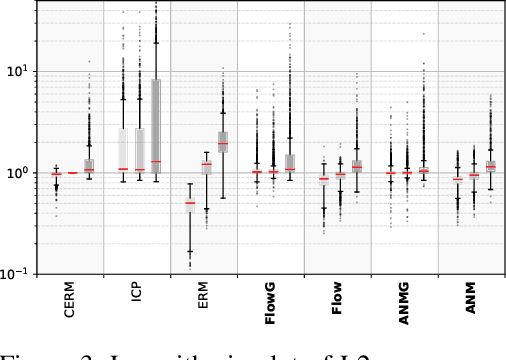
Standard supervised learning breaks down under data distribution shift. However, the principle of independent causal mechanisms (ICM, Peters et al. (2017)) can turn this weakness into an opportunity: one can take advantage of distribution shift between different environments during training in order to obtain more robust models. We propose a new gradient-based learning framework whose objective function is derived from the ICM principle. We show theoretically and experimentally that neural networks trained in this framework focus on relations remaining invariant across environments and ignore unstable ones. Moreover, we prove that the recovered stable relations correspond to the true causal mechanisms under certain conditions. In both regression and classification, the resulting models generalize well to unseen scenarios where traditionally trained models fail.
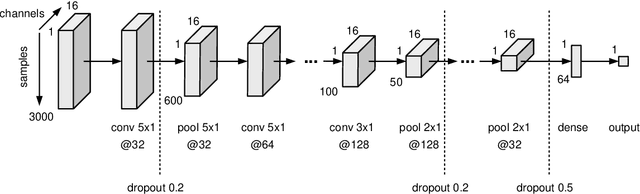
Convolutional Neural Networks for Epileptic Seizure Prediction
Nov 05, 2018
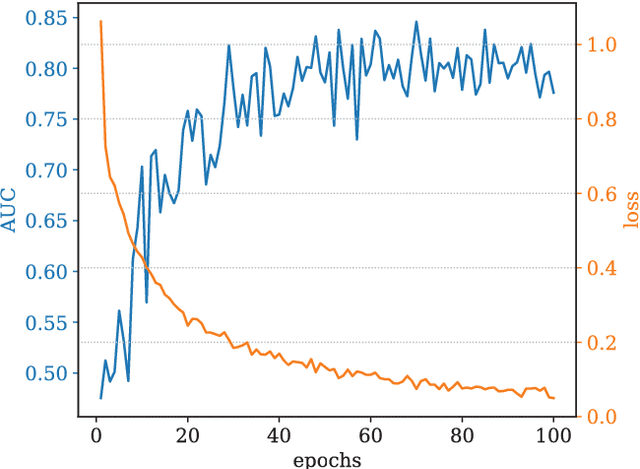
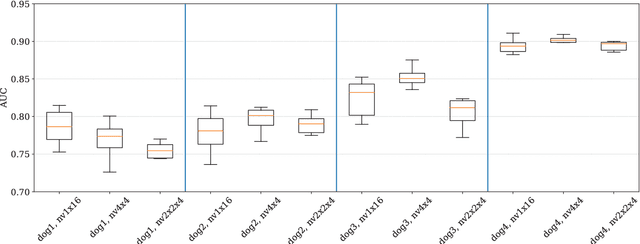
Epilepsy is the most common neurological disorder and an accurate forecast of seizures would help to overcome the patient's uncertainty and helplessness. In this contribution, we present and discuss a novel methodology for the classification of intracranial electroencephalography (iEEG) for seizure prediction. Contrary to previous approaches, we categorically refrain from an extraction of hand-crafted features and use a convolutional neural network (CNN) topology instead for both the determination of suitable signal characteristics and the binary classification of preictal and interictal segments. Three different models have been evaluated on public datasets with long-term recordings from four dogs and three patients. Overall, our findings demonstrate the general applicability. In this work we discuss the strengths and limitations of our methodology.