 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering the Definition of Adversarial Robustness for post-hoc OOD Detectors
Jun 25, 2024



Detecting out-of-distribution (OOD) inputs is critical for safely deploying deep learning models in real-world scenarios. In recent years, many OOD detectors have been developed, and even the benchmarking has been standardized, i.e. OpenOOD. The number of post-hoc detectors is growing fast and showing an option to protect a pre-trained classifier against natural distribution shifts, claiming to be ready for real-world scenarios. However, its efficacy in handling adversarial examples has been neglected in the majority of studies. This paper investigates the adversarial robustness of the 16 post-hoc detectors on several evasion attacks and discuss a roadmap towards adversarial defense in OOD detectors.
Adversarial Examples are Misaligned in Diffusion Model Manifolds
Jan 17, 2024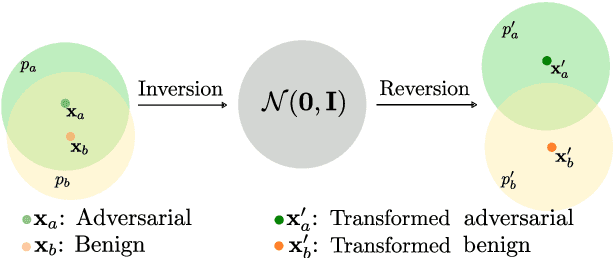
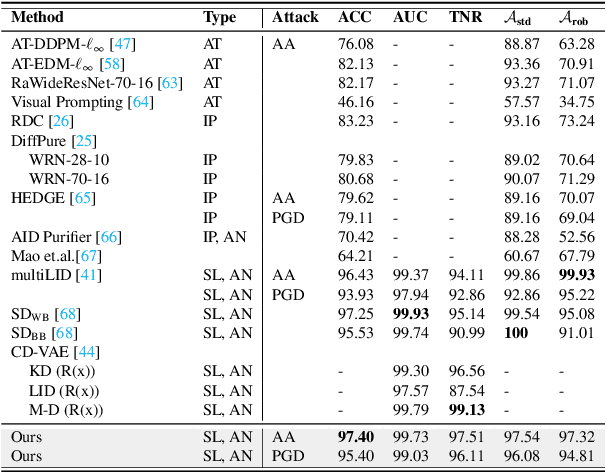
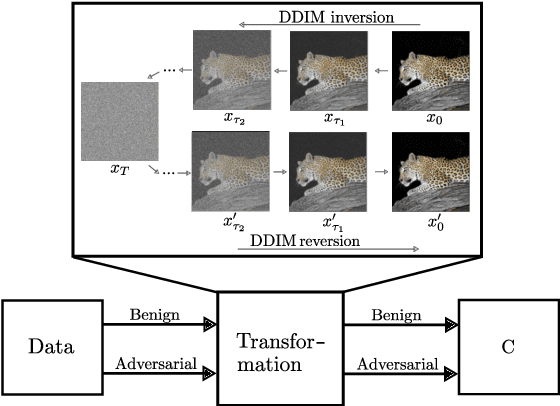
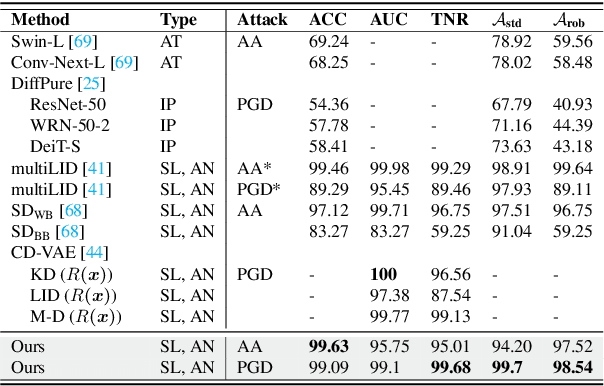
In recent years, diffusion models (DMs) have drawn significant attention for their success in approximating data distributions, yielding state-of-the-art generative results. Nevertheless, the versatility of these models extends beyond their generative capabilities to encompass various vision applications, such as image inpainting, segmentation, adversarial robustness, among others. This study is dedicated to the investigation of adversarial attacks through the lens of diffusion models. However, our objective does not involve enhancing the adversarial robustness of image classifiers. Instead, our focus lies in utilizing the diffusion model to detect and analyze the anomalies introduced by these attacks on images. To that end, we systematically examine the alignment of the distributions of adversarial examples when subjected to the process of transformation using diffusion models. The efficacy of this approach is assessed across CIFAR-10 and ImageNet datasets, including varying image sizes in the latter. The results demonstrate a notable capacity to discriminate effectively between benign and attacked images, providing compelling evidence that adversarial instances do not align with the learned manifold of the DMs.
Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
Jul 20, 2023



Diffusion models recently have been successfully applied for the visual synthesis of strikingly realistic appearing images. This raises strong concerns about their potential for malicious purposes. In this paper, we propose using the lightweight multi Local Intrinsic Dimensionality (multiLID), which has been originally developed in context of the detection of adversarial examples, for the automatic detection of synthetic images and the identification of the according generator networks. In contrast to many existing detection approaches, which often only work for GAN-generated images, the proposed method provides close to perfect detection results in many realistic use cases. Extensive experiments on known and newly created datasets demonstrate that the proposed multiLID approach exhibits superiority in diffusion detection and model identification. Since the empirical evaluations of recent publications on the detection of generated images are often mainly focused on the "LSUN-Bedroom" dataset, we further establish a comprehensive benchmark for the detection of diffusion-generated images, including samples from several diffusion models with different image sizes.
Unfolding Local Growth Rate Estimates for (Almost) Perfect Adversarial Detection
Dec 13, 2022
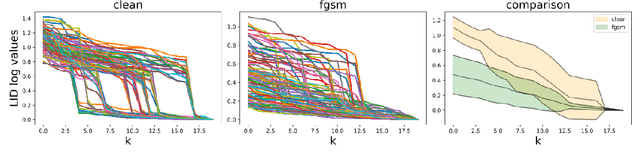
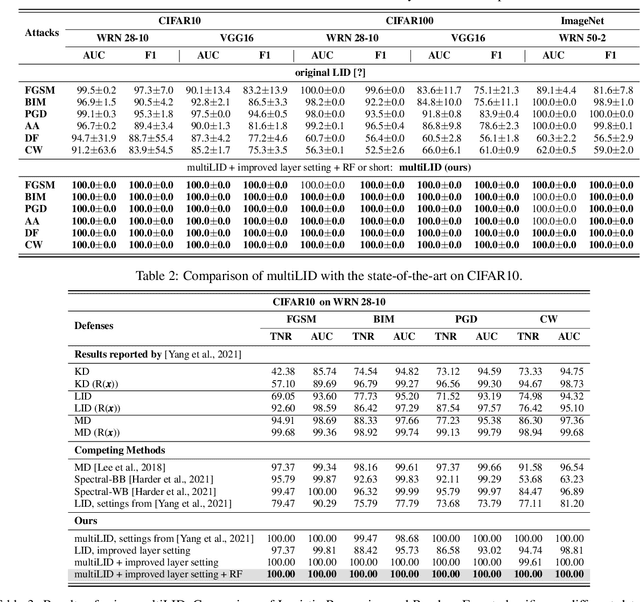
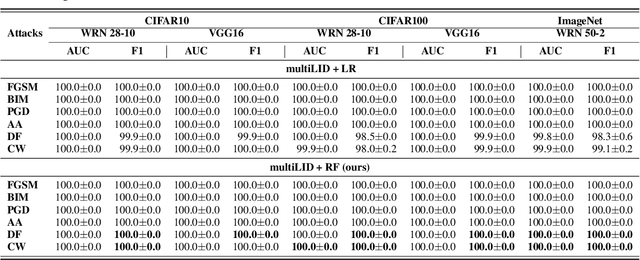
Convolutional neural networks (CNN) define the state-of-the-art solution on many perceptual tasks. However, current CNN approaches largely remain vulnerable against adversarial perturbations of the input that have been crafted specifically to fool the system while being quasi-imperceptible to the human eye. In recent years, various approaches have been proposed to defend CNNs against such attacks, for example by model hardening or by adding explicit defence mechanisms. Thereby, a small "detector" is included in the network and trained on the binary classification task of distinguishing genuine data from data containing adversarial perturbations. In this work, we propose a simple and light-weight detector, which leverages recent findings on the relation between networks' local intrinsic dimensionality (LID) and adversarial attacks. Based on a re-interpretation of the LID measure and several simple adaptations, we surpass the state-of-the-art on adversarial detection by a significant margin and reach almost perfect results in terms of F1-score for several networks and datasets. Sources available at: https://github.com/adverML/multiLID
Visual Prompting for Adversarial Robustness
Oct 12, 2022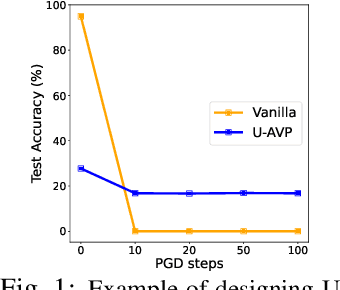
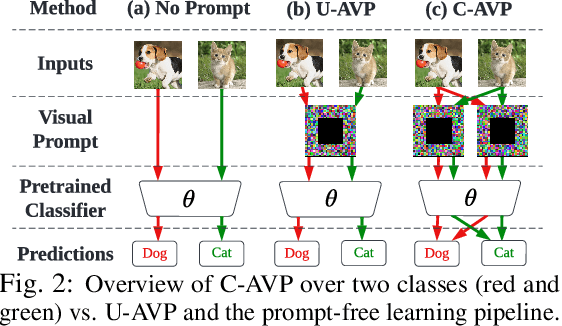


In this work, we leverage visual prompting (VP) to improve adversarial robustness of a fixed, pre-trained model at testing time. Compared to conventional adversarial defenses, VP allows us to design universal (i.e., data-agnostic) input prompting templates, which have plug-and-play capabilities at testing time to achieve desired model performance without introducing much computation overhead. Although VP has been successfully applied to improving model generalization, it remains elusive whether and how it can be used to defend against adversarial attacks. We investigate this problem and show that the vanilla VP approach is not effective in adversarial defense since a universal input prompt lacks the capacity for robust learning against sample-specific adversarial perturbations. To circumvent it, we propose a new VP method, termed Class-wise Adversarial Visual Prompting (C-AVP), to generate class-wise visual prompts so as to not only leverage the strengths of ensemble prompts but also optimize their interrelations to improve model robustness. Our experiments show that C-AVP outperforms the conventional VP method, with 2.1X standard accuracy gain and 2X robust accuracy gain. Compared to classical test-time defenses, C-AVP also yields a 42X inference time speedup.
Is RobustBench/AutoAttack a suitable Benchmark for Adversarial Robustness?
Dec 02, 2021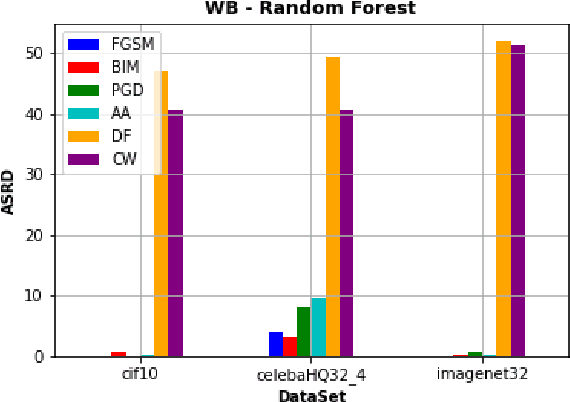
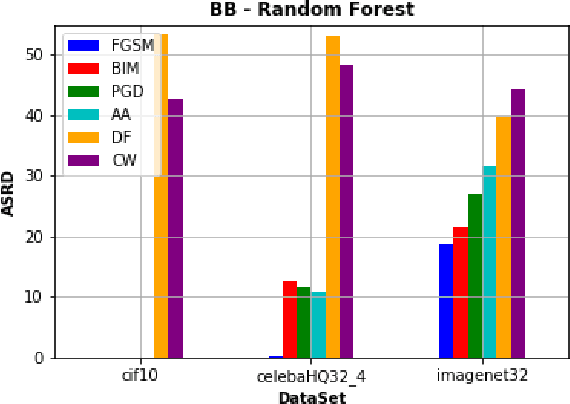
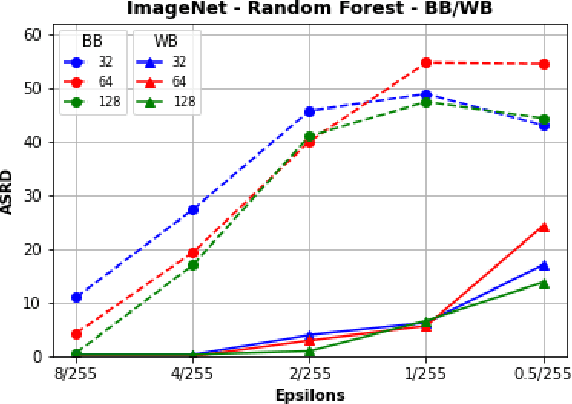
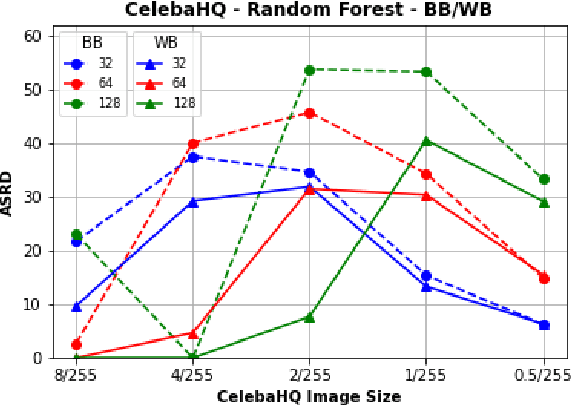
Recently, RobustBench (Croce et al. 2020) has become a widely recognized benchmark for the adversarial robustness of image classification networks. In its most commonly reported sub-task, RobustBench evaluates and ranks the adversarial robustness of trained neural networks on CIFAR10 under AutoAttack (Croce and Hein 2020b) with l-inf perturbations limited to eps = 8/255. With leading scores of the currently best performing models of around 60% of the baseline, it is fair to characterize this benchmark to be quite challenging. Despite its general acceptance in recent literature, we aim to foster discussion about the suitability of RobustBench as a key indicator for robustness which could be generalized to practical applications. Our line of argumentation against this is two-fold and supported by excessive experiments presented in this paper: We argue that I) the alternation of data by AutoAttack with l-inf, eps = 8/255 is unrealistically strong, resulting in close to perfect detection rates of adversarial samples even by simple detection algorithms and human observers. We also show that other attack methods are much harder to detect while achieving similar success rates. II) That results on low-resolution data sets like CIFAR10 do not generalize well to higher resolution images as gradient-based attacks appear to become even more detectable with increasing resolutions.
Detecting AutoAttack Perturbations in the Frequency Domain
Nov 16, 2021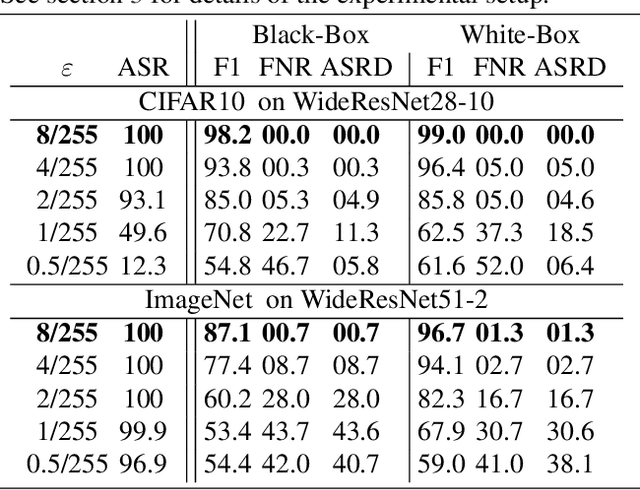
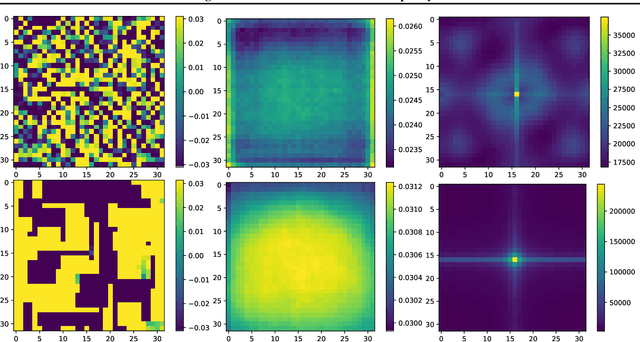

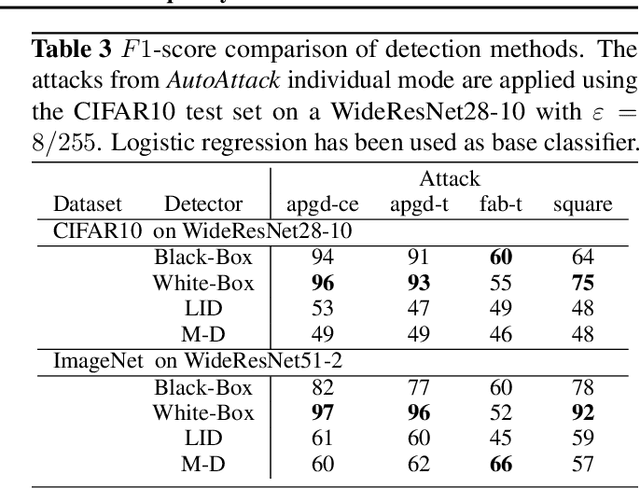
Recently, adversarial attacks on image classification networks by the AutoAttack (Croce and Hein, 2020b) framework have drawn a lot of attention. While AutoAttack has shown a very high attack success rate, most defense approaches are focusing on network hardening and robustness enhancements, like adversarial training. This way, the currently best-reported method can withstand about 66% of adversarial examples on CIFAR10. In this paper, we investigate the spatial and frequency domain properties of AutoAttack and propose an alternative defense. Instead of hardening a network, we detect adversarial attacks during inference, rejecting manipulated inputs. Based on a rather simple and fast analysis in the frequency domain, we introduce two different detection algorithms. First, a black box detector that only operates on the input images and achieves a detection accuracy of 100% on the AutoAttack CIFAR10 benchmark and 99.3% on ImageNet, for epsilon = 8/255 in both cases. Second, a whitebox detector using an analysis of CNN feature maps, leading to a detection rate of also 100% and 98.7% on the same benchmarks.