 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Learning of Aerosol Microphysics
Jul 24, 2022Aerosol particles play an important role in the climate system by absorbing and scattering radiation and influencing cloud properties. They are also one of the biggest sources of uncertainty for climate modeling. Many climate models do not include aerosols in sufficient detail due to computational constraints. In order to represent key processes, aerosol microphysical properties and processes have to be accounted for. This is done in the ECHAM-HAM global climate aerosol model using the M7 microphysics, but high computational costs make it very expensive to run with finer resolution or for a longer time. We aim to use machine learning to emulate the microphysics model at sufficient accuracy and reduce the computational cost by being fast at inference time. The original M7 model is used to generate data of input-output pairs to train a neural network on it. We are able to learn the variables' tendencies achieving an average $R^2$ score of $77.1\% $. We further explore methods to inform and constrain the neural network with physical knowledge to reduce mass violation and enforce mass positivity. On a GPU we achieve a speed-up of up to over 64x compared to the original model.
Is RobustBench/AutoAttack a suitable Benchmark for Adversarial Robustness?
Dec 02, 2021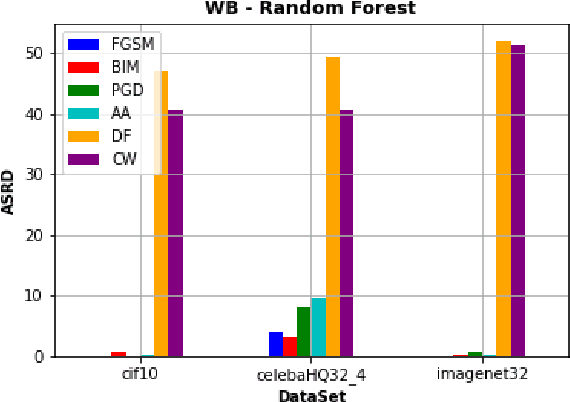
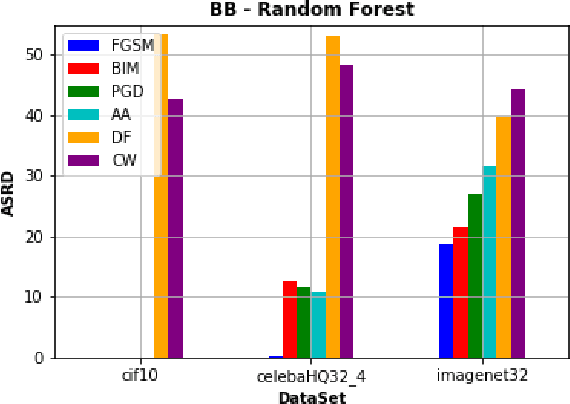
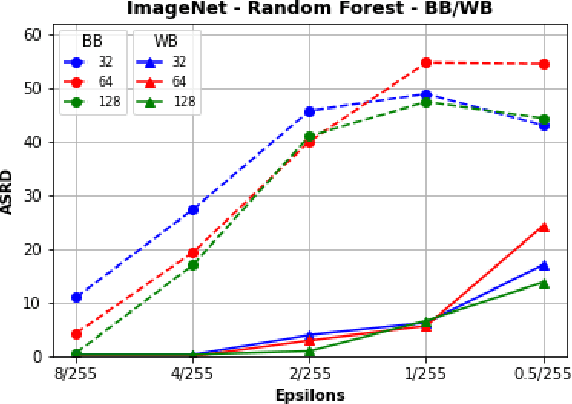
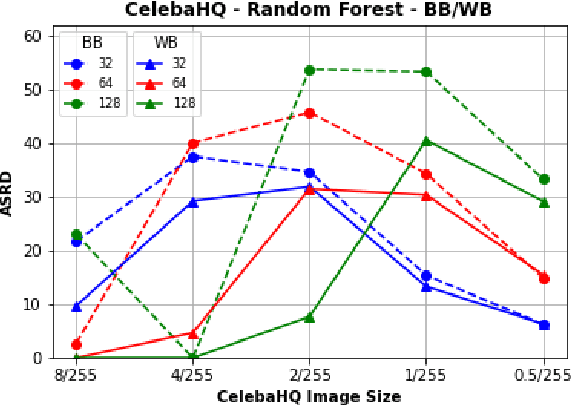
Recently, RobustBench (Croce et al. 2020) has become a widely recognized benchmark for the adversarial robustness of image classification networks. In its most commonly reported sub-task, RobustBench evaluates and ranks the adversarial robustness of trained neural networks on CIFAR10 under AutoAttack (Croce and Hein 2020b) with l-inf perturbations limited to eps = 8/255. With leading scores of the currently best performing models of around 60% of the baseline, it is fair to characterize this benchmark to be quite challenging. Despite its general acceptance in recent literature, we aim to foster discussion about the suitability of RobustBench as a key indicator for robustness which could be generalized to practical applications. Our line of argumentation against this is two-fold and supported by excessive experiments presented in this paper: We argue that I) the alternation of data by AutoAttack with l-inf, eps = 8/255 is unrealistically strong, resulting in close to perfect detection rates of adversarial samples even by simple detection algorithms and human observers. We also show that other attack methods are much harder to detect while achieving similar success rates. II) That results on low-resolution data sets like CIFAR10 do not generalize well to higher resolution images as gradient-based attacks appear to become even more detectable with increasing resolutions.
Detecting AutoAttack Perturbations in the Frequency Domain
Nov 16, 2021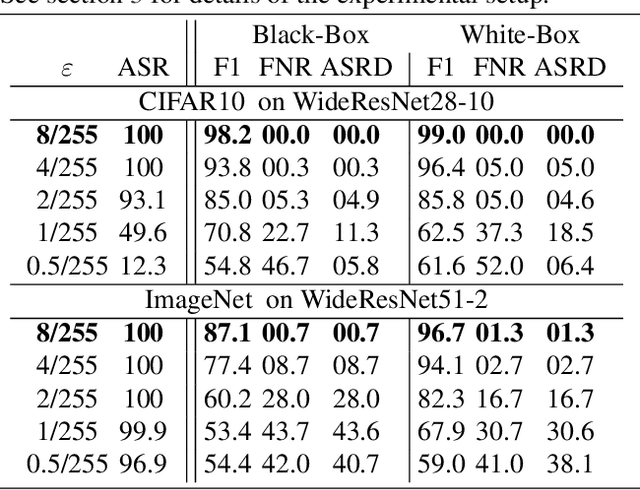
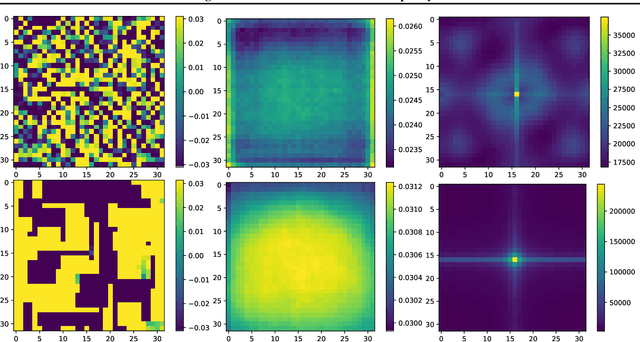

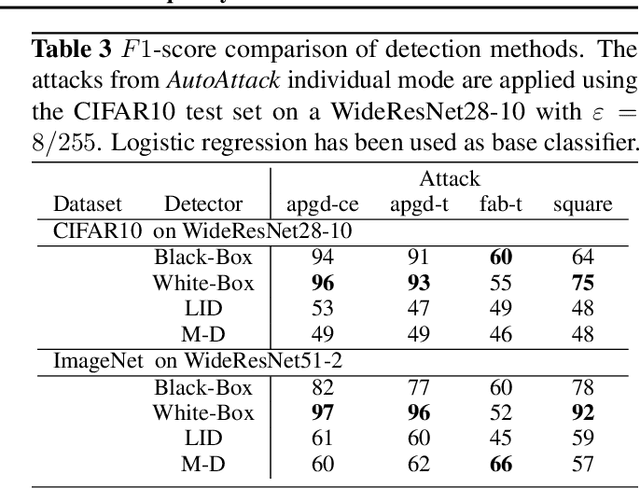
Recently, adversarial attacks on image classification networks by the AutoAttack (Croce and Hein, 2020b) framework have drawn a lot of attention. While AutoAttack has shown a very high attack success rate, most defense approaches are focusing on network hardening and robustness enhancements, like adversarial training. This way, the currently best-reported method can withstand about 66% of adversarial examples on CIFAR10. In this paper, we investigate the spatial and frequency domain properties of AutoAttack and propose an alternative defense. Instead of hardening a network, we detect adversarial attacks during inference, rejecting manipulated inputs. Based on a rather simple and fast analysis in the frequency domain, we introduce two different detection algorithms. First, a black box detector that only operates on the input images and achieves a detection accuracy of 100% on the AutoAttack CIFAR10 benchmark and 99.3% on ImageNet, for epsilon = 8/255 in both cases. Second, a whitebox detector using an analysis of CNN feature maps, leading to a detection rate of also 100% and 98.7% on the same benchmarks.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021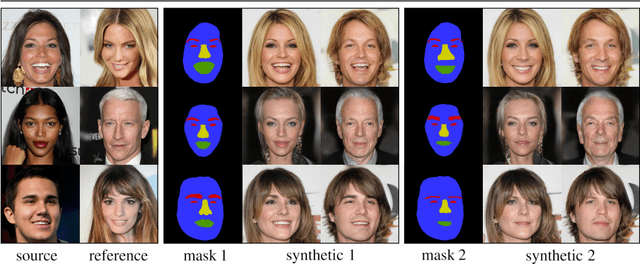
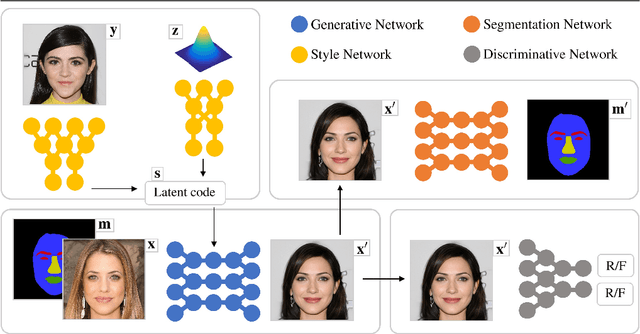

Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
Emulating Aerosol Microphysics with Machine Learning
Sep 29, 2021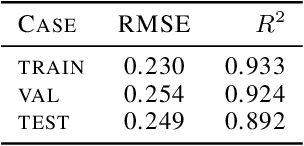
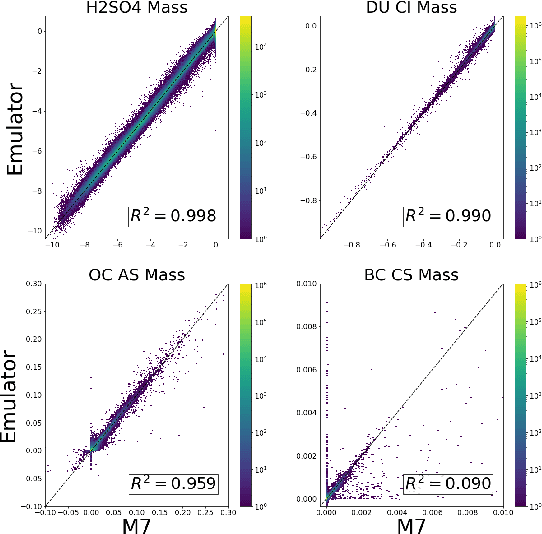
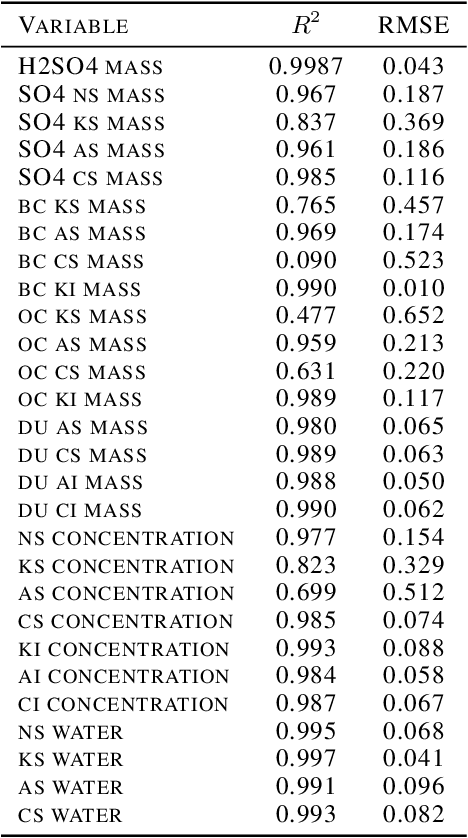
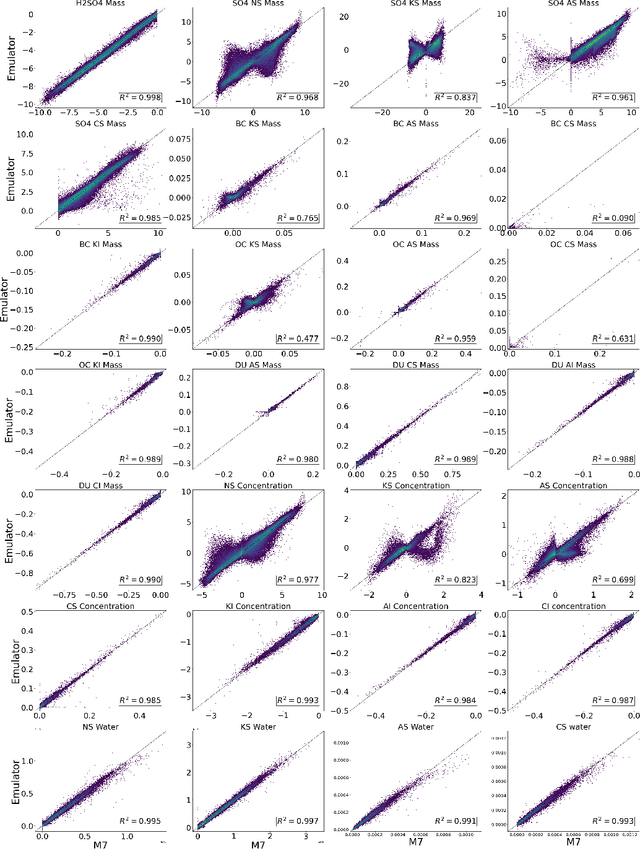
Aerosol particles play an important role in the climate system by absorbing and scattering radiation and influencing cloud properties. They are also one of the biggest sources of uncertainty for climate modeling. Many climate models do not include aerosols in sufficient detail. In order to achieve higher accuracy, aerosol microphysical properties and processes have to be accounted for. This is done in the ECHAM-HAM global climate aerosol model using the M7 microphysics model, but increased computational costs make it very expensive to run at higher resolutions or for a longer time. We aim to use machine learning to approximate the microphysics model at sufficient accuracy and reduce the computational cost by being fast at inference time. The original M7 model is used to generate data of input-output pairs to train a neural network on it. By using a special logarithmic transform we are able to learn the variables tendencies achieving an average $R^2$ score of $89\%$. On a GPU we achieve a speed-up of 120 compared to the original model.
Python Workflows on HPC Systems
Dec 01, 2020
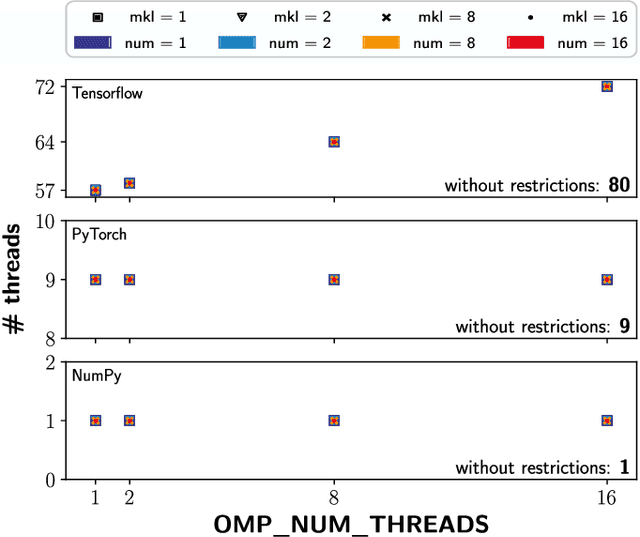
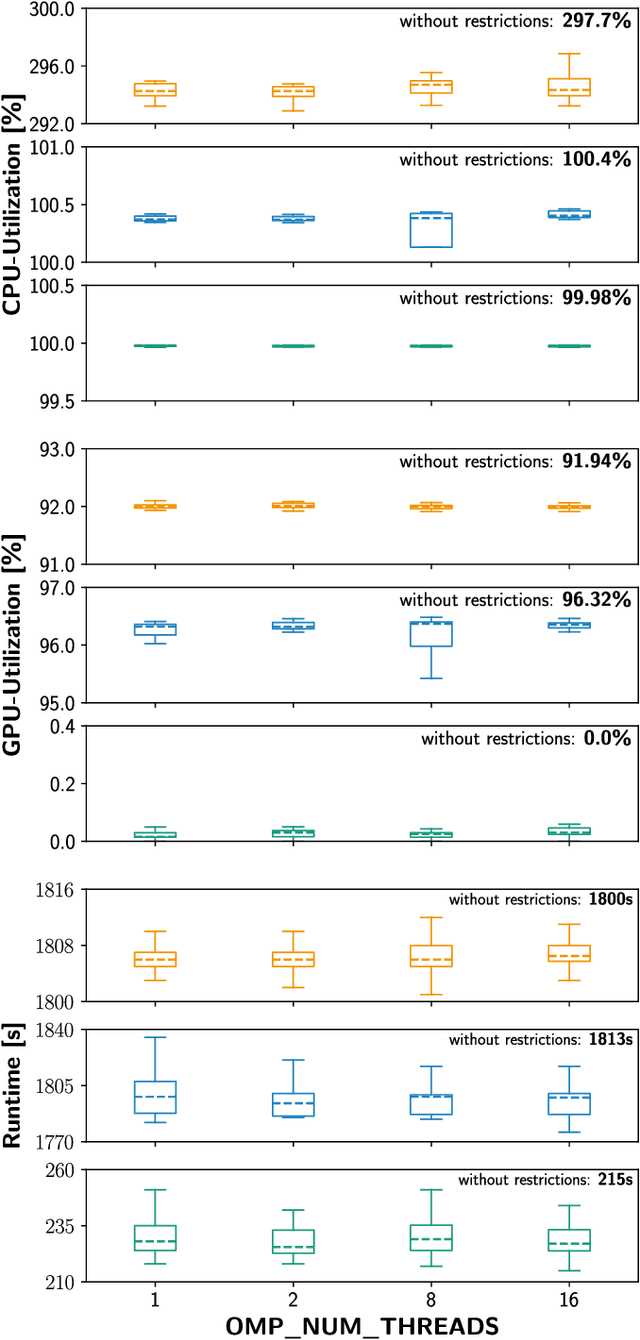
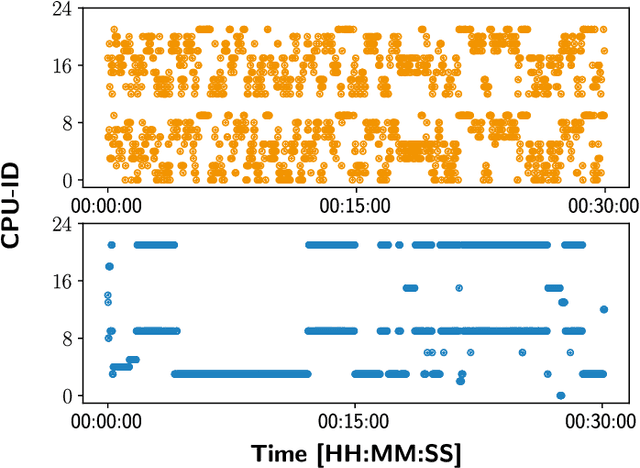
The recent successes and wide spread application of compute intensive machine learning and data analytics methods have been boosting the usage of the Python programming language on HPC systems. While Python provides many advantages for the users, it has not been designed with a focus on multi-user environments or parallel programming - making it quite challenging to maintain stable and secure Python workflows on a HPC system. In this paper, we analyze the key problems induced by the usage of Python on HPC clusters and sketch appropriate workarounds for efficiently maintaining multi-user Python software environments, securing and restricting resources of Python jobs and containing Python processes, while focusing on Deep Learning applications running on GPU clusters.