 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Cast: A Surprisingly Simple and Efficient Frontier Probabilistic AI Weather Forecaster
Apr 10, 2026AI-based weather forecasting now rivals traditional physics-based ensembles, but state-of-the-art (SOTA) models rely on specialized architectures and massive computational budgets, creating a high barrier to entry. We demonstrate that such complexity is unnecessary for frontier performance. We introduce U-Cast, a probabilistic forecaster built on a standard U-Net backbone trained with a simple recipe: deterministic pre-training on Mean Absolute Error followed by short probabilistic fine-tuning on the Continuous Ranked Probability Score (CRPS) using Monte Carlo Dropout for stochasticity. As a result, our model matches or exceeds the probabilistic skill of GenCast and IFS ENS at 1.5$^\circ\$ resolution while reducing training compute by over 10$\times$ compared to leading CRPS-based models and inference latency by over 10$\times$ compared to diffusion-based models. U-Cast trains in under 12 H200 GPU-days and generates a 60-step ensemble forecast in 11 seconds. These results suggest that scalable, general-purpose architectures paired with efficient training curricula can match complex domain-specific designs at a fraction of the cost, opening the training of frontier probabilistic weather models to the broader community. Our code is available at: https://github.com/Rose-STL-Lab/u-cast.
WaveSim: A Wavelet-based Multi-scale Similarity Metric for Weather and Climate Fields
Dec 16, 2025We introduce WaveSim, a multi-scale similarity metric for the evaluation of spatial fields in weather and climate applications. WaveSim exploits wavelet transforms to decompose input fields into scale-specific wavelet coefficients. The metric is built by multiplying three orthogonal components derived from these coefficients: Magnitude, which quantifies similarities in the energy distribution of the coefficients, i.e., the intensity of the field; Displacement, which captures spatial shift by comparing the centers of mass of normalized energy distributions; and Structure, which assesses pattern organization independent of location and amplitude. Each component yields a scale-specific similarity score ranging from 0 (no similarity) to 1 (perfect similarity), which are then combined across scales to produce an overall similarity measure. We first evaluate WaveSim using synthetic test cases, applying controlled spatial and temporal perturbations to systematically assess its sensitivity and expected behavior. We then demonstrate its applicability to physically relevant case studies of key modes of climate variability in Earth System Models. Traditional point-wise metrics lack a mechanism for attributing errors to physical scales or modes of dissimilarity. By operating in the wavelet domain and decomposing the signal along independent axes, WaveSim bypasses these limitations and provides an interpretable and diagnostically rich framework for assessing similarity in complex fields. Additionally, the WaveSim framework allows users to place emphasis on a specific scale or component, and lends itself to user-specific model intercomparison, model evaluation, and calibration and training of forecasting systems. We provide a PyTorch-ready implementation of WaveSim, along with all evaluation scripts, at: https://github.com/gabrieleaccarino/wavesim.
Discovering Latent Structural Causal Models from Spatio-Temporal Data
Nov 08, 2024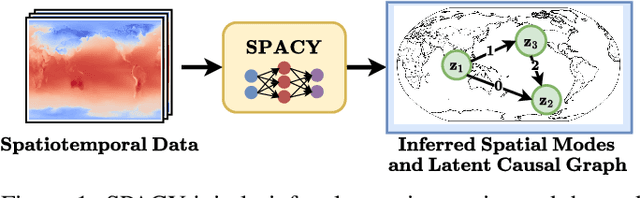

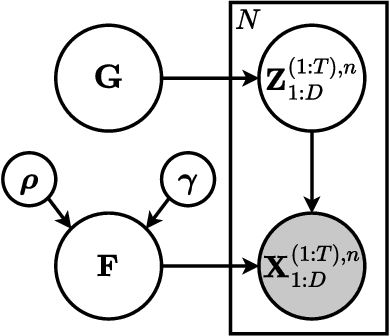
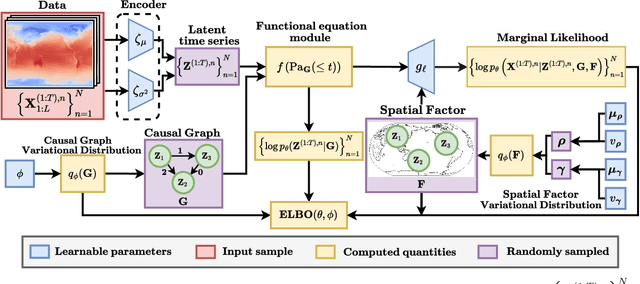
Many important phenomena in scientific fields such as climate, neuroscience, and epidemiology are naturally represented as spatiotemporal gridded data with complex interactions. For example, in climate science, researchers aim to uncover how large-scale events, such as the North Atlantic Oscillation (NAO) and the Antarctic Oscillation (AAO), influence other global processes. Inferring causal relationships from these data is a challenging problem compounded by the high dimensionality of such data and the correlations between spatially proximate points. We present SPACY (SPAtiotemporal Causal discoverY), a novel framework based on variational inference, designed to explicitly model latent time-series and their causal relationships from spatially confined modes in the data. Our method uses an end-to-end training process that maximizes an evidence-lower bound (ELBO) for the data likelihood. Theoretically, we show that, under some conditions, the latent variables are identifiable up to transformation by an invertible matrix. Empirically, we show that SPACY outperforms state-of-the-art baselines on synthetic data, remains scalable for large grids, and identifies key known phenomena from real-world climate data.
Adapting While Learning: Grounding LLMs for Scientific Problems with Intelligent Tool Usage Adaptation
Nov 01, 2024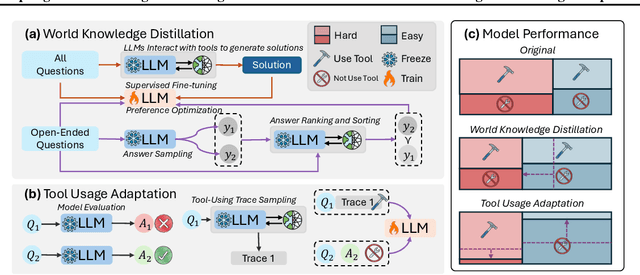
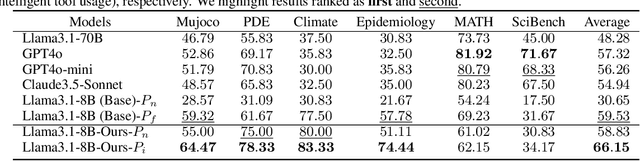
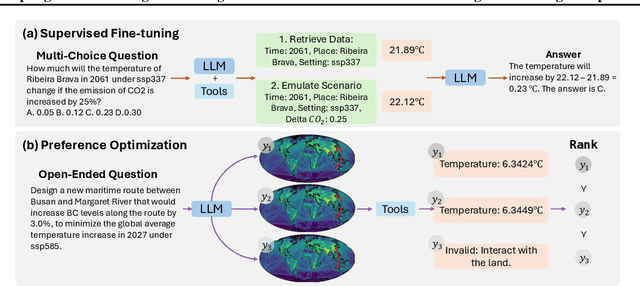
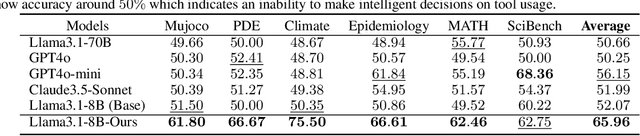
Large Language Models (LLMs) demonstrate promising capabilities in solving simple scientific problems but often produce hallucinations for complex ones. While integrating LLMs with tools can increase reliability, this approach typically results in over-reliance on tools, diminishing the model's ability to solve simple problems through basic reasoning. In contrast, human experts first assess problem complexity using domain knowledge before choosing an appropriate solution approach. Inspired by this human problem-solving process, we propose a novel two-component fine-tuning method. In the first component World Knowledge Distillation (WKD), LLMs learn directly from solutions generated using tool's information to internalize domain knowledge. In the second component Tool Usage Adaptation (TUA), we partition problems into easy and hard categories based on the model's direct answering accuracy. While maintaining the same alignment target for easy problems as in WKD, we train the model to intelligently switch to tool usage for more challenging problems. We validate our method on six scientific benchmark datasets, spanning mathematics, climate science and epidemiology. On average, our models demonstrate a 28.18% improvement in answer accuracy and a 13.89% increase in tool usage precision across all datasets, surpassing state-of-the-art models including GPT-4o and Claude-3.5.
ClimaQA: An Automated Evaluation Framework for Climate Foundation Models
Oct 22, 2024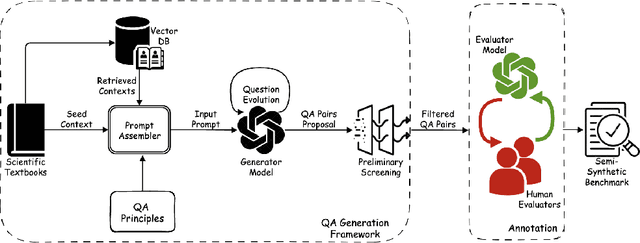
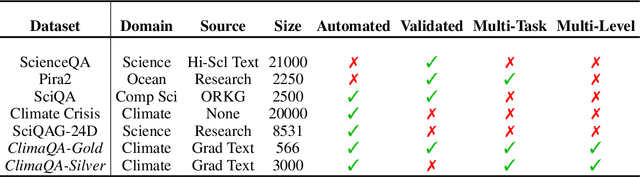

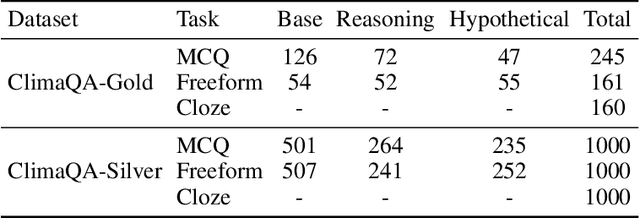
The use of foundation models in climate science has recently gained significant attention. However, a critical issue remains: the lack of a comprehensive evaluation framework capable of assessing the quality and scientific validity of model outputs. To address this issue, we develop ClimaGen (Climate QA Generator), an automated algorithmic framework that generates question-answer pairs from graduate textbooks with climate scientists in the loop. As a result, we present ClimaQA-Gold, an expert-annotated benchmark dataset alongside ClimaQA-Silver, a large-scale, comprehensive synthetic QA dataset for climate science. Finally, we develop evaluation strategies and compare different Large Language Models (LLMs) on our benchmarks. Our results offer novel insights into various approaches used to enhance climate foundation models.
Harnessing AI data-driven global weather models for climate attribution: An analysis of the 2017 Oroville Dam extreme atmospheric river
Sep 17, 2024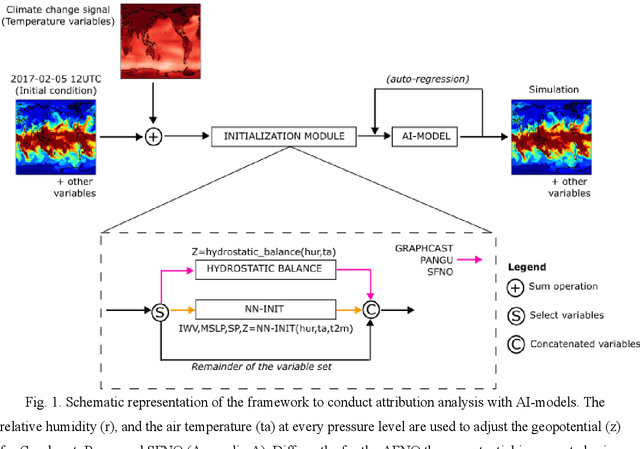
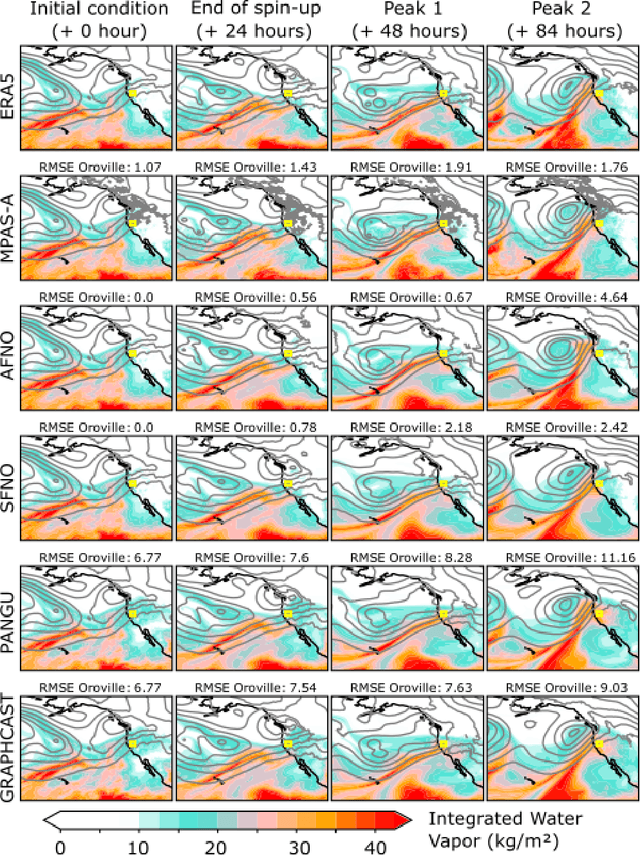
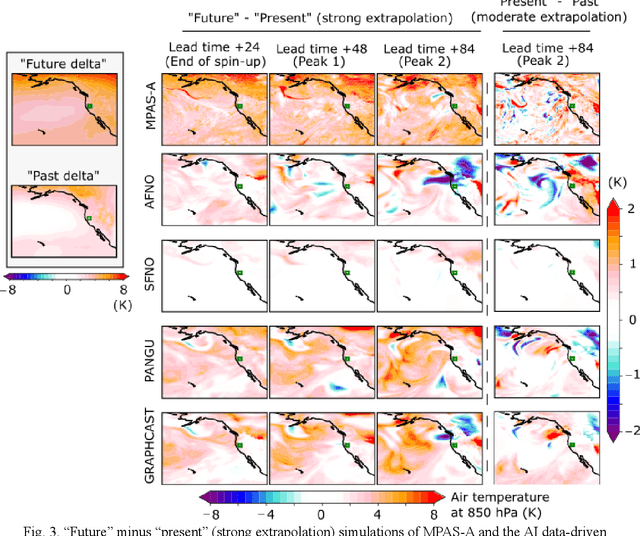
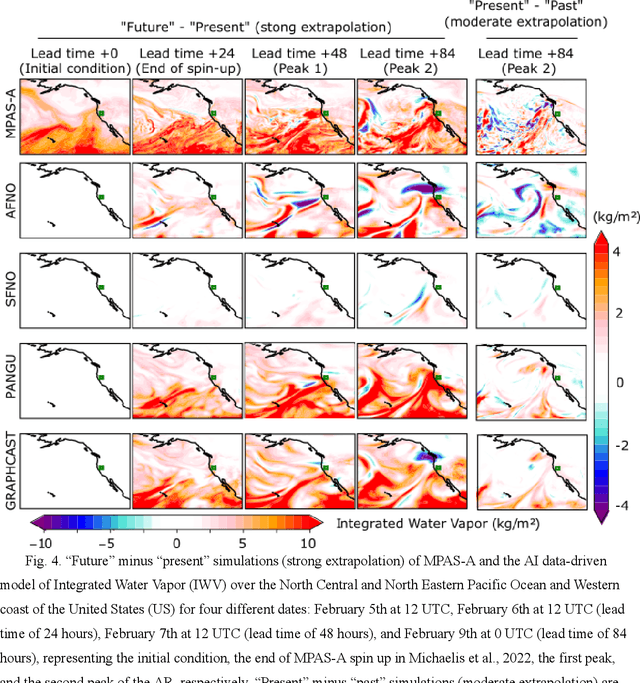
AI data-driven models (Graphcast, Pangu Weather, Fourcastnet, and SFNO) are explored for storyline-based climate attribution due to their short inference times, which can accelerate the number of events studied, and provide real time attributions when public attention is heightened. The analysis is framed on the extreme atmospheric river episode of February 2017 that contributed to the Oroville dam spillway incident in Northern California. Past and future simulations are generated by perturbing the initial conditions with the pre-industrial and the late-21st century temperature climate change signals, respectively. The simulations are compared to results from a dynamical model which represents plausible pseudo-realities under both climate environments. Overall, the AI models show promising results, projecting a 5-6 % increase in the integrated water vapor over the Oroville dam in the present day compared to the pre-industrial, in agreement with the dynamical model. Different geopotential-moisture-temperature dependencies are unveiled for each of the AI-models tested, providing valuable information for understanding the physicality of the attribution response. However, the AI models tend to simulate weaker attribution values than the pseudo-reality imagined by the dynamical model, suggesting some reduced extrapolation skill, especially for the late-21st century regime. Large ensembles generated with an AI model (>500 members) produced statistically significant present-day to pre-industrial attribution results, unlike the >20-member ensemble from the dynamical model. This analysis highlights the potential of AI models to conduct attribution analysis, while emphasizing future lines of work on explainable artificial intelligence to gain confidence in these tools, which can enable reliable attribution studies in real-time.
The impact of internal variability on benchmarking deep learning climate emulators
Aug 09, 2024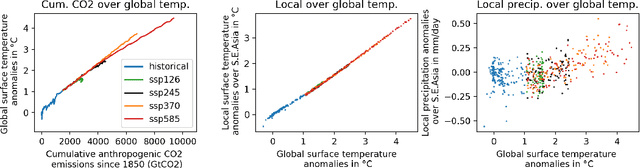
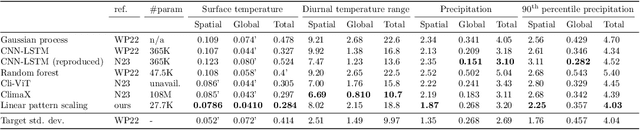
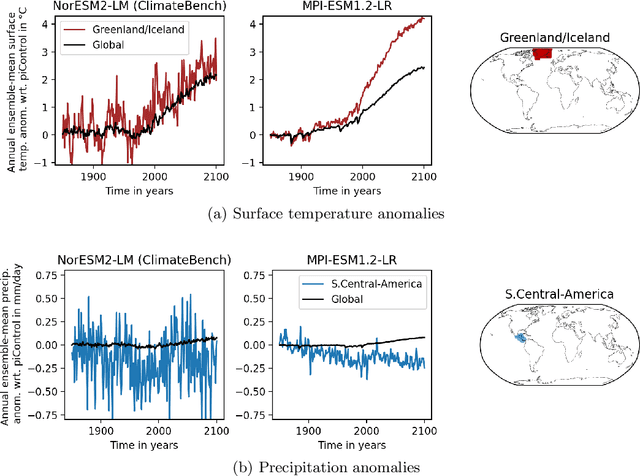
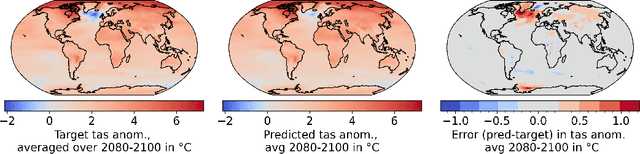
Full-complexity Earth system models (ESMs) are computationally very expensive, limiting their use in exploring the climate outcomes of multiple emission pathways. More efficient emulators that approximate ESMs can directly map emissions onto climate outcomes, and benchmarks are being used to evaluate their accuracy on standardized tasks and datasets. We investigate a popular benchmark in data-driven climate emulation, ClimateBench, on which deep learning-based emulators are currently achieving the best performance. We implement a linear regression-based emulator, akin to pattern scaling, and find that it outperforms the incumbent 100M-parameter deep learning foundation model, ClimaX, on 3 out of 4 regionally-resolved surface-level climate variables. While emulating surface temperature is expected to be predominantly linear, this result is surprising for emulating precipitation. We identify that this outcome is a result of high levels of internal variability in the benchmark targets. To address internal variability, we update the benchmark targets with ensemble averages from the MPI-ESM1.2-LR model that contain 50 instead of 3 climate simulations per emission pathway. Using the new targets, we show that linear pattern scaling continues to be more accurate on temperature, but can be outperformed by a deep learning-based model for emulating precipitation. We publish our code, data, and an interactive tutorial at github.com/blutjens/climate-emulator.
Multi-Fidelity Residual Neural Processes for Scalable Surrogate Modeling
Feb 29, 2024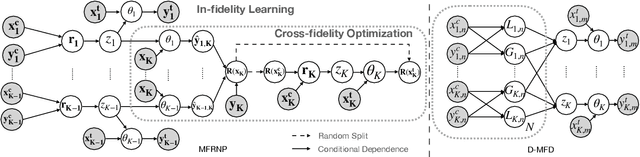
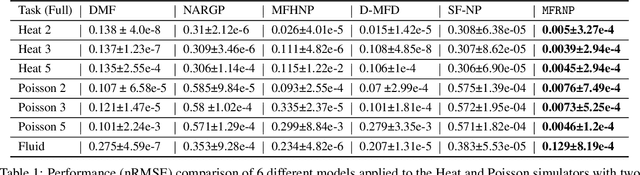
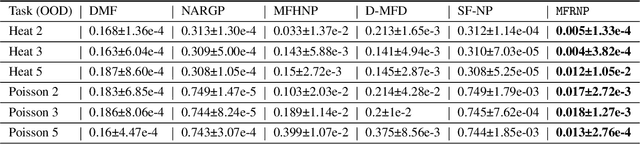
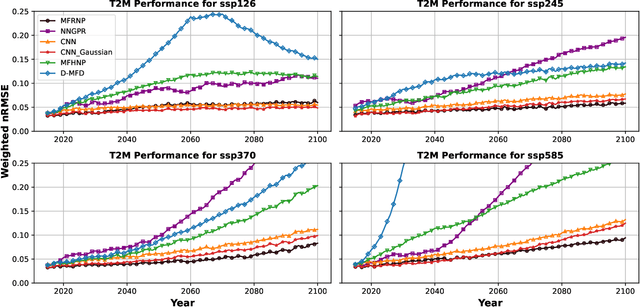
Multi-fidelity surrogate modeling aims to learn an accurate surrogate at the highest fidelity level by combining data from multiple sources. Traditional methods relying on Gaussian processes can hardly scale to high-dimensional data. Deep learning approaches utilize neural network based encoders and decoders to improve scalability. These approaches share encoded representations across fidelities without including corresponding decoder parameters. At the highest fidelity, the representations are decoded with different parameters, making the shared information inherently inaccurate. This hinders inference performance, especially in out-of-distribution scenarios when the highest fidelity data has limited domain coverage. To address these limitations, we propose Multi-fidelity Residual Neural Processes (MFRNP), a novel multi-fidelity surrogate modeling framework. MFRNP optimizes lower fidelity decoders for accurate information sharing by aggregating lower fidelity surrogate outputs and models residual between the aggregation and ground truth on the highest fidelity. We show that MFRNP significantly outperforms current state-of-the-art in learning partial differential equations and a real-world climate modeling task.
CloudTracks: A Dataset for Localizing Ship Tracks in Satellite Images of Clouds
Jan 25, 2024Clouds play a significant role in global temperature regulation through their effect on planetary albedo. Anthropogenic emissions of aerosols can alter the albedo of clouds, but the extent of this effect, and its consequent impact on temperature change, remains uncertain. Human-induced clouds caused by ship aerosol emissions, commonly referred to as ship tracks, provide visible manifestations of this effect distinct from adjacent cloud regions and therefore serve as a useful sandbox to study human-induced clouds. However, the lack of large-scale ship track data makes it difficult to deduce their general effects on cloud formation. Towards developing automated approaches to localize ship tracks at scale, we present CloudTracks, a dataset containing 3,560 satellite images labeled with more than 12,000 ship track instance annotations. We train semantic segmentation and instance segmentation model baselines on our dataset and find that our best model substantially outperforms previous state-of-the-art for ship track localization (61.29 vs. 48.65 IoU). We also find that the best instance segmentation model is able to identify the number of ship tracks in each image more accurately than the previous state-of-the-art (1.64 vs. 4.99 MAE). However, we identify cases where the best model struggles to accurately localize and count ship tracks, so we believe CloudTracks will stimulate novel machine learning approaches to better detect elongated and overlapping features in satellite images. We release our dataset openly at {zenodo.org/records/10042922}.
FaIRGP: A Bayesian Energy Balance Model for Surface Temperatures Emulation
Jul 14, 2023Emulators, or reduced complexity climate models, are surrogate Earth system models that produce projections of key climate quantities with minimal computational resources. Using time-series modeling or more advanced machine learning techniques, data-driven emulators have emerged as a promising avenue of research, producing spatially resolved climate responses that are visually indistinguishable from state-of-the-art Earth system models. Yet, their lack of physical interpretability limits their wider adoption. In this work, we introduce FaIRGP, a data-driven emulator that satisfies the physical temperature response equations of an energy balance model. The result is an emulator that (i) enjoys the flexibility of statistical machine learning models and can learn from observations, and (ii) has a robust physical grounding with interpretable parameters that can be used to make inference about the climate system. Further, our Bayesian approach allows a principled and mathematically tractable uncertainty quantification. Our model demonstrates skillful emulation of global mean surface temperature and spatial surface temperatures across realistic future scenarios. Its ability to learn from data allows it to outperform energy balance models, while its robust physical foundation safeguards against the pitfalls of purely data-driven models. We also illustrate how FaIRGP can be used to obtain estimates of top-of-atmosphere radiative forcing and discuss the benefits of its mathematical tractability for applications such as detection and attribution or precipitation emulation. We hope that this work will contribute to widening the adoption of data-driven methods in climate emulation.