 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation or Recitation? Calibrating Evaluation Scores for Machine Translation of Extremely Low-Resource Languages
Mar 26, 2026The landscape of extremely low-resource machine translation (MT) is characterized by perplexing variability in reported performance, often making results across different language pairs difficult to contextualize. For researchers focused on specific language groups -- such as ancient languages -- it is nearly impossible to determine if breakthroughs reported in other contexts (e.g., native African or American languages) result from superior methodologies or are merely artifacts of benchmark collection. To address this problem, we introduce the FRED Difficulty Metrics, which include the Fertility Ratio (F), Retrieval Proxy (R), Pre-training Exposure (E), and Corpus Diversity (D) and serve as dataset-intrinsic metrics to contextualize reported scores. These metrics reveal that a significant portion of result variability is explained by train-test overlap and pre-training exposure rather than model capability. Additionally, we identify that some languages -- particularly extinct and non-Latin indigenous languages -- suffer from poor tokenization coverage (high token fertility), highlighting a fundamental limitation of transferring models from high-resource languages that lack a shared vocabulary. By providing these indices alongside performance scores, we enable more transparent evaluation of cross-lingual transfer and provide a more reliable foundation for the XLR MT community.
Low-Resource Guidance for Controllable Latent Audio Diffusion
Mar 04, 2026Generative audio requires fine-grained controllable outputs, yet most existing methods require model retraining on specific controls or inference-time controls (\textit{e.g.}, guidance) that can also be computationally demanding. By examining the bottlenecks of existing guidance-based controls, in particular their high cost-per-step due to decoder backpropagation, we introduce a guidance-based approach through selective TFG and Latent-Control Heads (LatCHs), which enables controlling latent audio diffusion models with low computational overhead. LatCHs operate directly in latent space, avoiding the expensive decoder step, and requiring minimal training resources (7M parameters and $\approx$ 4 hours of training). Experiments with Stable Audio Open demonstrate effective control over intensity, pitch, and beats (and a combination of those) while maintaining generation quality. Our method balances precision and audio fidelity with far lower computational costs than standard end-to-end guidance. Demo examples can be found at https://zacharynovack.github.io/latch/latch.html.
From sunblock to softblock: Analyzing the correlates of neology in published writing and on social media
Feb 13, 2026Living languages are shaped by a host of conflicting internal and external evolutionary pressures. While some of these pressures are universal across languages and cultures, others differ depending on the social and conversational context: language use in newspapers is subject to very different constraints than language use on social media. Prior distributional semantic work on English word emergence (neology) identified two factors correlated with creation of new words by analyzing a corpus consisting primarily of historical published texts (Ryskina et al., 2020, arXiv:2001.07740). Extending this methodology to contextual embeddings in addition to static ones and applying it to a new corpus of Twitter posts, we show that the same findings hold for both domains, though the topic popularity growth factor may contribute less to neology on Twitter than in published writing. We hypothesize that this difference can be explained by the two domains favouring different neologism formation mechanisms.
Continuous Diffusion Models Can Obey Formal Syntax
Feb 12, 2026Diffusion language models offer a promising alternative to autoregressive models due to their global, non-causal generation process, but their continuous latent dynamics make discrete constraints -- e.g., the output should be a JSON file that matches a given schema -- difficult to impose. We introduce a training-free guidance method for steering continuous diffusion language models to satisfy formal syntactic constraints expressed using regular expressions. Our approach constructs an analytic score estimating the probability that a latent state decodes to a valid string accepted by a given regular expression, and uses its gradient to guide sampling, without training auxiliary classifiers. The denoising process targets the base model conditioned on syntactic validity. We implement our method in Diffinity on top of the PLAID diffusion model and evaluate it on 180 regular-expression constraints over JSON and natural-language benchmarks. Diffinity achieves 68-96\% constraint satisfaction while incurring only a small perplexity cost relative to unconstrained sampling, outperforming autoregressive constrained decoding in both constraint satisfaction and output quality.
UReason: Benchmarking the Reasoning Paradox in Unified Multimodal Models
Feb 09, 2026To elicit capabilities for addressing complex and implicit visual requirements, recent unified multimodal models increasingly adopt chain-of-thought reasoning to guide image generation. However, the actual effect of reasoning on visual synthesis remains unclear. We present UReason, a diagnostic benchmark for reasoning-driven image generation that evaluates whether reasoning can be faithfully executed in pixels. UReason contains 2,000 instances across five task families: Code, Arithmetic, Spatial, Attribute, and Text reasoning. To isolate the role of reasoning traces, we introduce an evaluation framework comparing direct generation, reasoning-guided generation, and de-contextualized generation which conditions only on the refined prompt. Across eight open-source unified models, we observe a consistent Reasoning Paradox: Reasoning traces generally improve performance over direct generation, yet retaining intermediate thoughts as conditioning context often hinders visual synthesis, and conditioning only on the refined prompt yields substantial gains. Our analysis suggests that the bottleneck lies in contextual interference rather than insufficient reasoning capacity. UReason provides a principled testbed for studying reasoning in unified models and motivates future methods that effectively integrate reasoning for visual generation while mitigating interference.
Steering Autoregressive Music Generation with Recursive Feature Machines
Oct 21, 2025Controllable music generation remains a significant challenge, with existing methods often requiring model retraining or introducing audible artifacts. We introduce MusicRFM, a framework that adapts Recursive Feature Machines (RFMs) to enable fine-grained, interpretable control over frozen, pre-trained music models by directly steering their internal activations. RFMs analyze a model's internal gradients to produce interpretable "concept directions", or specific axes in the activation space that correspond to musical attributes like notes or chords. We first train lightweight RFM probes to discover these directions within MusicGen's hidden states; then, during inference, we inject them back into the model to guide the generation process in real-time without per-step optimization. We present advanced mechanisms for this control, including dynamic, time-varying schedules and methods for the simultaneous enforcement of multiple musical properties. Our method successfully navigates the trade-off between control and generation quality: we can increase the accuracy of generating a target musical note from 0.23 to 0.82, while text prompt adherence remains within approximately 0.02 of the unsteered baseline, demonstrating effective control with minimal impact on prompt fidelity. We release code to encourage further exploration on RFMs in the music domain.
Constrained Adaptive Rejection Sampling
Oct 02, 2025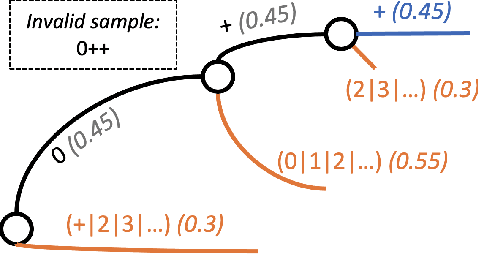
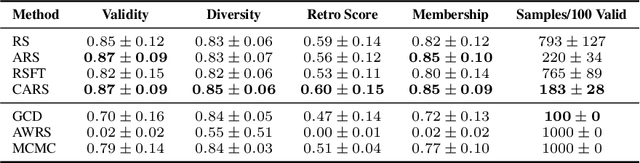
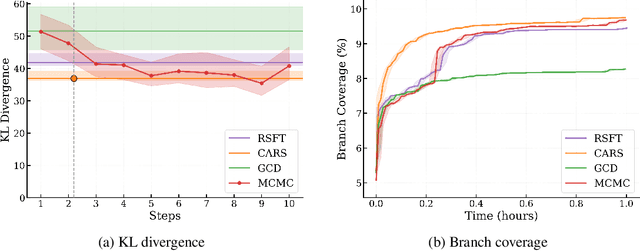
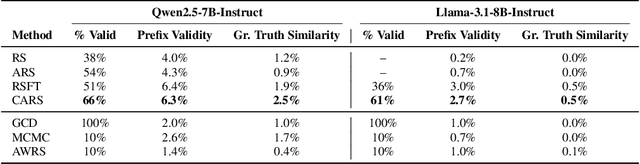
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
Bob's Confetti: Phonetic Memorization Attacks in Music and Video Generation
Jul 23, 2025Lyrics-to-Song (LS2) generation models promise end-to-end music synthesis from text, yet their vulnerability to training data memorization remains underexplored. We introduce Adversarial PhoneTic Prompting (APT), a novel attack where lyrics are semantically altered while preserving their acoustic structure through homophonic substitutions (e.g., Eminem's famous "mom's spaghetti" $\rightarrow$ "Bob's confetti"). Despite these distortions, we uncover a powerful form of sub-lexical memorization: models like SUNO and YuE regenerate outputs strikingly similar to known training content, achieving high similarity across audio-domain metrics, including CLAP, AudioJudge, and CoverID. This vulnerability persists across multiple languages and genres. More surprisingly, we discover that phoneme-altered lyrics alone can trigger visual memorization in text-to-video models. When prompted with phonetically modified lyrics from Lose Yourself, Veo 3 reconstructs visual elements from the original music video -- including character appearance and scene composition -- despite no visual cues in the prompt. We term this phenomenon phonetic-to-visual regurgitation. Together, these findings expose a critical vulnerability in transcript-conditioned multimodal generation: phonetic prompting alone can unlock memorized audiovisual content, raising urgent questions about copyright, safety, and content provenance in modern generative systems. Example generations are available on our demo page (jrohsc.github.io/music_attack/).
Constrained Sampling for Language Models Should Be Easy: An MCMC Perspective
Jun 06, 2025Constrained decoding enables Language Models (LMs) to produce samples that provably satisfy hard constraints. However, existing constrained-decoding approaches often distort the underlying model distribution, a limitation that is especially problematic in applications like program fuzzing, where one wants to generate diverse and valid program inputs for testing purposes. We propose a new constrained sampling framework based on Markov Chain Monte Carlo (MCMC) that simultaneously satisfies three core desiderata: constraint satisfying (every sample satisfies the constraint), monotonically converging (the sampling process converges to the true conditional distribution), and efficient (high-quality samples emerge in few steps). Our method constructs a proposal distribution over valid outputs and applies a Metropolis-Hastings acceptance criterion based on the LM's likelihood, ensuring principled and efficient exploration of the constrained space. Empirically, our sampler outperforms existing methods on both synthetic benchmarks and real-world program fuzzing tasks.
The Surprising Soupability of Documents in State Space Models
May 29, 2025We investigate whether hidden states from Structured State Space Models (SSMs) can be merged post-hoc to support downstream reasoning. Inspired by model souping, we propose a strategy where documents are encoded independently and their representations are pooled -- via simple operations like averaging -- into a single context state. This approach, which we call document souping, enables modular encoding and reuse without reprocessing the full input for each query. We finetune Mamba2 models to produce soupable representations and find that they support multi-hop QA, sparse retrieval, and long-document reasoning with strong accuracy. On HotpotQA, souping ten independently encoded documents nearly matches the performance of a cross-encoder trained on the same inputs.