 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Sampling for Language Models Should Be Easy: An MCMC Perspective
Jun 06, 2025Constrained decoding enables Language Models (LMs) to produce samples that provably satisfy hard constraints. However, existing constrained-decoding approaches often distort the underlying model distribution, a limitation that is especially problematic in applications like program fuzzing, where one wants to generate diverse and valid program inputs for testing purposes. We propose a new constrained sampling framework based on Markov Chain Monte Carlo (MCMC) that simultaneously satisfies three core desiderata: constraint satisfying (every sample satisfies the constraint), monotonically converging (the sampling process converges to the true conditional distribution), and efficient (high-quality samples emerge in few steps). Our method constructs a proposal distribution over valid outputs and applies a Metropolis-Hastings acceptance criterion based on the LM's likelihood, ensuring principled and efficient exploration of the constrained space. Empirically, our sampler outperforms existing methods on both synthetic benchmarks and real-world program fuzzing tasks.
Flexible and Efficient Grammar-Constrained Decoding
Feb 07, 2025



Large Language Models (LLMs) are often asked to generate structured outputs that obey precise syntactic rules, such as code snippets or formatted data. Grammar-constrained decoding (GCD) can guarantee that LLM outputs matches such rules by masking out tokens that will provably lead to outputs that do not belong to a specified context-free grammar (CFG). To guarantee soundness, GCD algorithms have to compute how a given LLM subword tokenizer can align with the tokens used by a given context-free grammar and compute token masks based on this information. Doing so efficiently is challenging and existing GCD algorithms require tens of minutes to preprocess common grammars. We present a new GCD algorithm together with an implementation that offers 17.71x faster offline preprocessing than existing approaches while preserving state-of-the-art efficiency in online mask computation.
Grammar-Aligned Decoding
May 31, 2024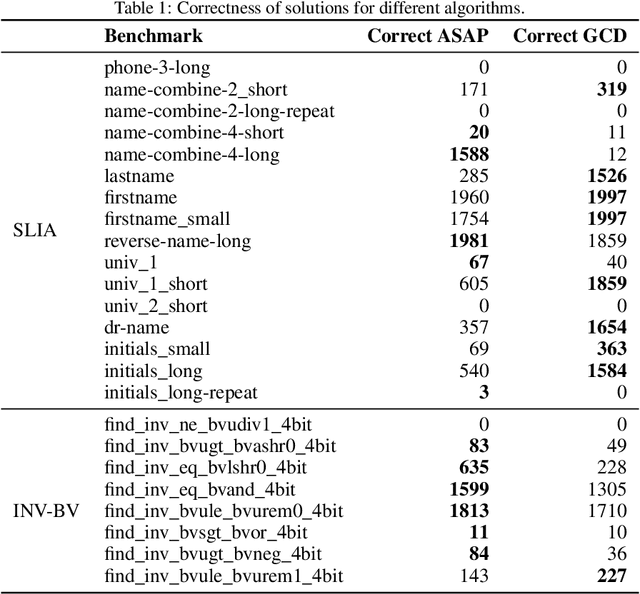
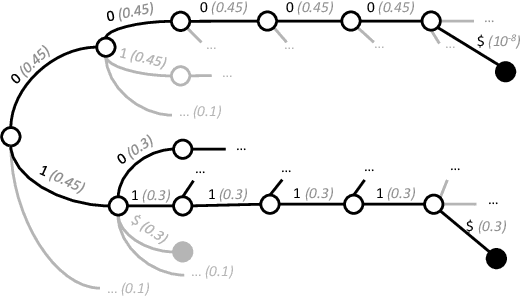

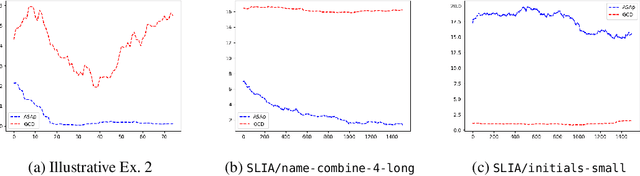
Large Language Models (LLMs) struggle with reliably generating highly structured outputs, such as program code, mathematical formulas, or well-formed markup. Constrained decoding approaches mitigate this problem by greedily restricting what tokens an LLM can output at each step to guarantee that the output matches a given constraint. Specifically, in grammar-constrained decoding (GCD), the LLM's output must follow a given grammar. In this paper we demonstrate that GCD techniques (and in general constrained decoding techniques) can distort the LLM's distribution, leading to outputs that are grammatical but appear with likelihoods that are not proportional to the ones given by the LLM, and so ultimately are low-quality. We call the problem of aligning sampling with a grammar constraint, grammar-aligned decoding (GAD), and propose adaptive sampling with approximate expected futures (ASAp), a decoding algorithm that guarantees the output to be grammatical while provably producing outputs that match the conditional probability of the LLM's distribution conditioned on the given grammar constraint. Our algorithm uses prior sample outputs to soundly overapproximate the future grammaticality of different output prefixes. Our evaluation on code generation and structured NLP tasks shows how ASAp often produces outputs with higher likelihood (according to the LLM's distribution) than existing GCD techniques, while still enforcing the desired grammatical constraints.