 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLDe: Intentional Code Generation via Human-in-the-Loop Decoding
May 28, 2025While AI programming tools hold the promise of increasing programmers' capabilities and productivity to a remarkable degree, they often exclude users from essential decision-making processes, causing many to effectively "turn off their brains" and over-rely on solutions provided by these systems. These behaviors can have severe consequences in critical domains, like software security. We propose Human-in-the-loop Decoding, a novel interaction technique that allows users to observe and directly influence LLM decisions during code generation, in order to align the model's output with their personal requirements. We implement this technique in HiLDe, a code completion assistant that highlights critical decisions made by the LLM and provides local alternatives for the user to explore. In a within-subjects study (N=18) on security-related tasks, we found that HiLDe led participants to generate significantly fewer vulnerabilities and better align code generation with their goals compared to a traditional code completion assistant.
Grammar-Aligned Decoding
May 31, 2024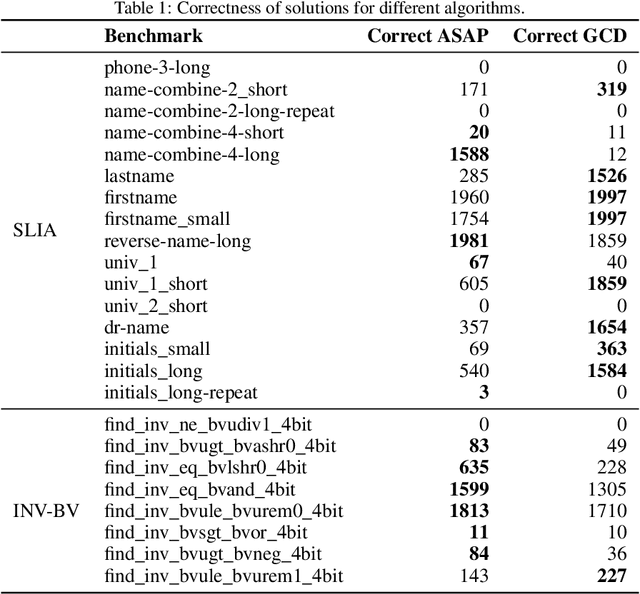
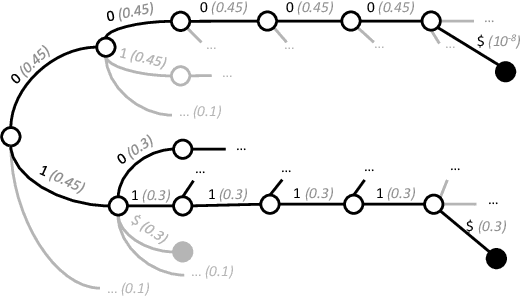

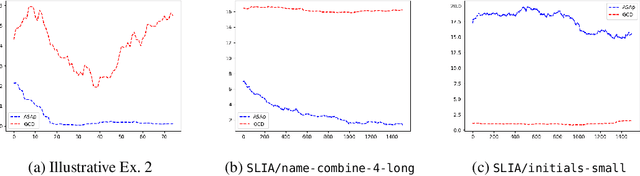
Large Language Models (LLMs) struggle with reliably generating highly structured outputs, such as program code, mathematical formulas, or well-formed markup. Constrained decoding approaches mitigate this problem by greedily restricting what tokens an LLM can output at each step to guarantee that the output matches a given constraint. Specifically, in grammar-constrained decoding (GCD), the LLM's output must follow a given grammar. In this paper we demonstrate that GCD techniques (and in general constrained decoding techniques) can distort the LLM's distribution, leading to outputs that are grammatical but appear with likelihoods that are not proportional to the ones given by the LLM, and so ultimately are low-quality. We call the problem of aligning sampling with a grammar constraint, grammar-aligned decoding (GAD), and propose adaptive sampling with approximate expected futures (ASAp), a decoding algorithm that guarantees the output to be grammatical while provably producing outputs that match the conditional probability of the LLM's distribution conditioned on the given grammar constraint. Our algorithm uses prior sample outputs to soundly overapproximate the future grammaticality of different output prefixes. Our evaluation on code generation and structured NLP tasks shows how ASAp often produces outputs with higher likelihood (according to the LLM's distribution) than existing GCD techniques, while still enforcing the desired grammatical constraints.
Laurel: Generating Dafny Assertions Using Large Language Models
May 27, 2024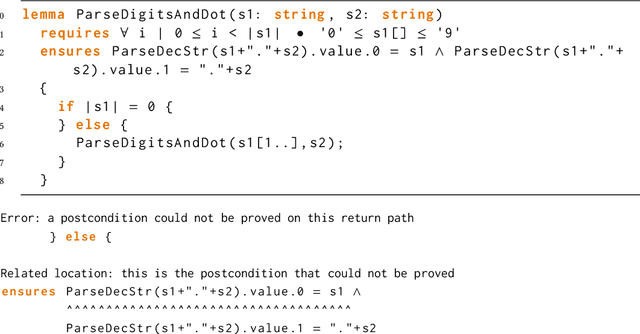

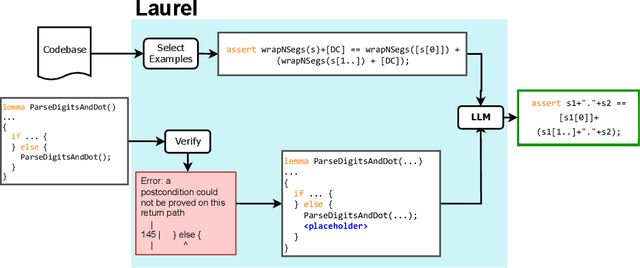

Dafny is a popular verification language, which automates proofs by outsourcing them to an SMT solver. This automation is not perfect, however, and the solver often requires guidance in the form of helper assertions creating a burden for the proof engineer. In this paper, we propose Laurel, a tool that uses large language models (LLMs) to automatically generate helper assertions for Dafny programs. To improve the success rate of LLMs in this task, we design two domain-specific prompting techniques. First, we help the LLM determine the location of the missing assertion by analyzing the verifier's error message and inserting an assertion placeholder at that location. Second, we provide the LLM with example assertions from the same codebase, which we select based on a new lemma similarity metric. We evaluate our techniques on a dataset of helper assertions we extracted from three real-world Dafny codebases. Our evaluation shows that Laurel is able to generate over 50% of the required helper assertions given only a few attempts, making LLMs a usable and affordable tool to further automate practical program verification.
HYSYNTH: Context-Free LLM Approximation for Guiding Program Synthesis
May 24, 2024Many structured prediction and reasoning tasks can be framed as program synthesis problems, where the goal is to generate a program in a domain-specific language (DSL) that transforms input data into the desired output. Unfortunately, purely neural approaches, such as large language models (LLMs), often fail to produce fully correct programs in unfamiliar DSLs, while purely symbolic methods based on combinatorial search scale poorly to complex problems. Motivated by these limitations, we introduce a hybrid approach, where LLM completions for a given task are used to learn a task-specific, context-free surrogate model, which is then used to guide program synthesis. We evaluate this hybrid approach on three domains, and show that it outperforms both unguided search and direct sampling from LLMs, as well as existing program synthesizers.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024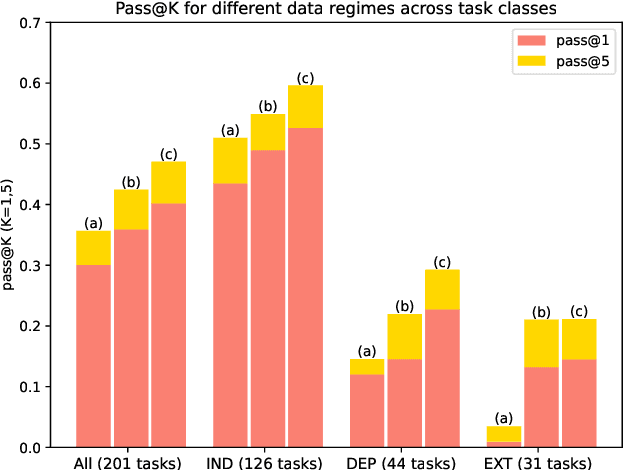
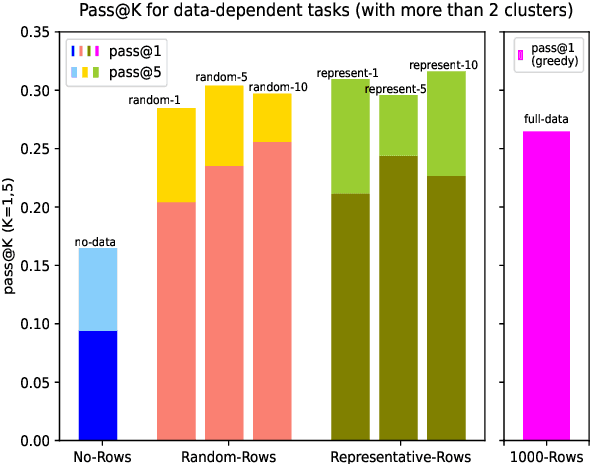
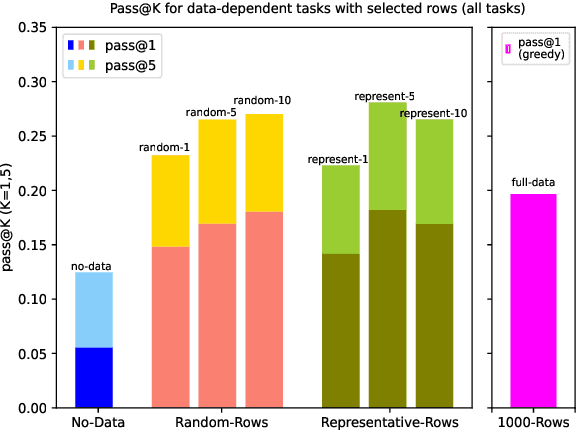
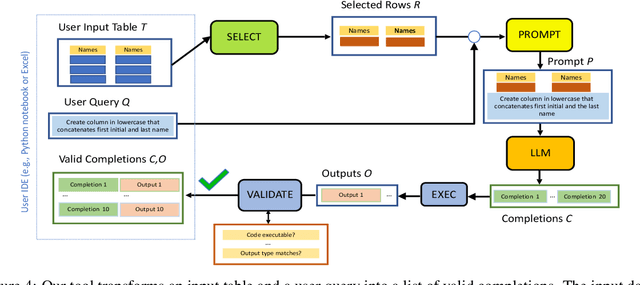
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.