 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"If You're Very Clever, No One Knows You've Used It": The Social Dynamics of Developing Generative AI Literacy in the Workplace
Feb 01, 2026Generative AI (GenAI) tools are rapidly transforming knowledge work, making AI literacy a critical priority for organizations. However, research on AI literacy lacks empirical insight into how knowledge workers' beliefs around GenAI literacy are shaped by the social dynamics of the workplace, and how workers learn to apply GenAI tools in these environments. To address this gap, we conducted in-depth interviews with 19 knowledge workers across multiple sectors to examine how they develop GenAI competencies in real-world professional contexts. We found that, while knowledge sharing from colleagues supported learning, the ability to remove cues indicating GenAI use was perceived as validation of domain expertise. These behaviours ultimately reduced opportunities for learning via knowledge sharing and undermined transparency. To advance workplace AI literacy, we argue for fostering open dialogue, increasing visibility of user-generated knowledge, and greater emphasis on the benefits of collaborative learning for navigating rapid technological developments.
An Experimental Comparison of Cognitive Forcing Functions for Execution Plans in AI-Assisted Writing: Effects On Trust, Overreliance, and Perceived Critical Thinking
Jan 25, 2026Generative AI (GenAI) tools improve productivity in knowledge workflows such as writing, but also risk overreliance and reduced critical thinking. Cognitive forcing functions (CFFs) mitigate these risks by requiring active engagement with AI output. As GenAI workflows grow more complex, systems increasingly present execution plans for user review. However, these plans are themselves AI-generated and prone to overreliance, and the effectiveness of applying CFFs to AI plans remains underexplored. We conduct a controlled experiment in which participants completed AI-assisted writing tasks while reviewing AI-generated plans under four CFF conditions: Assumption (argument analysis), WhatIf (hypothesis testing), Both, and a no-CFF control. A follow-up think-aloud and interview study qualitatively compared these conditions. Results show that the Assumption CFF most effectively reduced overreliance without increasing cognitive load, while participants perceived the WhatIf CFF as most helpful. These findings highlight the value of plan-focused CFFs for supporting critical reflection in GenAI-assisted knowledge work.
Understanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
Dynamic Prompt Middleware: Contextual Prompt Refinement Controls for Comprehension Tasks
Dec 03, 2024

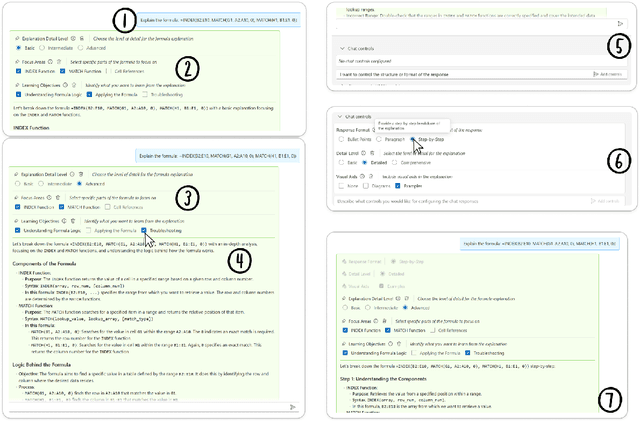

Effective prompting of generative AI is challenging for many users, particularly in expressing context for comprehension tasks such as explaining spreadsheet formulas, Python code, and text passages. Prompt middleware aims to address this barrier by assisting in prompt construction, but barriers remain for users in expressing adequate control so that they can receive AI-responses that match their preferences. We conduct a formative survey (n=38) investigating user needs for control over AI-generated explanations in comprehension tasks, which uncovers a trade-off between standardized but predictable support for prompting, and adaptive but unpredictable support tailored to the user and task. To explore this trade-off, we implement two prompt middleware approaches: Dynamic Prompt Refinement Control (Dynamic PRC) and Static Prompt Refinement Control (Static PRC). The Dynamic PRC approach generates context-specific UI elements that provide prompt refinements based on the user's prompt and user needs from the AI, while the Static PRC approach offers a preset list of generally applicable refinements. We evaluate these two approaches with a controlled user study (n=16) to assess the impact of these approaches on user control of AI responses for crafting better explanations. Results show a preference for the Dynamic PRC approach as it afforded more control, lowered barriers to providing context, and encouraged exploration and reflection of the tasks, but that reasoning about the effects of different generated controls on the final output remains challenging. Drawing on participant feedback, we discuss design implications for future Dynamic PRC systems that enhance user control of AI responses. Our findings suggest that dynamic prompt middleware can improve the user experience of generative AI workflows by affording greater control and guide users to a better AI response.
Evaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Aug 16, 2024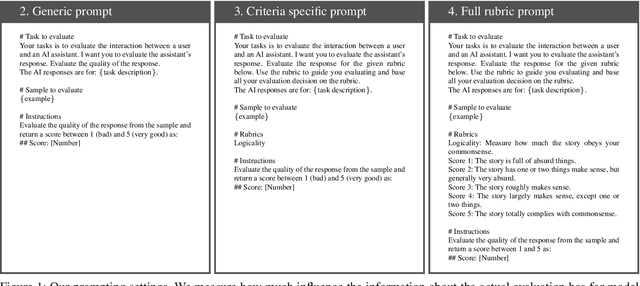
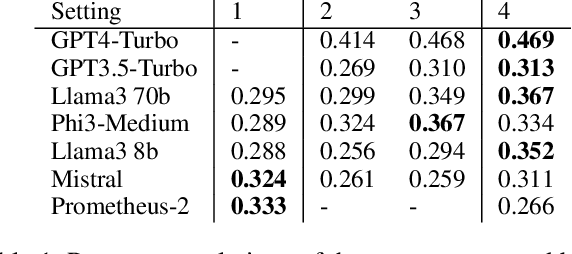
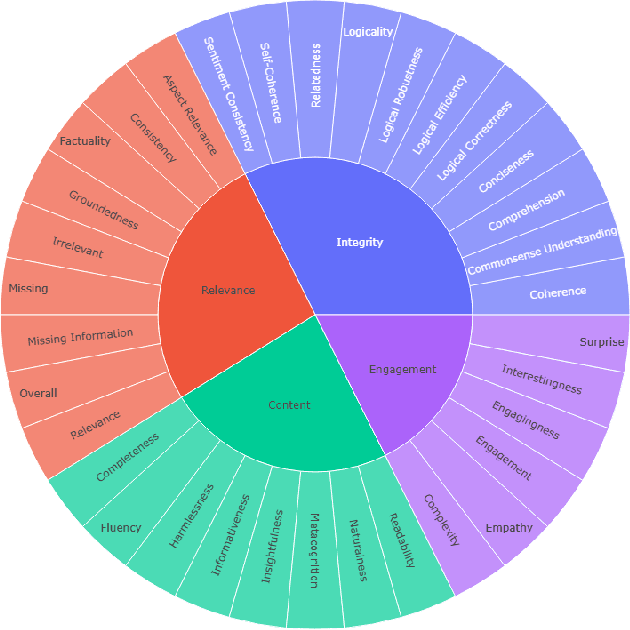
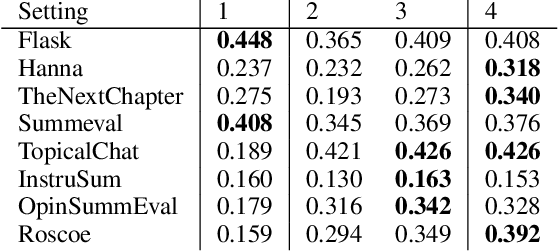
LLMs-as-a-judge is a recently popularized method which replaces human judgements in task evaluation (Zheng et al. 2024) with automatic evaluation using LLMs. Due to widespread use of RLHF (Reinforcement Learning from Human Feedback), state-of-the-art LLMs like GPT4 and Llama3 are expected to have strong alignment with human preferences when prompted for a quality judgement, such as the coherence of a text. While this seems beneficial, it is not clear whether the assessments by an LLM-as-a-judge constitute only an evaluation based on the instructions in the prompts, or reflect its preference for high-quality data similar to its fine-tune data. To investigate how much influence prompting the LLMs-as-a-judge has on the alignment of AI judgements to human judgements, we analyze prompts with increasing levels of instructions about the target quality of an evaluation, for several LLMs-as-a-judge. Further, we compare to a prompt-free method using model perplexity as a quality measure instead. We aggregate a taxonomy of quality criteria commonly used across state-of-the-art evaluations with LLMs and provide this as a rigorous benchmark of models as judges. Overall, we show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.
Improving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition
Jul 02, 2024



LLM-powered tools like ChatGPT Data Analysis, have the potential to help users tackle the challenging task of data analysis programming, which requires expertise in data processing, programming, and statistics. However, our formative study (n=15) uncovered serious challenges in verifying AI-generated results and steering the AI (i.e., guiding the AI system to produce the desired output). We developed two contrasting approaches to address these challenges. The first (Stepwise) decomposes the problem into step-by-step subgoals with pairs of editable assumptions and code until task completion, while the second (Phasewise) decomposes the entire problem into three editable, logical phases: structured input/output assumptions, execution plan, and code. A controlled, within-subjects experiment (n=18) compared these systems against a conversational baseline. Users reported significantly greater control with the Stepwise and Phasewise systems, and found intervention, correction, and verification easier, compared to the baseline. The results suggest design guidelines and trade-offs for AI-assisted data analysis tools.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024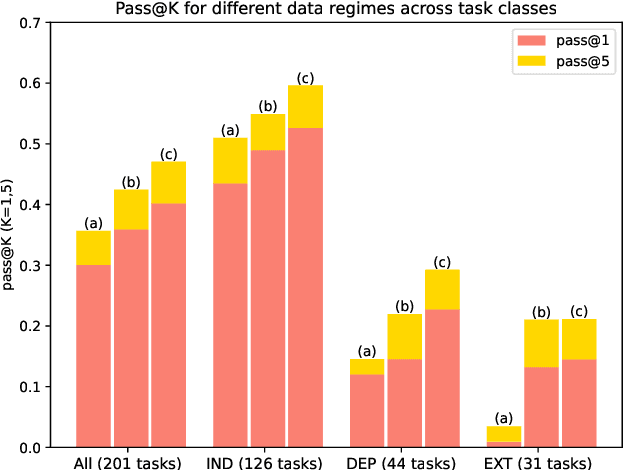
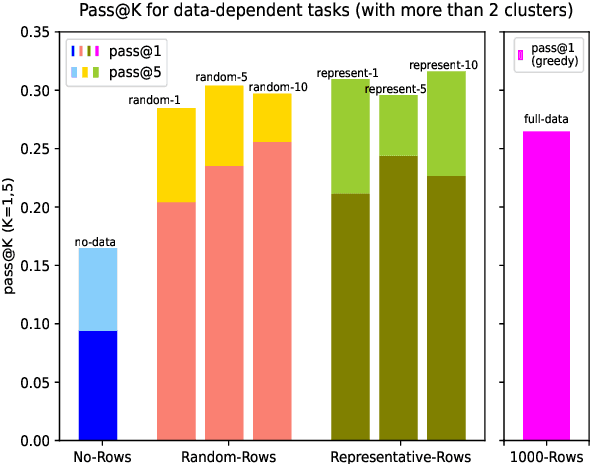
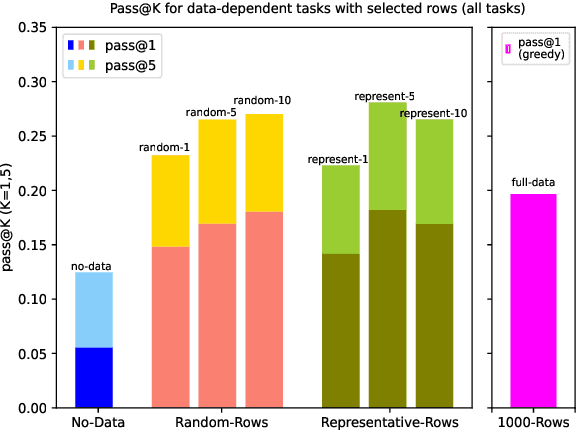
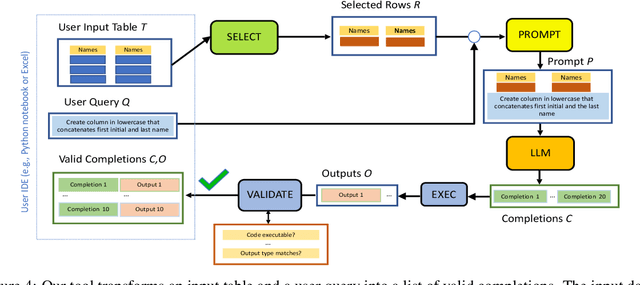
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Will Code Remain a Relevant User Interface for End-User Programming with Generative AI Models?
Nov 01, 2023The research field of end-user programming has largely been concerned with helping non-experts learn to code sufficiently well in order to achieve their tasks. Generative AI stands to obviate this entirely by allowing users to generate code from naturalistic language prompts. In this essay, we explore the extent to which "traditional" programming languages remain relevant for non-expert end-user programmers in a world with generative AI. We posit the "generative shift hypothesis": that generative AI will create qualitative and quantitative expansions in the traditional scope of end-user programming. We outline some reasons that traditional programming languages may still be relevant and useful for end-user programmers. We speculate whether each of these reasons might be fundamental and enduring, or whether they may disappear with further improvements and innovations in generative AI. Finally, we articulate a set of implications for end-user programming research, including the possibility of needing to revisit many well-established core concepts, such as Ko's learning barriers and Blackwell's attention investment model.
* Advait Sarkar. 2023. "Will Code Remain a Relevant User Interface for End-User Programming with Generative AI Models?" In Proceedings of the 2023 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward! '23)
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.
Exploring Perspectives on the Impact of Artificial Intelligence on the Creativity of Knowledge Work: Beyond Mechanised Plagiarism and Stochastic Parrots
Jul 20, 2023Artificial Intelligence (AI), and in particular generative models, are transformative tools for knowledge work. They problematise notions of creativity, originality, plagiarism, the attribution of credit, and copyright ownership. Critics of generative models emphasise the reliance on large amounts of training data, and view the output of these models as no more than randomised plagiarism, remix, or collage of the source data. On these grounds, many have argued for stronger regulations on the deployment, use, and attribution of the output of these models. However, these issues are not new or unique to artificial intelligence. In this position paper, using examples from literary criticism, the history of art, and copyright law, I show how creativity and originality resist definition as a notatable or information-theoretic property of an object, and instead can be seen as the property of a process, an author, or a viewer. Further alternative views hold that all creative work is essentially reuse (mostly without attribution), or that randomness itself can be creative. I suggest that creativity is ultimately defined by communities of creators and receivers, and the deemed sources of creativity in a workflow often depend on which parts of the workflow can be automated. Using examples from recent studies of AI in creative knowledge work, I suggest that AI shifts knowledge work from material production to critical integration. This position paper aims to begin a conversation around a more nuanced approach to the problems of creativity and credit assignment for generative models, one which more fully recognises the importance of the creative and curatorial voice of the users of these models and moves away from simpler notational or information-theoretic views.