 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLMbda Calculus: AI Agents, Conversations, and Information Flow
Feb 23, 2026A conversation with a large language model (LLM) is a sequence of prompts and responses, with each response generated from the preceding conversation. AI agents build such conversations automatically: given an initial human prompt, a planner loop interleaves LLM calls with tool invocations and code execution. This tight coupling creates a new and poorly understood attack surface. A malicious prompt injected into a conversation can compromise later reasoning, trigger dangerous tool calls, or distort final outputs. Despite the centrality of such systems, we currently lack a principled semantic foundation for reasoning about their behaviour and safety. We address this gap by introducing an untyped call-by-value lambda calculus enriched with dynamic information-flow control and a small number of primitives for constructing prompt-response conversations. Our language includes a primitive that invokes an LLM: it serializes a value, sends it to the model as a prompt, and parses the response as a new term. This calculus faithfully represents planner loops and their vulnerabilities, including the mechanisms by which prompt injection alters subsequent computation. The semantics explicitly captures conversations, and so supports reasoning about defenses such as quarantined sub-conversations, isolation of generated code, and information-flow restrictions on what may influence an LLM call. A termination-insensitive noninterference theorem establishes integrity and confidentiality guarantees, demonstrating that a formal calculus can provide rigorous foundations for safe agentic programming.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024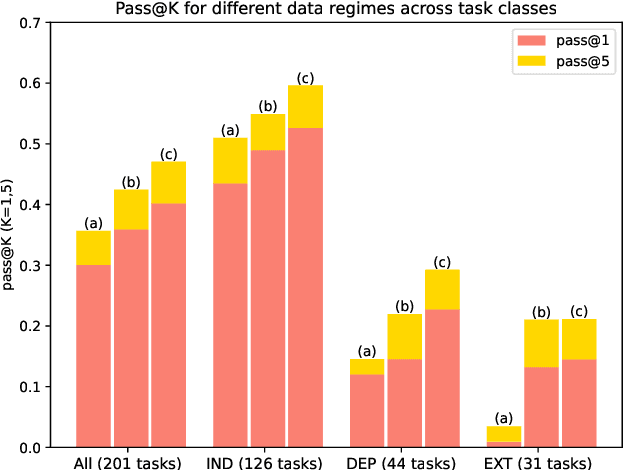
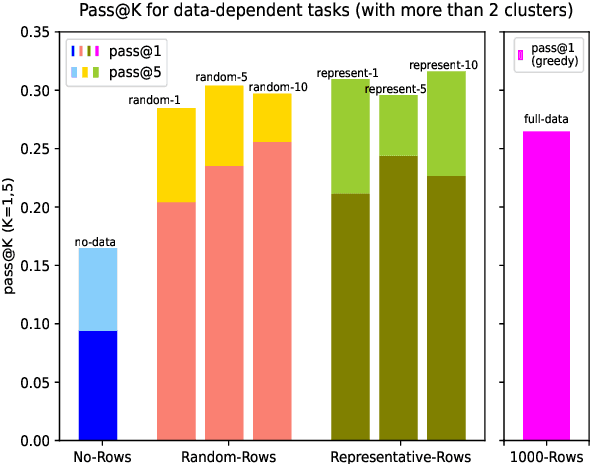
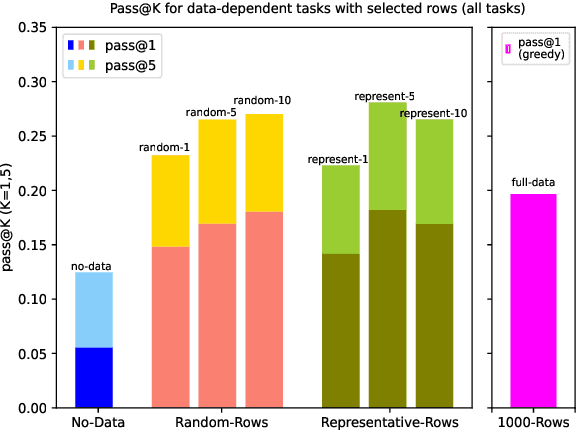
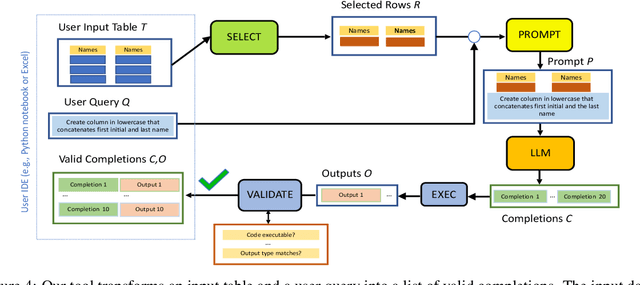
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.
What is it like to program with artificial intelligence?
Aug 12, 2022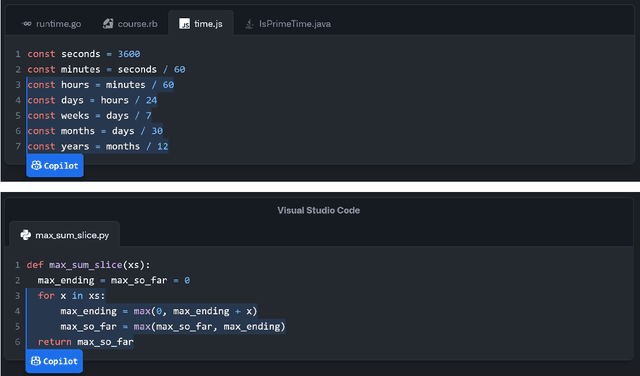
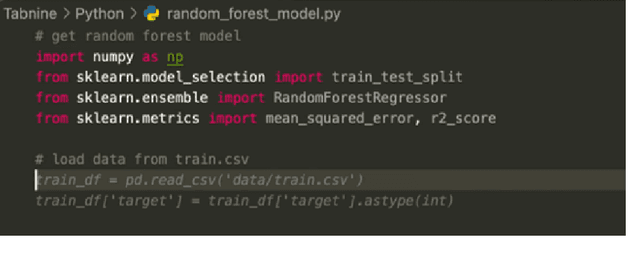
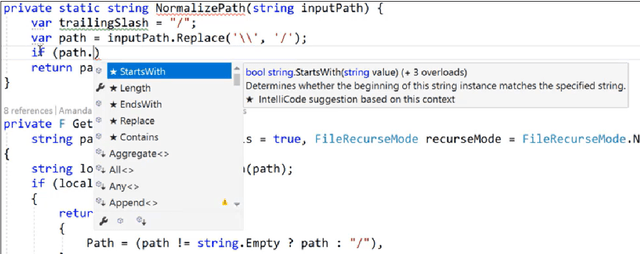
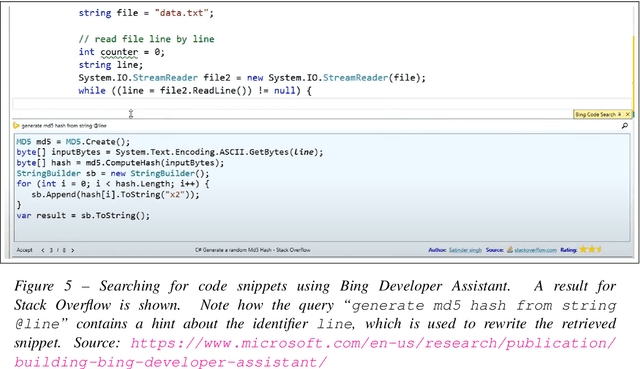
Large language models, such as OpenAI's codex and Deepmind's AlphaCode, can generate code to solve a variety of problems expressed in natural language. This technology has already been commercialised in at least one widely-used programming editor extension: GitHub Copilot. In this paper, we explore how programming with large language models (LLM-assisted programming) is similar to, and differs from, prior conceptualisations of programmer assistance. We draw upon publicly available experience reports of LLM-assisted programming, as well as prior usability and design studies. We find that while LLM-assisted programming shares some properties of compilation, pair programming, and programming via search and reuse, there are fundamental differences both in the technical possibilities as well as the practical experience. Thus, LLM-assisted programming ought to be viewed as a new way of programming with its own distinct properties and challenges. Finally, we draw upon observations from a user study in which non-expert end user programmers use LLM-assisted tools for solving data tasks in spreadsheets. We discuss the issues that might arise, and open research challenges, in applying large language models to end-user programming, particularly with users who have little or no programming expertise.
Conditional independence by typing
Oct 22, 2020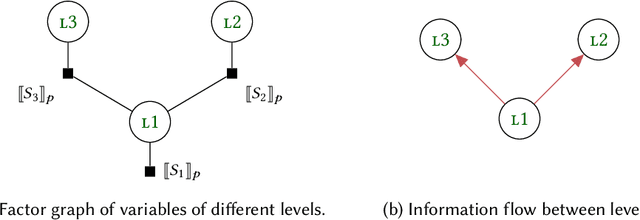
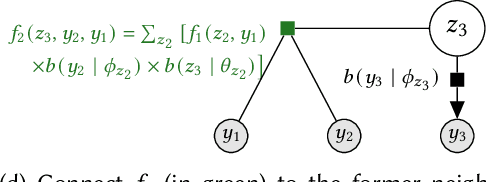
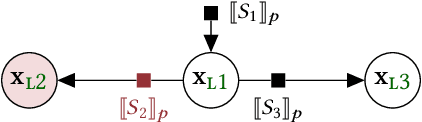
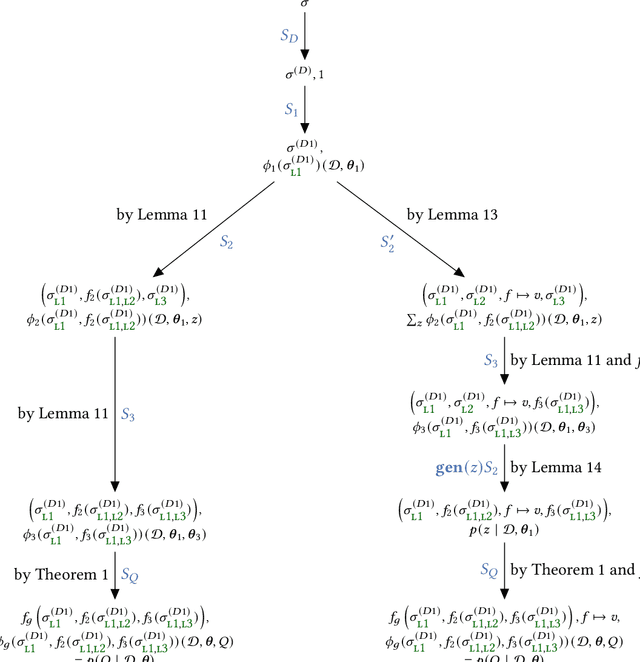
A central goal of probabilistic programming languages (PPLs) is to separate modelling from inference. However, this goal is hard to achieve in practice. Users are often forced to re-write their models in order to improve efficiency of inference or meet restrictions imposed by the PPL. Conditional independence (CI) relationships among parameters are a crucial aspect of probabilistic models that captures a qualitative summary of the specified model and can facilitate more efficient inference. We present an information flow type system for probabilistic programming that captures conditional independence (CI) relationships, and show that, for a well-typed program in our system, the distribution it implements is guaranteed to have certain CI-relationships. Further, by using type inference, we can statically \emph{deduce} which CI-properties are present in a specified model. As a practical application, we consider the problem of how to perform inference on models with mixed discrete and continuous parameters. Inference on such models is challenging in many existing PPLs, but can be improved through a workaround, where the discrete parameters are used \textit{implicitly}, at the expense of manual model re-writing. We present a source-to-source semantics-preserving transformation, which uses our CI-type system to automate this workaround by eliminating the discrete parameters from a probabilistic program. The resulting program can be seen as a hybrid inference algorithm on the original program, where continuous parameters can be drawn using efficient gradient-based inference methods, while the discrete parameters are drawn using variable elimination. We implement our CI-type system and its example application in SlicStan: a compositional variant of Stan.
OptTyper: Probabilistic Type Inference by Optimising Logical and Natural Constraints
Apr 01, 2020

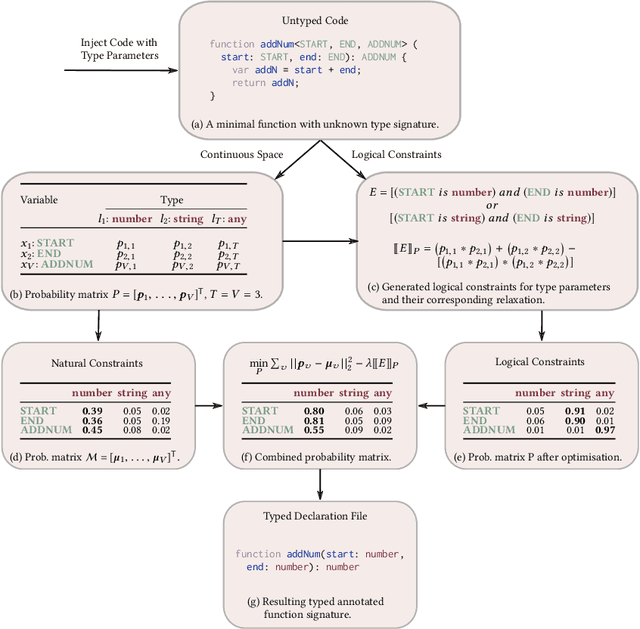

We present a new approach to the type inference problem for dynamic languages. Our goal is to combine logical constraints, that is, deterministic information from a type system, with natural constraints, uncertain information about types from sources like identifier names. To this end, we introduce a framework for probabilistic type inference that combines logic and learning: logical constraints on the types are extracted from the program, and deep learning is applied to predict types from surface-level code properties that are statistically associated, such as variable names. The main insight of our method is to constrain the predictions from the learning procedure to respect the logical constraints, which we achieve by relaxing the logical inference problem of type prediction into a continuous optimisation problem. To evaluate the idea, we built a tool called OptTyper to predict a TypeScript declaration file for a JavaScript library. OptTyper combines a continuous interpretation of logical constraints derived by a simple program transformation and static analysis of the JavaScript code, with natural constraints obtained from a deep learning model, which learns naming conventions for types from a large codebase. We evaluate OptTyper on a data set of 5,800 open-source JavaScript projects that have type annotations in the well-known DefinitelyTyped repository. We find that combining logical and natural constraints yields a large improvement in performance over either kind of information individually, and produces 50% fewer incorrect type predictions than previous approaches.
Probabilistic Programming with Densities in SlicStan: Efficient, Flexible and Deterministic
Nov 02, 2018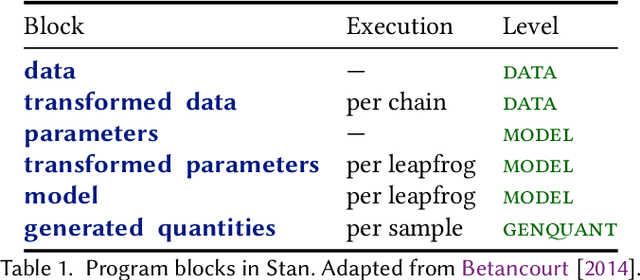
Stan is a probabilistic programming language that has been increasingly used for real-world scalable projects. However, to make practical inference possible, the language sacrifices some of its usability by adopting a block syntax, which lacks compositionality and flexible user-defined functions. Moreover, the semantics of the language has been mainly given in terms of intuition about implementation, and has not been formalised. This paper provides a formal treatment of the Stan language, and introduces the probabilistic programming language SlicStan --- a compositional, self-optimising version of Stan. Our main contributions are: (1) the formalisation of a core subset of Stan through an operational density-based semantics; (2) the design and semantics of the Stan-like language SlicStan, which facilities better code reuse and abstraction through its compositional syntax, more flexible functions, and information-flow type system; and (3) a formal, semantic-preserving procedure for translating SlicStan to Stan.
Deriving Probability Density Functions from Probabilistic Functional Programs
Jun 29, 2017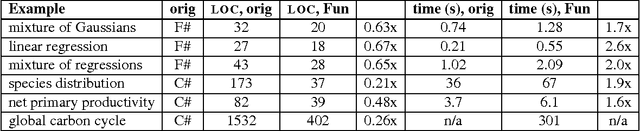
The probability density function of a probability distribution is a fundamental concept in probability theory and a key ingredient in various widely used machine learning methods. However, the necessary framework for compiling probabilistic functional programs to density functions has only recently been developed. In this work, we present a density compiler for a probabilistic language with failure and both discrete and continuous distributions, and provide a proof of its soundness. The compiler greatly reduces the development effort of domain experts, which we demonstrate by solving inference problems from various scientific applications, such as modelling the global carbon cycle, using a standard Markov chain Monte Carlo framework.