 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Feb 02, 2026AI agents often fail in ways that are difficult to localize because executions are probabilistic, long-horizon, multi-agent, and mediated by noisy tool outputs. We address this gap by manually annotating failed agent runs and release a novel benchmark of 115 failed trajectories spanning structured API workflows, incident management, and open-ended web/file tasks. Each trajectory is annotated with a critical failure step and a category from a grounded-theory derived, cross-domain failure taxonomy. To mitigate the human cost of failure attribution, we present AGENTRX, an automated domain-agnostic diagnostic framework that pinpoints the critical failure step in a failed agent trajectory. It synthesizes constraints, evaluates them step-by-step, and produces an auditable validation log of constraint violations with associated evidence; an LLM-based judge uses this log to localize the critical step and category. Our framework improves step localization and failure attribution over existing baselines across three domains.
PromptPex: Automatic Test Generation for Language Model Prompts
Mar 07, 2025Large language models (LLMs) are being used in many applications and prompts for these models are integrated into software applications as code-like artifacts. These prompts behave much like traditional software in that they take inputs, generate outputs, and perform some specific function. However, prompts differ from traditional code in many ways and require new approaches to ensure that they are robust. For example, unlike traditional software the output of a prompt depends on the AI model that interprets it. Also, while natural language prompts are easy to modify, the impact of updates is harder to predict. New approaches to testing, debugging, and modifying prompts with respect to the model running them are required. To address some of these issues, we developed PromptPex, an LLM-based tool to automatically generate and evaluate unit tests for a given prompt. PromptPex extracts input and output specifications from a prompt and uses them to generate diverse, targeted, and valid unit tests. These tests are instrumental in identifying regressions when a prompt is changed and also serve as a tool to understand how prompts are interpreted by different models. We use PromptPex to generate tests for eight benchmark prompts and evaluate the quality of the generated tests by seeing if they can cause each of four diverse models to produce invalid output. PromptPex consistently creates tests that result in more invalid model outputs than a carefully constructed baseline LLM-based test generator. Furthermore, by extracting concrete specifications from the input prompt, PromptPex allows prompt writers to clearly understand and test specific aspects of their prompts. The source code of PromptPex is available at https://github.com/microsoft/promptpex.
HYSYNTH: Context-Free LLM Approximation for Guiding Program Synthesis
May 24, 2024Many structured prediction and reasoning tasks can be framed as program synthesis problems, where the goal is to generate a program in a domain-specific language (DSL) that transforms input data into the desired output. Unfortunately, purely neural approaches, such as large language models (LLMs), often fail to produce fully correct programs in unfamiliar DSLs, while purely symbolic methods based on combinatorial search scale poorly to complex problems. Motivated by these limitations, we introduce a hybrid approach, where LLM completions for a given task are used to learn a task-specific, context-free surrogate model, which is then used to guide program synthesis. We evaluate this hybrid approach on three domains, and show that it outperforms both unguided search and direct sampling from LLMs, as well as existing program synthesizers.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024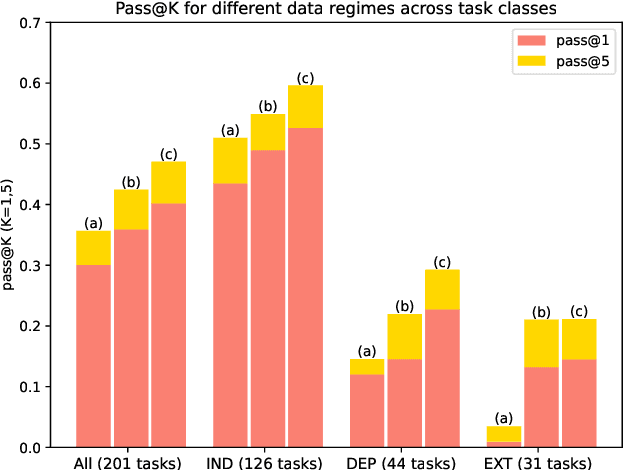
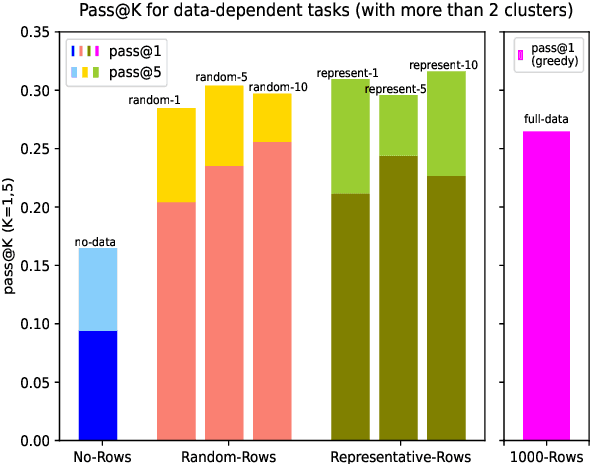
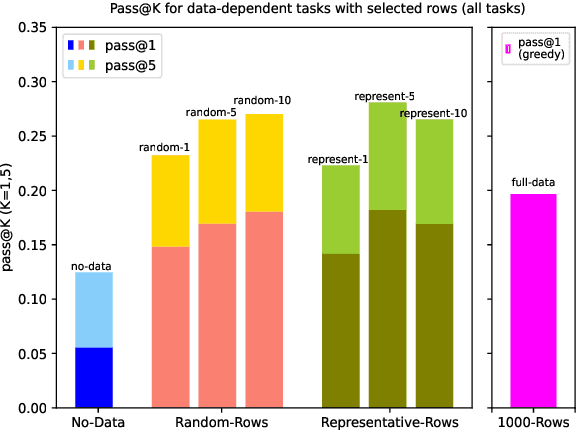
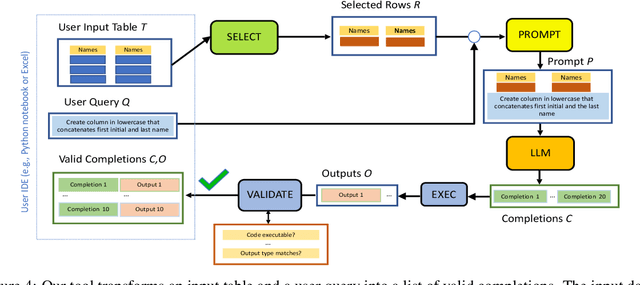
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.