 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Aug 16, 2024
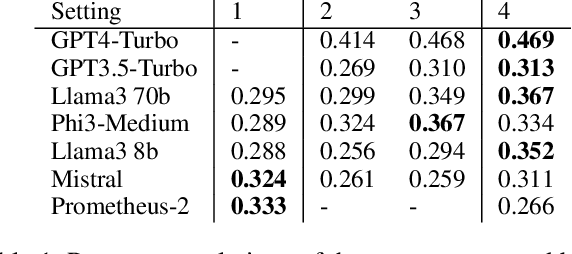
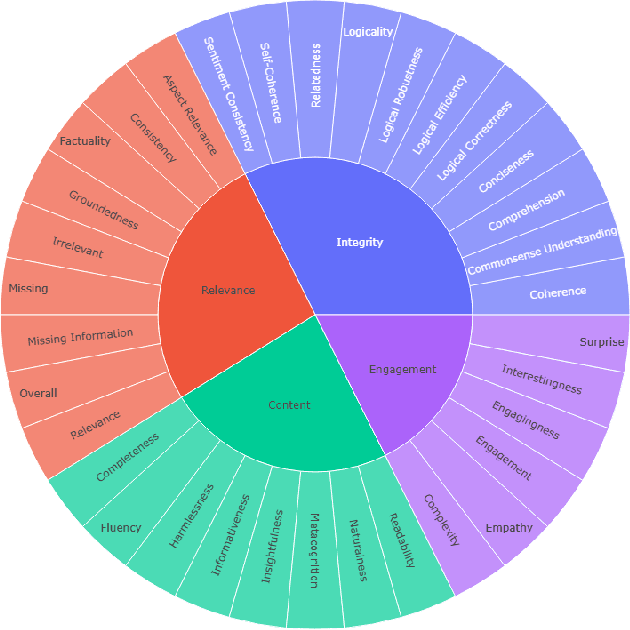
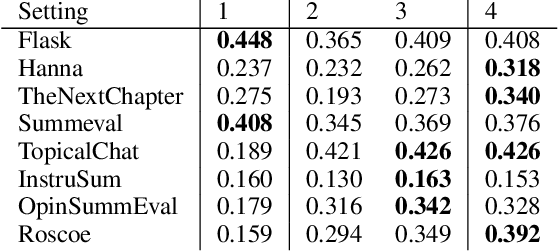
LLMs-as-a-judge is a recently popularized method which replaces human judgements in task evaluation (Zheng et al. 2024) with automatic evaluation using LLMs. Due to widespread use of RLHF (Reinforcement Learning from Human Feedback), state-of-the-art LLMs like GPT4 and Llama3 are expected to have strong alignment with human preferences when prompted for a quality judgement, such as the coherence of a text. While this seems beneficial, it is not clear whether the assessments by an LLM-as-a-judge constitute only an evaluation based on the instructions in the prompts, or reflect its preference for high-quality data similar to its fine-tune data. To investigate how much influence prompting the LLMs-as-a-judge has on the alignment of AI judgements to human judgements, we analyze prompts with increasing levels of instructions about the target quality of an evaluation, for several LLMs-as-a-judge. Further, we compare to a prompt-free method using model perplexity as a quality measure instead. We aggregate a taxonomy of quality criteria commonly used across state-of-the-art evaluations with LLMs and provide this as a rigorous benchmark of models as judges. Overall, we show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.
An Empirical Study of Validating Synthetic Data for Formula Generation
Jul 15, 2024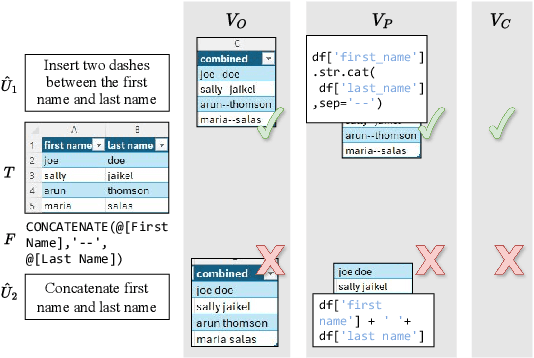
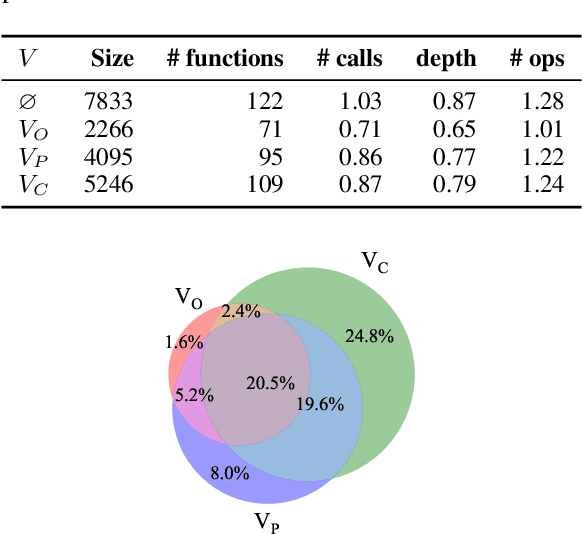
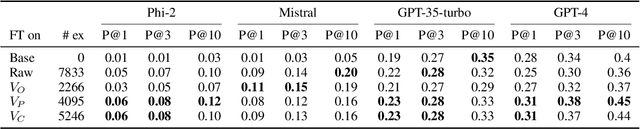
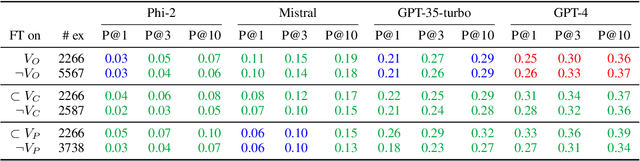
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024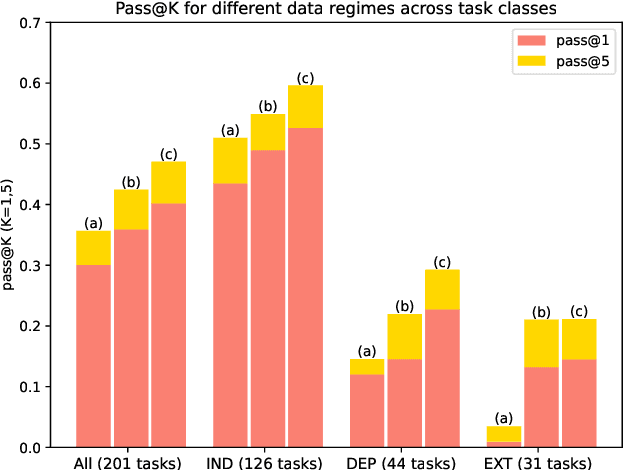
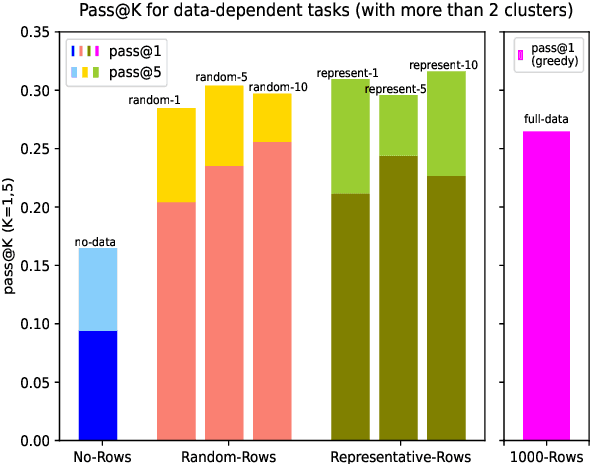
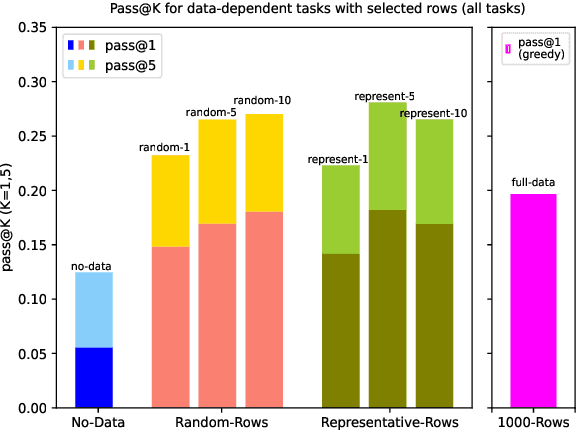
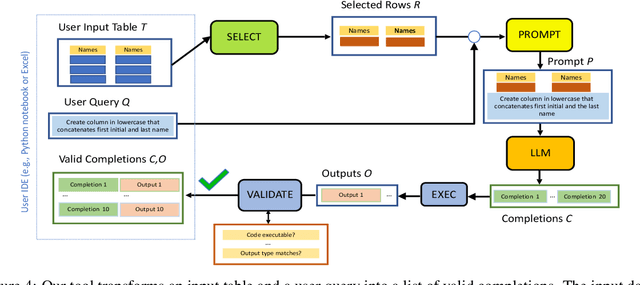
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Assessing GPT4-V on Structured Reasoning Tasks
Dec 13, 2023Multi-modality promises to unlock further uses for large language models. Recently, the state-of-the-art language model GPT-4 was enhanced with vision capabilities. We carry out a prompting evaluation of GPT-4V and five other baselines on structured reasoning tasks, such as mathematical reasoning, visual data analysis, and code generation. We show that visual Chain-of-Thought, an extension of Chain-of-Thought to multi-modal LLMs, yields significant improvements over the vanilla model. We also present a categorized analysis of scenarios where these models perform well and where they struggle, highlighting challenges associated with coherent multimodal reasoning.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023
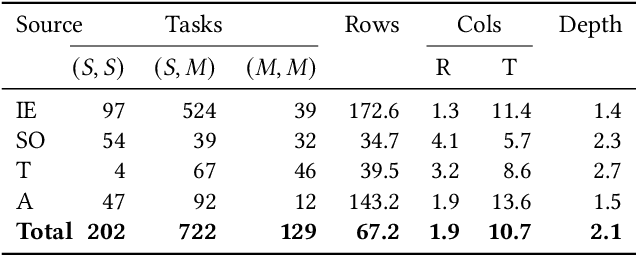

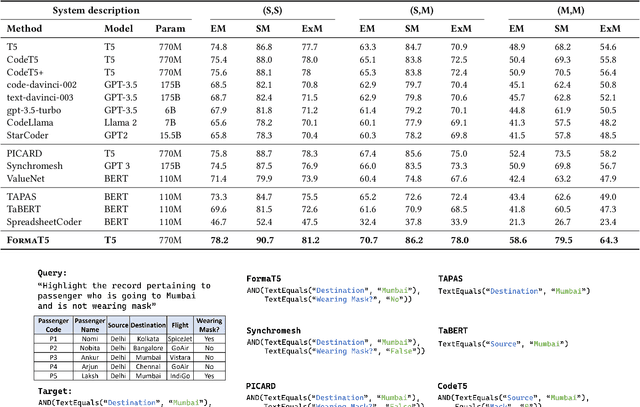
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.
CodeFusion: A Pre-trained Diffusion Model for Code Generation
Nov 01, 2023

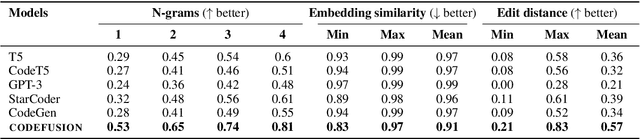

Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do not easily allow reconsidering earlier tokens generated. We introduce CodeFusion, a pre-trained diffusion code generation model that addresses this limitation by iteratively denoising a complete program conditioned on the encoded natural language. We evaluate CodeFusion on the task of natural language to code generation for Bash, Python, and Microsoft Excel conditional formatting (CF) rules. Experiments show that CodeFusion (75M parameters) performs on par with state-of-the-art auto-regressive systems (350M-175B parameters) in top-1 accuracy and outperforms them in top-3 and top-5 accuracy due to its better balance in diversity versus quality.
TST$^\mathrm{R}$: Target Similarity Tuning Meets the Real World
Oct 28, 2023Target similarity tuning (TST) is a method of selecting relevant examples in natural language (NL) to code generation through large language models (LLMs) to improve performance. Its goal is to adapt a sentence embedding model to have the similarity between two NL inputs match the similarity between their associated code outputs. In this paper, we propose different methods to apply and improve TST in the real world. First, we replace the sentence transformer with embeddings from a larger model, which reduces sensitivity to the language distribution and thus provides more flexibility in synthetic generation of examples, and we train a tiny model that transforms these embeddings to a space where embedding similarity matches code similarity, which allows the model to remain a black box and only requires a few matrix multiplications at inference time. Second, we show how to efficiently select a smaller number of training examples to train the TST model. Third, we introduce a ranking-based evaluation for TST that does not require end-to-end code generation experiments, which can be expensive to perform.
Tabular Representation, Noisy Operators, and Impacts on Table Structure Understanding Tasks in LLMs
Oct 16, 2023Large language models (LLMs) are increasingly applied for tabular tasks using in-context learning. The prompt representation for a table may play a role in the LLMs ability to process the table. Inspired by prior work, we generate a collection of self-supervised structural tasks (e.g. navigate to a cell and row; transpose the table) and evaluate the performance differences when using 8 formats. In contrast to past work, we introduce 8 noise operations inspired by real-world messy data and adversarial inputs, and show that such operations can impact LLM performance across formats for different structural understanding tasks.
DataVinci: Learning Syntactic and Semantic String Repairs
Aug 21, 2023



String data is common in real-world datasets: 67.6% of values in a sample of 1.8 million real Excel spreadsheets from the web were represented as text. Systems that successfully clean such string data can have a significant impact on real users. While prior work has explored errors in string data, proposed approaches have often been limited to error detection or require that the user provide annotations, examples, or constraints to fix the errors. Furthermore, these systems have focused independently on syntactic errors or semantic errors in strings, but ignore that strings often contain both syntactic and semantic substrings. We introduce DataVinci, a fully unsupervised string data error detection and repair system. DataVinci learns regular-expression-based patterns that cover a majority of values in a column and reports values that do not satisfy such patterns as data errors. DataVinci can automatically derive edits to the data error based on the majority patterns and constraints learned over other columns without the need for further user interaction. To handle strings with both syntactic and semantic substrings, DataVinci uses an LLM to abstract (and re-concretize) portions of strings that are semantic prior to learning majority patterns and deriving edits. Because not all data can result in majority patterns, DataVinci leverages execution information from an existing program (which reads the target data) to identify and correct data repairs that would not otherwise be identified. DataVinci outperforms 7 baselines on both error detection and repair when evaluated on 4 existing and new benchmarks.