 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025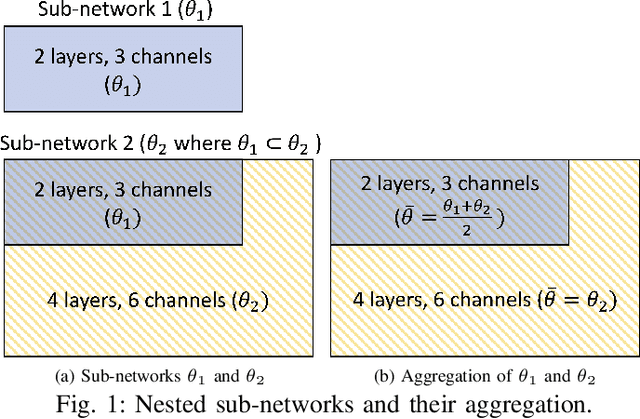
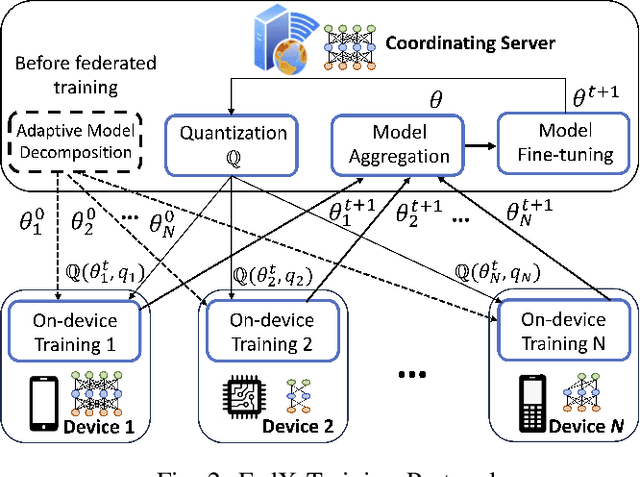
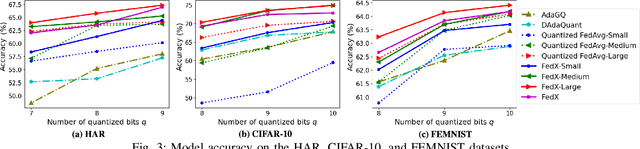
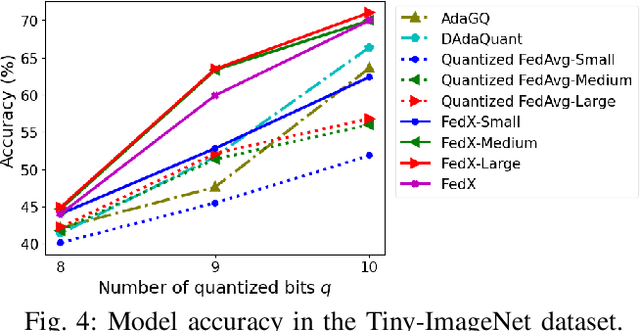
Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
Federated Joint Learning of Robot Networks in Stroke Rehabilitation
Mar 08, 2024



Advanced by rich perception and precise execution, robots possess immense potential to provide professional and customized rehabilitation exercises for patients with mobility impairments caused by strokes. Autonomous robotic rehabilitation significantly reduces human workloads in the long and tedious rehabilitation process. However, training a rehabilitation robot is challenging due to the data scarcity issue. This challenge arises from privacy concerns (e.g., the risk of leaking private disease and identity information of patients) during clinical data access and usage. Data from various patients and hospitals cannot be shared for adequate robot training, further compromising rehabilitation safety and limiting implementation scopes. To address this challenge, this work developed a novel federated joint learning (FJL) method to jointly train robots across hospitals. FJL also adopted a long short-term memory network (LSTM)-Transformer learning mechanism to effectively explore the complex tempo-spatial relations among patient mobility conditions and robotic rehabilitation motions. To validate FJL's effectiveness in training a robot network, a clinic-simulation combined experiment was designed. Real rehabilitation exercise data from 200 patients with stroke diseases (upper limb hemiplegia, Parkinson's syndrome, and back pain syndrome) were adopted. Inversely driven by clinical data, 300,000 robotic rehabilitation guidances were simulated. FJL proved to be effective in joint rehabilitation learning, performing 20% - 30% better than baseline methods.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
DeepFace-EMD: Re-ranking Using Patch-wise Earth Mover's Distance Improves Out-Of-Distribution Face Identification
Dec 07, 2021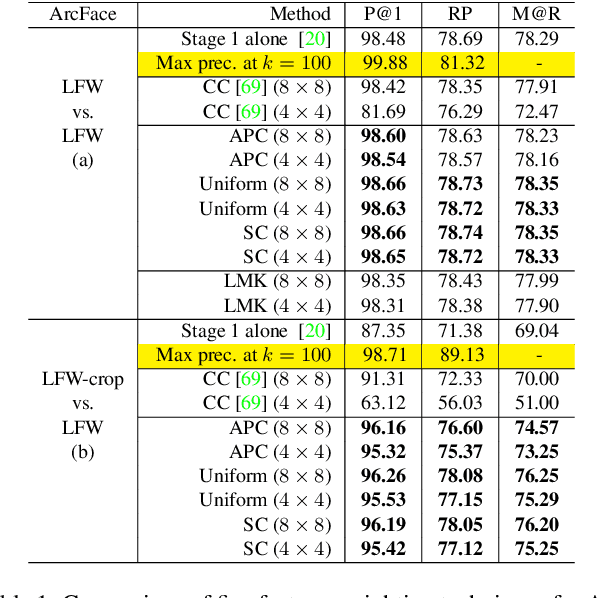

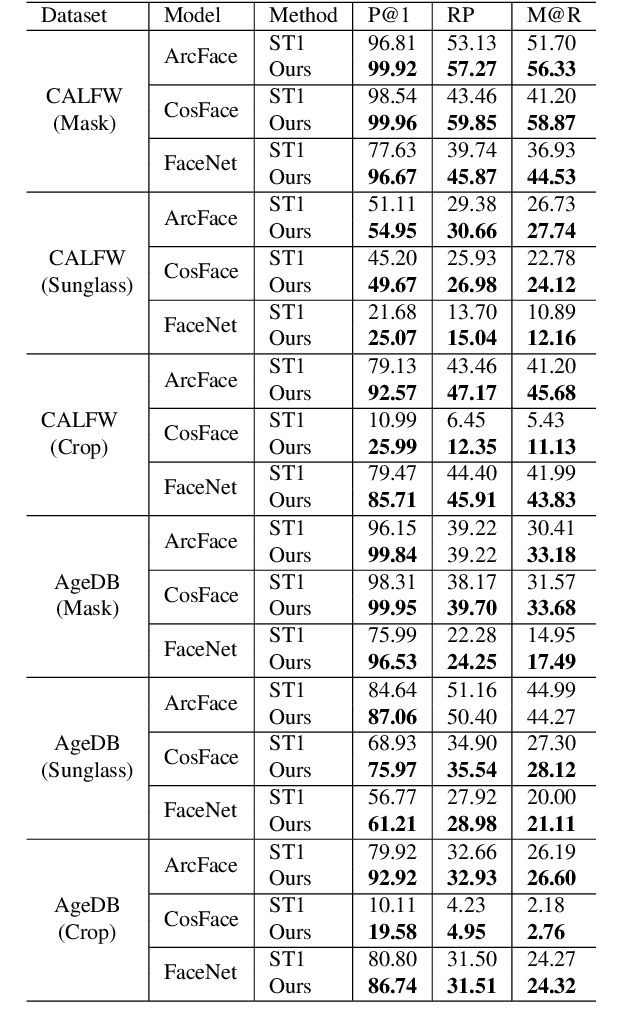

Face identification (FI) is ubiquitous and drives many high-stake decisions made by law enforcement. State-of-the-art FI approaches compare two images by taking the cosine similarity between their image embeddings. Yet, such an approach suffers from poor out-of-distribution (OOD) generalization to new types of images (e.g., when a query face is masked, cropped, or rotated) not included in the training set or the gallery. Here, we propose a re-ranking approach that compares two faces using the Earth Mover's Distance on the deep, spatial features of image patches. Our extra comparison stage explicitly examines image similarity at a fine-grained level (e.g., eyes to eyes) and is more robust to OOD perturbations and occlusions than traditional FI. Interestingly, without finetuning feature extractors, our method consistently improves the accuracy on all tested OOD queries: masked, cropped, rotated, and adversarial while obtaining similar results on in-distribution images.
Binarizing MobileNet via Evolution-based Searching
May 15, 2020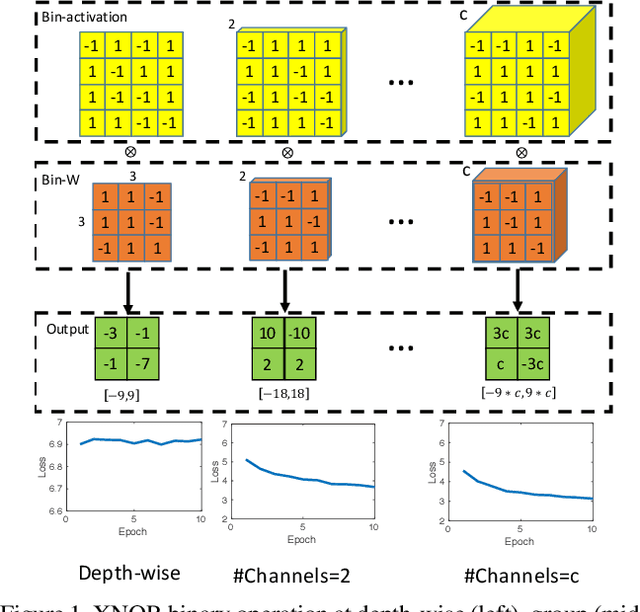
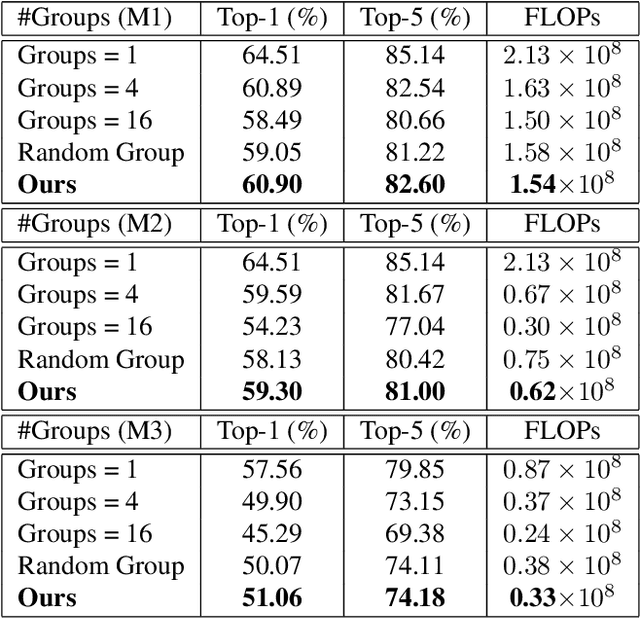
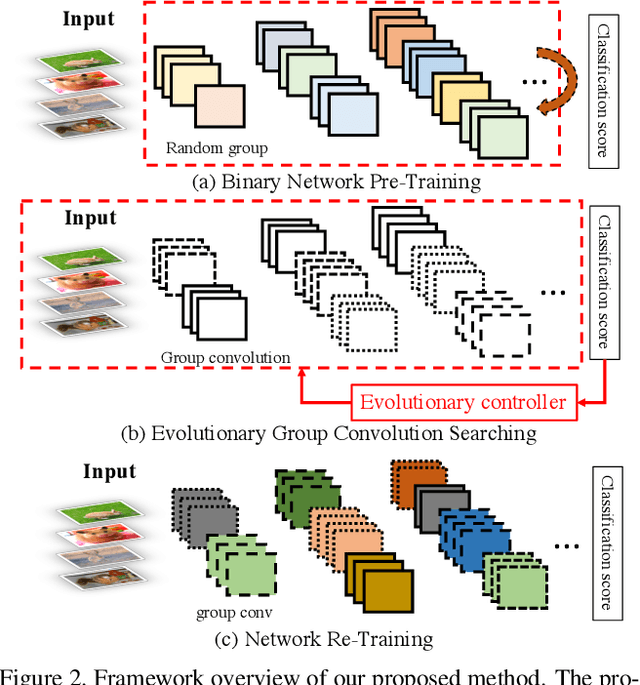
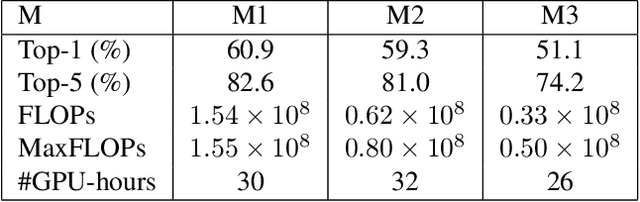
Binary Neural Networks (BNNs), known to be one among the effectively compact network architectures, have achieved great outcomes in the visual tasks. Designing efficient binary architectures is not trivial due to the binary nature of the network. In this paper, we propose a use of evolutionary search to facilitate the construction and training scheme when binarizing MobileNet, a compact network with separable depth-wise convolution. Inspired by one-shot architecture search frameworks, we manipulate the idea of group convolution to design efficient 1-Bit Convolutional Neural Networks (CNNs), assuming an approximately optimal trade-off between computational cost and model accuracy. Our objective is to come up with a tiny yet efficient binary neural architecture by exploring the best candidates of the group convolution while optimizing the model performance in terms of complexity and latency. The approach is threefold. First, we train strong baseline binary networks with a wide range of random group combinations at each convolutional layer. This set-up gives the binary neural networks a capability of preserving essential information through layers. Second, to find a good set of hyperparameters for group convolutions we make use of the evolutionary search which leverages the exploration of efficient 1-bit models. Lastly, these binary models are trained from scratch in a usual manner to achieve the final binary model. Various experiments on ImageNet are conducted to show that following our construction guideline, the final model achieves 60.09% Top-1 accuracy and outperforms the state-of-the-art CI-BCNN with the same computational cost.
MoBiNet: A Mobile Binary Network for Image Classification
Jul 31, 2019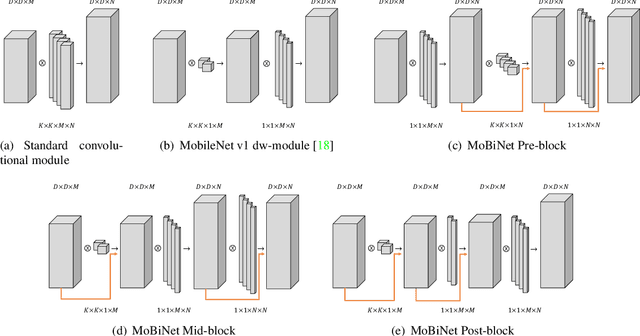

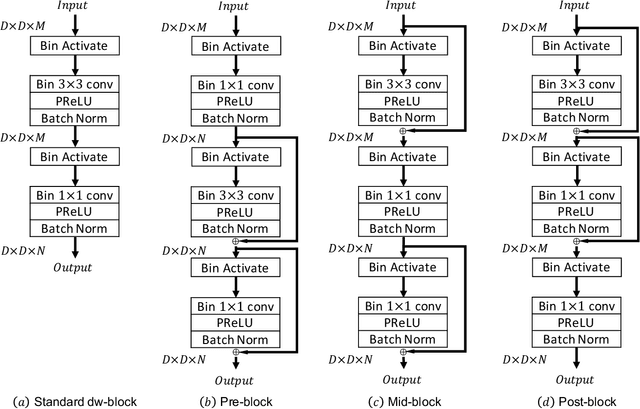
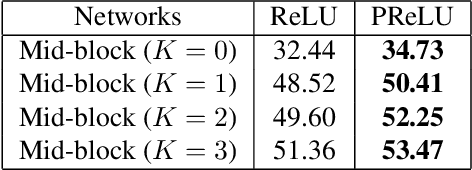
MobileNet and Binary Neural Networks are two among the most widely used techniques to construct deep learning models for performing a variety of tasks on mobile and embedded platforms.In this paper, we present a simple yet efficient scheme to exploit MobileNet binarization at activation function and model weights. However, training a binary network from scratch with separable depth-wise and point-wise convolutions in case of MobileNet is not trivial and prone to divergence. To tackle this training issue, we propose a novel neural network architecture, namely MoBiNet - Mobile Binary Network in which skip connections are manipulated to prevent information loss and vanishing gradient, thus facilitate the training process. More importantly, while existing binary neural networks often make use of cumbersome backbones such as Alex-Net, ResNet, VGG-16 with float-type pre-trained weights initialization, our MoBiNet focuses on binarizing the already-compressed neural networks like MobileNet without the need of a pre-trained model to start with. Therefore, our proposal results in an effectively small model while keeping the accuracy comparable to existing ones. Experiments on ImageNet dataset show the potential of the MoBiNet as it achieves 54.40% top-1 accuracy and dramatically reduces the computational cost with binary operators.