 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Structure-aware Language Models: Targeted Software Testing beyond Textual Semantics
Apr 20, 2026Recent advances in large language models for test case generation have improved branch coverage via prompt-engineered mutations. However, they still lack principled mechanisms for steering models toward specific high-risk execution branches, limiting their effectiveness for discovering subtle bugs and security vulnerabilities. We propose GLMTest, the first program structure-aware LLM framework for targeted test case generation that seamlessly integrates code property graphs and code semantics using a graph neural network and a language model to condition test case generation on execution branches. This structured conditioning enables controllable and branch-targeted test case generation, thereby potentially enhancing bug and security risk discovery. Experiments on real-world projects show that GLMTest built on a Qwen2.5-Coder-7B-Instruct model improves branch accuracy from 27.4% to 50.2% on TestGenEval benchmark compared with state-of-the-art LLMs, i.e., Claude-Sonnet-4.5 and GPT-4o-mini.
AdFL: In-Browser Federated Learning for Online Advertisement
Feb 06, 2026Since most countries are coming up with online privacy regulations, such as GDPR in the EU, online publishers need to find a balance between revenue from targeted advertisement and user privacy. One way to be able to still show targeted ads, based on user personal and behavioral information, is to employ Federated Learning (FL), which performs distributed learning across users without sharing user raw data with other stakeholders in the publishing ecosystem. This paper presents AdFL, an FL framework that works in the browsers to learn user ad preferences. These preferences are aggregated in a global FL model, which is then used in the browsers to show more relevant ads to users. AdFL can work with any model that uses features available in the browser such as ad viewability, ad click-through, user dwell time on pages, and page content. The AdFL server runs at the publisher and coordinates the learning process for the users who browse pages on the publisher's website. The AdFL prototype does not require the client to install any software, as it is built utilizing standard APIs available on most modern browsers. We built a proof-of-concept model for ad viewability prediction that runs on top of AdFL. We tested AdFL and the model with two non-overlapping datasets from a website with 40K visitors per day. The experiments demonstrate AdFL's feasibility to capture the training information in the browser in a few milliseconds, show that the ad viewability prediction achieves up to 92.59% AUC, and indicate that utilizing differential privacy (DP) to safeguard local model parameters yields adequate performance, with only modest declines in comparison to the non-DP variant.
NOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
Using Salient Object Detection to Identify Manipulative Cookie Banners that Circumvent GDPR
Oct 30, 2025The main goal of this paper is to study how often cookie banners that comply with the General Data Protection Regulation (GDPR) contain aesthetic manipulation, a design tactic to draw users' attention to the button that permits personal data sharing. As a byproduct of this goal, we also evaluate how frequently the banners comply with GDPR and the recommendations of national data protection authorities regarding banner designs. We visited 2,579 websites and identified the type of cookie banner implemented. Although 45% of the relevant websites have fully compliant banners, we found aesthetic manipulation on 38% of the compliant banners. Unlike prior studies of aesthetic manipulation, we use a computer vision model for salient object detection to measure how salient (i.e., attention-drawing) each banner element is. This enables the discovery of new types of aesthetic manipulation (e.g., button placement), and leads us to conclude that aesthetic manipulation is more common than previously reported (38% vs 27% of banners). To study the effects of user and/or website location on cookie banner design, we include websites within the European Union (EU), where privacy regulation enforcement is more stringent, and websites outside the EU. We visited websites from IP addresses in the EU and from IP addresses in the United States (US). We find that 13.9% of EU websites change their banner design when the user is from the US, and EU websites are roughly 48.3% more likely to use aesthetic manipulation than non-EU websites, highlighting their innovative responses to privacy regulation.
CryptGNN: Enabling Secure Inference for Graph Neural Networks
Sep 11, 2025We present CryptGNN, a secure and effective inference solution for third-party graph neural network (GNN) models in the cloud, which are accessed by clients as ML as a service (MLaaS). The main novelty of CryptGNN is its secure message passing and feature transformation layers using distributed secure multi-party computation (SMPC) techniques. CryptGNN protects the client's input data and graph structure from the cloud provider and the third-party model owner, and it protects the model parameters from the cloud provider and the clients. CryptGNN works with any number of SMPC parties, does not require a trusted server, and is provably secure even if P-1 out of P parties in the cloud collude. Theoretical analysis and empirical experiments demonstrate the security and efficiency of CryptGNN.
FedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025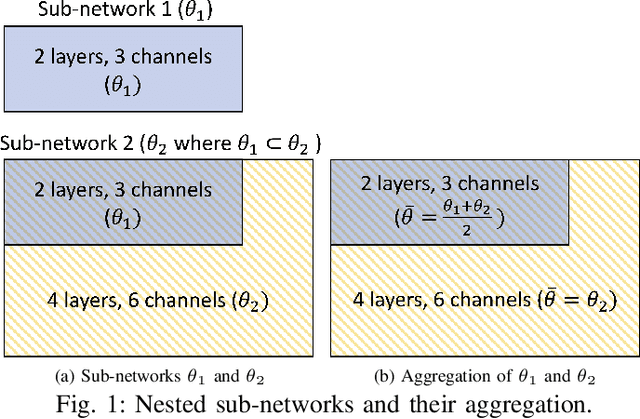
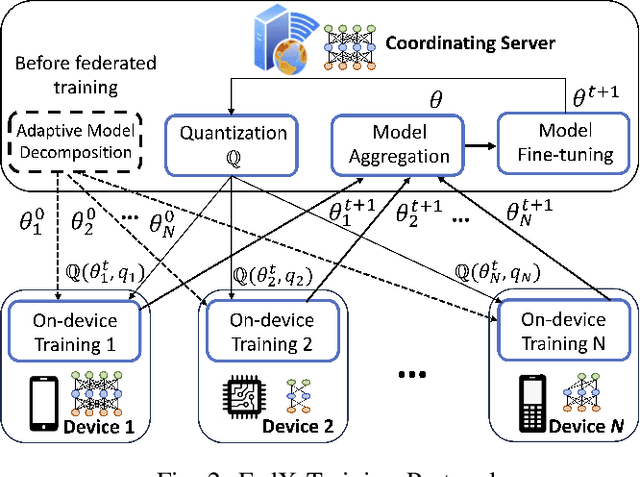
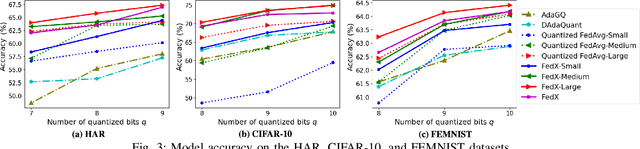
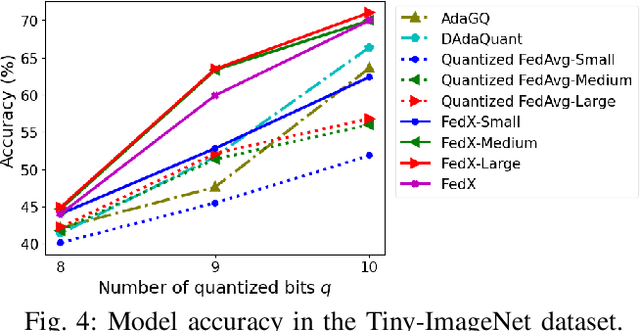
Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
Demo: SGCode: A Flexible Prompt-Optimizing System for Secure Generation of Code
Sep 11, 2024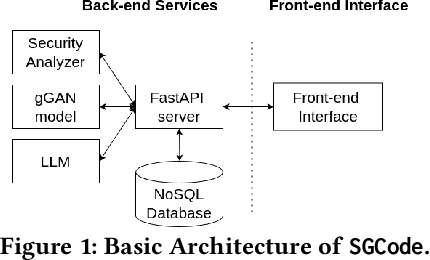
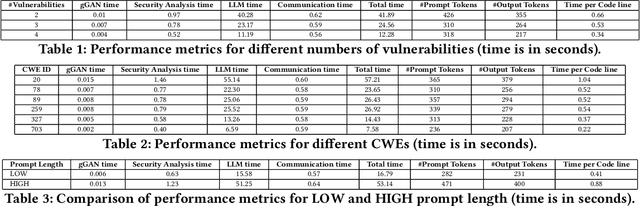
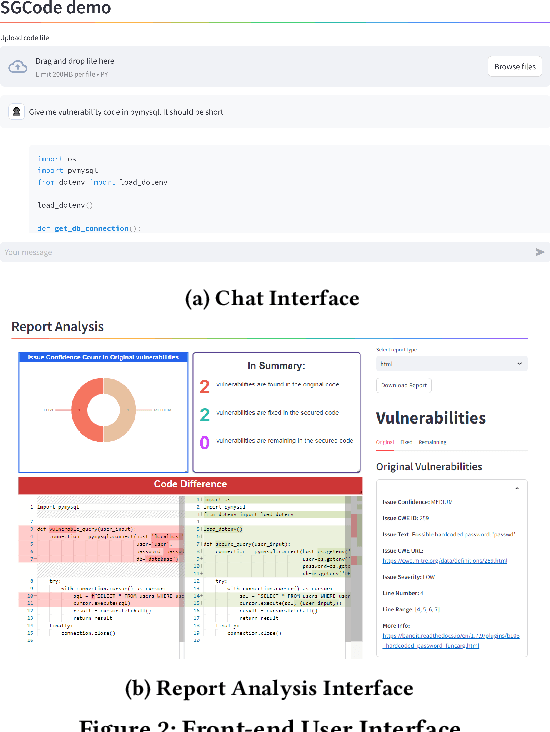
This paper introduces SGCode, a flexible prompt-optimizing system to generate secure code with large language models (LLMs). SGCode integrates recent prompt-optimization approaches with LLMs in a unified system accessible through front-end and back-end APIs, enabling users to 1) generate secure code, which is free of vulnerabilities, 2) review and share security analysis, and 3) easily switch from one prompt optimization approach to another, while providing insights on model and system performance. We populated SGCode on an AWS server with PromSec, an approach that optimizes prompts by combining an LLM and security tools with a lightweight generative adversarial graph neural network to detect and fix security vulnerabilities in the generated code. Extensive experiments show that SGCode is practical as a public tool to gain insights into the trade-offs between model utility, secure code generation, and system cost. SGCode has only a marginal cost compared with prompting LLMs. SGCode is available at: http://3.131.141.63:8501/.
Concept Matching: Clustering-based Federated Continual Learning
Nov 12, 2023Federated Continual Learning (FCL) has emerged as a promising paradigm that combines Federated Learning (FL) and Continual Learning (CL). To achieve good model accuracy, FCL needs to tackle catastrophic forgetting due to concept drift over time in CL, and to overcome the potential interference among clients in FL. We propose Concept Matching (CM), a clustering-based framework for FCL to address these challenges. The CM framework groups the client models into concept model clusters, and then builds different global models to capture different concepts in FL over time. In each round, the server sends the global concept models to the clients. To avoid catastrophic forgetting, each client selects the concept model best-matching the concept of the current data for further fine-tuning. To avoid interference among client models with different concepts, the server clusters the models representing the same concept, aggregates the model weights in each cluster, and updates the global concept model with the cluster model of the same concept. Since the server does not know the concepts captured by the aggregated cluster models, we propose a novel server concept matching algorithm that effectively updates a global concept model with a matching cluster model. The CM framework provides flexibility to use different clustering, aggregation, and concept matching algorithms. The evaluation demonstrates that CM outperforms state-of-the-art systems and scales well with the number of clients and the model size.
Zone-based Federated Learning for Mobile Sensing Data
Mar 10, 2023

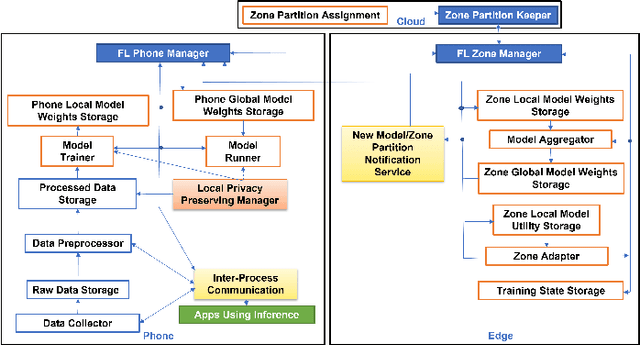

Mobile apps, such as mHealth and wellness applications, can benefit from deep learning (DL) models trained with mobile sensing data collected by smart phones or wearable devices. However, currently there is no mobile sensing DL system that simultaneously achieves good model accuracy while adapting to user mobility behavior, scales well as the number of users increases, and protects user data privacy. We propose Zone-based Federated Learning (ZoneFL) to address these requirements. ZoneFL divides the physical space into geographical zones mapped to a mobile-edge-cloud system architecture for good model accuracy and scalability. Each zone has a federated training model, called a zone model, which adapts well to data and behaviors of users in that zone. Benefiting from the FL design, the user data privacy is protected during the ZoneFL training. We propose two novel zone-based federated training algorithms to optimize zone models to user mobility behavior: Zone Merge and Split (ZMS) and Zone Gradient Diffusion (ZGD). ZMS optimizes zone models by adapting the zone geographical partitions through merging of neighboring zones or splitting of large zones into smaller ones. Different from ZMS, ZGD maintains fixed zones and optimizes a zone model by incorporating the gradients derived from neighboring zones' data. ZGD uses a self-attention mechanism to dynamically control the impact of one zone on its neighbors. Extensive analysis and experimental results demonstrate that ZoneFL significantly outperforms traditional FL in two models for heart rate prediction and human activity recognition. In addition, we developed a ZoneFL system using Android phones and AWS cloud. The system was used in a heart rate prediction field study with 63 users for 4 months, and we demonstrated the feasibility of ZoneFL in real-life.
Complement Sparsification: Low-Overhead Model Pruning for Federated Learning
Mar 10, 2023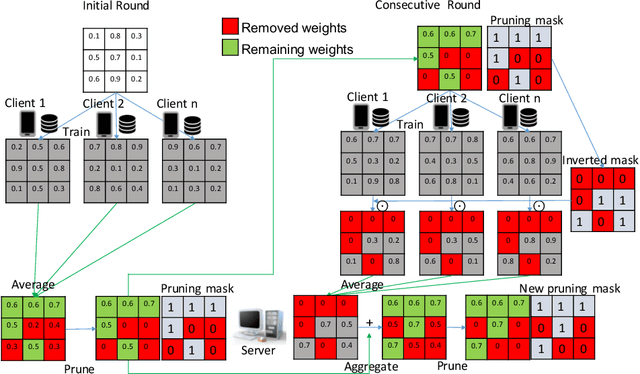

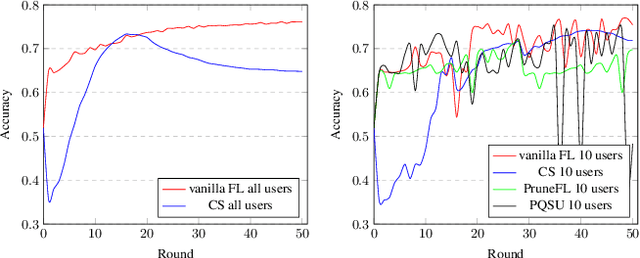

Federated Learning (FL) is a privacy-preserving distributed deep learning paradigm that involves substantial communication and computation effort, which is a problem for resource-constrained mobile and IoT devices. Model pruning/sparsification develops sparse models that could solve this problem, but existing sparsification solutions cannot satisfy at the same time the requirements for low bidirectional communication overhead between the server and the clients, low computation overhead at the clients, and good model accuracy, under the FL assumption that the server does not have access to raw data to fine-tune the pruned models. We propose Complement Sparsification (CS), a pruning mechanism that satisfies all these requirements through a complementary and collaborative pruning done at the server and the clients. At each round, CS creates a global sparse model that contains the weights that capture the general data distribution of all clients, while the clients create local sparse models with the weights pruned from the global model to capture the local trends. For improved model performance, these two types of complementary sparse models are aggregated into a dense model in each round, which is subsequently pruned in an iterative process. CS requires little computation overhead on the top of vanilla FL for both the server and the clients. We demonstrate that CS is an approximation of vanilla FL and, thus, its models perform well. We evaluate CS experimentally with two popular FL benchmark datasets. CS achieves substantial reduction in bidirectional communication, while achieving performance comparable with vanilla FL. In addition, CS outperforms baseline pruning mechanisms for FL.